当前位置:网站首页>Similar image detection method
Similar image detection method
2022-08-09 16:02:00 【Yehenara Hermione】
背景
以图搜图,It is often used in our daily life,For example, when shopping for a product,Want to compare prices,Often shopping in various placesappSee the price of the same product in the form of a search map;When you come across some unknown plant,You can also get the name of the plant by searching for pictures.Most of these functions are achieved by calculating the similarity of images.By calculating the similarity between the image to be searched and the image in the image database,And sort the similarity to recommend search results of similar images for users.同时,It can also be used to judge whether a trademark is infringed by detecting whether the pictures are similar,Whether the image work is plagiarized, etc.This article will introduce several commonly used similar image detection methods,Among them are hash-based algorithms,基于直方图,基于特征匹配,基于BOW+KmeansAnd the image similarity calculation method based on convolutional network.
技术实现

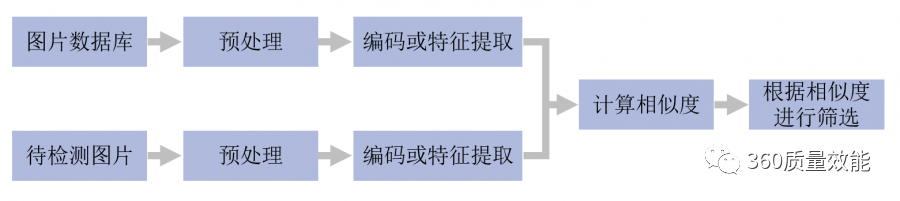
The detection process of similar images is simply to encode or extract features from each image in the image database(一般形式为特征向量),Form a digital database.对于待检测图片,Encoding or feature extraction is performed in the same way as in the image database,The distance between the code or the feature vector and the code or vector of the image in the database is then calculated,as the similarity between images,and sort the similarity,Display the images that are the most similar or meet the needs.

哈希算法
The hash algorithm generates one per image“指纹”(fingerprint)字符串,然后比较不同图像的指纹.结果越接近,就说明图像越相似.
There are three commonly used hash algorithms:
def aHash(img):
img = cv2.resize(img, (8, 8))
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
np_mean = np.mean(gray)
ahash_01 = (gray > np_mean) + 0
ahash_list = ahash_01.reshape(1, -1)[0].tolist()
ahash_str = ''.join([str(x) for x in ahash_list])
return ahash_str
def pHash(img):
img = cv2.resize(img, (32, 32))
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
dct = cv2.dct(np.float32(gray))
dct_roi = dct[0:8, 0:8]
avreage = np.mean(dct_roi)
phash_01 = (dct_roi > avreage) + 0
phash_list = phash_01.reshape(1, -1)[0].tolist()
phash_str = ''.join([str(x) for x in phash_list])
return phash_str
def dHash(img):
img = cv2.resize(img, (9, 8))
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
hash_str0 = []
for i in range(8):
hash_str0.append(gray[:, i] > gray[:, i + 1])
hash_str1 = np.array(hash_str0) + 0
hash_str2 = hash_str1.T
hash_str3 = hash_str2.reshape(1, -1)[0].tolist()
dhash_str = ''.join([str(x) for x in hash_str3])
return dhash_str
def hammingDist(hashstr1, hashstr2):
assert len(hashstr1) == len(hashstr1)
return sum([ch1 != ch2 for ch1, ch2 in zip(hashstr1, hashstr1)])
Single channel histogram and triple histogram
def calculate_single(img1, img2):
hist1 = cv2.calcHist([img1], [0], None, [256], [0.0, 255.0])
hist1 = cv2.normalize(hist1, hist1, 0, 1, cv2.NORM_MINMAX, -1)
hist2 = cv2.calcHist([img2], [0], None, [256], [0.0, 255.0])
hist2 = cv2.normalize(hist2, hist2, 0, 1, cv2.NORM_MINMAX, -1)
degree = 0
for i in range(len(hist1)):
if hist1[i] != hist2[i]:
degree = degree + (1 - abs(hist1[i] - hist2[i]) / max(hist1[i], hist2[i]))
else:
degree = degree + 1
degree = degree / len(hist1)
return degree
def classify_hist_of_three(img1, img2, size=(256, 256)):
image1 = cv2.resize(img1, size)
image2 = cv2.resize(img2, size)
sub_image1 = cv2.split(img1)
sub_image2 = cv2.split(img2)
sub_data = 0
for im1, im2 in zip(sub_img1, sub_img2):
sub_data += calculate_single(im1, im2)
sub_data = sub_data / 3
return sub_data
A method based on feature extraction and matching
def ORB_img_similarity(img1_path,img2_path):
orb = cv2.ORB_create()
img1 = cv2.imread(img1_path, cv2.IMREAD_GRAYSCALE)
img2 = cv2.imread(img2_path, cv2.IMREAD_GRAYSCALE)
kp1, des1 = orb.detectAndCompute(img1, None)
kp2, des2 = orb.detectAndCompute(img2, None)
bf = cv2.BFMatcher(cv2.NORM_HAMMING)
matches = bf.knnMatch(des1, trainDescriptors=des2, k=2)
matchNum = [m for (m, n) in matches if m.distance <0.8* n.distance]
similary = len(good) / len(matches)
return similary
def sift_similarity(img1_path, img2_path):
sift = cv2.xfeatures2d.SIFT_create()
FLANN_INDEX_KDTREE=0
indexParams = dict(algorithm=FLANN_INDEX_KDTREE, trees=5)
searchParams = dict(checks=50)
flann = cv2.FlannBasedMatcher(indexParams, searchParams)
sampleImage = cv2.imread(samplePath, 0)
kp1, des1 = sift.detectAndCompute(sampleImage, None)
kp2, des2 = sift.detectAndCompute(queryImage, None)
matches = flann.knnMatch(des1, des2, k=2)
matchNum = [m for (m, n) in matches if m.distance <0.8* n.distance]
similary = matchNum/len(matches)
return similarity
基于BOW+K-Meanssimilar image detection
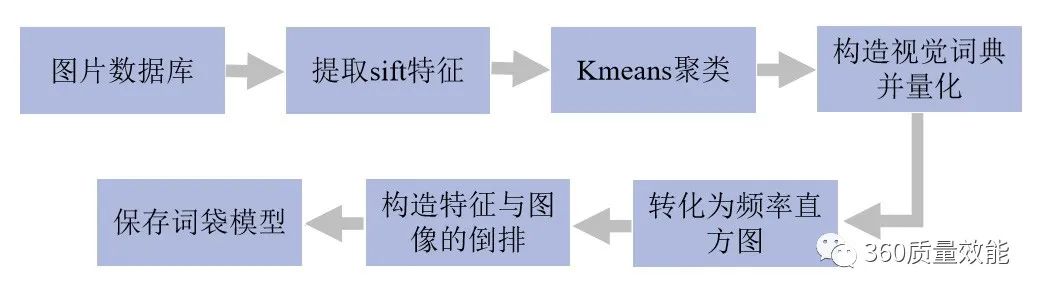
BOWModels are widely used in computer vision,compared to textBOW,Features of images are treated as words(word),The dictionary of sight words consists of all sight words in the picture set,The bag-of-words model is generated as shown below.首先,用siftThe algorithm generates feature points and descriptors for each image in the image library.再用k-MeansThe algorithm clusters the feature points in the image library,聚类中心有k个,Cluster centers are called visual words,Group these cluster centers together,形成一部字典.根据IDF原理,Count each sight wordTF-IDF权重来表示视觉单词对区分图像的重要程度.for each image in the image library,Count the number of times each word in the dictionary appears in its feature set,Denote each image as K 维数值向量(直方图).After getting the histogram vector for each image,构造特征到图像的倒排表,Quickly index images of relevant candidates through an inverted table.for the image to be detected,计算出sift特征,并根据TF-IDFconverted into feature vectors(频率直方图),The similarity judgment of the histogram vector is performed according to the index result.

des_list = []
filelist = os.listdir(dir)
trainNum = int(count / 3)
for i in range(len(filelist)):
filename = dir + '\\' + filelist[i]
img = cv2.imread(filename)
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
kp, des = sift_det.detectAndCompute(gray, None)
des_list.append((image_path, des))
descriptors = des_list[0][1]
for image_path, descriptor in des_list[1:]:
descriptors = np.vstack((descriptors, descriptor))
voc, variance = kmeans(descriptors, numWords, 1)
im_features = np.zeros((len(image_paths), numWords), "float32")
for i in range(len(image_paths)):
words, distance = vq(des_list[i][1], voc)
for w in words:
im_features[i][w] += 1
nbr_occurences = np.sum((im_features >0) * 1, axis = 0)
idf = np.array(np.log((1.0*len(image_paths)+1) / (1.0*nbr_occurences + 1)), 'float32')
im_features = im_features*idf
im_features = preprocessing.normalize(im_features, norm='l2')
joblib.dump((im_features, image_paths, idf, numWords, voc), "bow.pkl", compress=3)
Similar Image Detection Based on Convolutional Networks
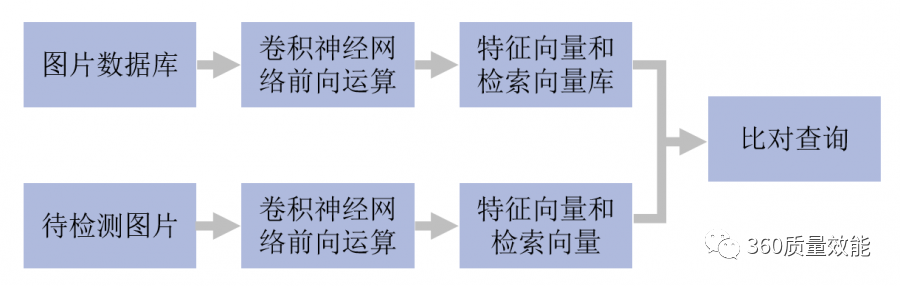
在ImageNetThe convolutional network structure in (vgg16)基础上,在第7层(4096个神经元)和outputAdd a fully connected layer between layers,并选用sigmoidThe activation function makes the output value in 0-1之间,设定阈值0.5Can be converted later01A binary vector is retrieved as a binary vector.这样,Do convolutional network forward operations on all images,得到第7层4096The dimensional feature vector sum represents the th of the image category buckets8层output.for the image to be detected,同样得到4096dimensional eigenvectors and128维01二值检索向量,Find the image corresponding to the binary search vector in the database,比对4096The distance between dimensional feature vectors,Reorder to get the final result.其流程如下:

database = 'dataset'
index = 'models/vgg_featureCNN.h5'
img_list = get_imlist(database)
features = []
names = []
model = VGGNet()
for i, img_path in enumerate(img_list):
norm_feat = model.vgg_extract_feat(img_path)
img_name = os.path.split(img_path)[1]
features.append(norm_feat)
names.append(img_name)
feats = np.array(features)
output = index
h5f = h5py.File(output, 'w')
h5f.create_dataset('dataset_features', data=feats)
h5f.create_dataset('dataset_names', data=np.string_(names))
h5f.close()
model = VGGNet()
queryVec = model.vgg_extract_feat(imgs)
scores = np.dot(queryVec, feats.T)
rank_ID = np.argsort(scores)[::-1]
rank_score = scores[rank_ID]
效果展示
The different methods are shown below for an icon,The effect of similar image detection in the same database:

It can be seen from the test results,for the above data,基于vgg16和siftFeature retrieval results will be more accurate and stable,The image retrieved based on the histogram is also similar to the image to be detected,而基于BOWThe results retrieved by the hash algorithm are unstable,基于orbThere is a big gap between the image retrieved by the feature and the image to be detected,效果很不理想.But that doesn't mean that a certain method is necessarily bad,but for specific data,There are also differences in the performance of the same method in different databases.在实践过程中,In order to ensure the stability of the detection effect,The method with better and more stable performance should be selected.
总结
There are many ways to detect similar images,But not every method is suitable for your application scenario,The performance of various methods on different data also has great differences.因此,It can be comprehensively considered according to the characteristics of its own data and the characteristics of different methods.Different methods can also be combined according to requirements,Further improve the accuracy and stability of similar image detection.If the detection of similar images is to analyze whether the trademark is infringed or whether the work is plagiarized, etc,The threshold of similarity can be set appropriately,进行筛选.
边栏推荐
猜你喜欢
Zero Time Technology | Nomad cross-chain bridge theft of 180 million US dollars incident analysis

【OpenGL】四、OpenGL入门总结:LearnOpenGL CN教程中关于欧拉角公式推导

Hudi Spark-Shell 实战

基于FPGA的FIR滤波器的实现(2)—采用kaiserord & fir2 & firpm函数设计

基于微信云开发的幼儿园招生报名小程序

shell------常用小工具,sort,uniq,tr,cut
升级适配AGP 7.0

【磁场建模项目2020-02-Lilin】采集板硬件规范

机器学习--数学库--概率统计

一种基于视频帧差异视频卡顿检测方案

{kind=link}
{kind=link}
{kind=link}
随机推荐
C语言程序设计笔记(浙大翁恺版) 第三周:判断
leetcode 剑指 Offer 07. 重建二叉树
C语言程序设计笔记(浙大翁恺版) 第十一周:结构类型
my creative day
外贸软件如何提升进出口公司业绩 实现降本增效
相似图像的检测方法
SMI 与 Gateway API 的 GAMMA 倡议意味着什么?
JS——循环结构经典例题解析与分享
OpenCV - 图像模板匹配 matchTemplate
【DevOps】jekins部署(一)
Swift中的Error处理
参考文献格式
回归测试:意义、挑战、最佳实践和工具
C语言程序设计笔记(浙大翁恺版) 第五周:循环控制
Use Baidu EasyDL to realize intelligent identification of health code/travel code in 30 minutes
[LeetCode] 485.最大连续 1 的个数
听书项目总结
VMWare不使用简易安装,手动安装ISO操作手册
玩转云端 | 天翼云电脑的百变玩法
常用sql记录