当前位置:网站首页>Reproduction of paper -- Libra r-cnn: rewards balanced learning for object detection
Reproduction of paper -- Libra r-cnn: rewards balanced learning for object detection
2022-04-21 14:37:00 【RooKiChen】
The reproduced paper has been open source , Just rely on mmdetection Environmental , stay linux Install first mmdetection It's more convenient , But in Windows Lower installation mmdetection It's not that convenient . Although but ... I'm a little lazy , Not installed on the school server mmdetection, So it reappeared itself .
LibraRCNN Official open source code :https://github.com/OceanPang/Libra_R-CNN
LibraRCNN Original thesis :https://arxiv.org/pdf/1904.02701.pdf
The specific implementation details of some papers are not clear , So I reproduce it according to my own understanding , If there are different methods, welcome to discuss in the comment area .
One 、LibraRCNN structure
The same as usual , First map :
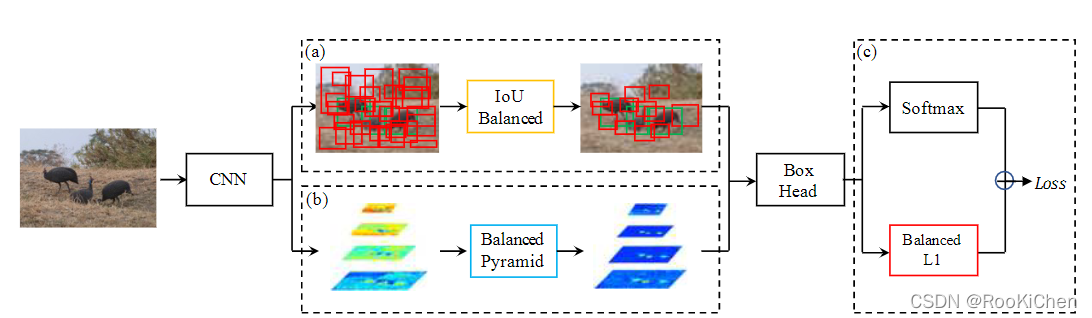
You can see from the picture above ,LibraRCNN The overall framework of is similar to FasterRCNN No difference , It mainly improves three parts :IoUBalanced、Balanced Pyramid、Banlanced L1, The full text revolves around Balanced, The name of the paper Libra It also means Libra , Let's explain these three parts in detail .
1.IoU Balanced
in the original , The authors say that random sampling will ignore some negative samples , Cause sample imbalance , So the random sampling is replaced by layered sampling , The specific formula is shown in the following figure :
Random sampling

Stratified sampling
Here in the original text K The default is 3

This part is relatively simple in code implementation , But there will be some details to deal with : When the number of boxes cannot be k Divisible time , You need to sample all the remaining boxes .
Here's a post IoU Balanced Implementation code , The specific code of the whole paper can refer to the link given at the end of the article .
# Stratified sampling
# First of all, will positive and negative Divided into three layers
k = 3
# There are several data in each layer
pk = positive.numel() // 3
fk = negative.numel() // 3
positive01 = positive[0:pk]
positive02 = positive[pk:pk * 2]
positive03 = positive[pk * 2:]
negative01 = negative[0:fk]
negative02 = negative[fk:fk * 2]
negative03 = negative[fk * 2:]
# Number of data collected per layer
num_pos_k = num_pos // 3
num_neg_k = num_neg // 3
# Start stratified sampling
rep01 = positive01[torch.randperm(positive01.numel(), device=positive.device)[:num_pos_k]]
rep02 = positive02[torch.randperm(positive02.numel(), device=positive.device)[:num_pos_k]]
rep03 = positive03[torch.randperm(positive03.numel(), device=positive.device)[:num_pos - 2*num_pos_k]]
ref01 = negative01[torch.randperm(negative01.numel(), device=negative.device)[:num_neg_k]]
ref02 = negative02[torch.randperm(negative02.numel(), device=negative.device)[:num_neg_k]]
ref03 = negative03[torch.randperm(negative03.numel(), device=negative.device)[:num_neg - 2*num_neg_k]]
pos_idx_per_image = torch.cat((rep01, rep02, rep03))
neg_idx_per_image = torch.cat((ref01, ref02, ref03))
2.Balanced Pyramid
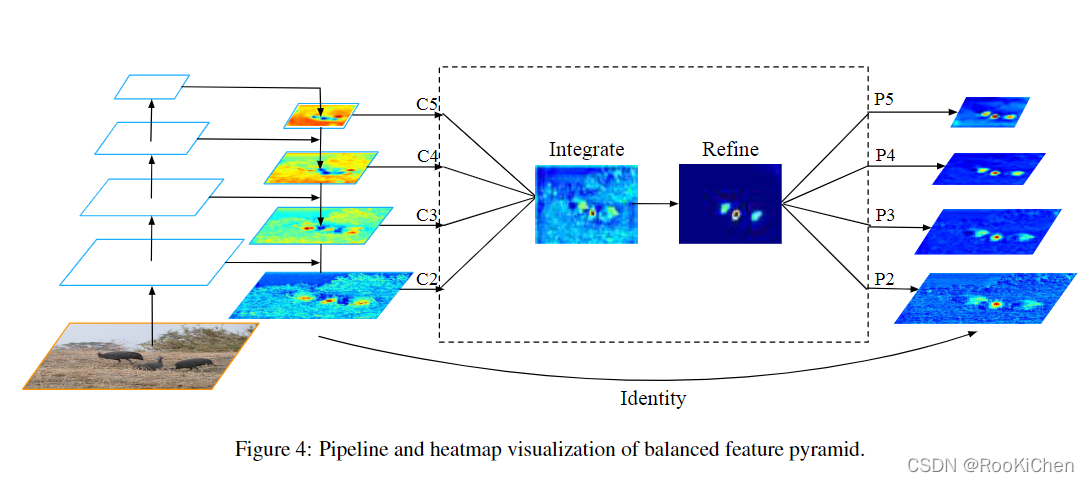
Here we need to pay attention to , The author put the original Pi(i=2,3,4,5) It has been written. Ci(i=2,3,4,5), As you can see from the picture ,Ci It is obtained through up sampling and feature fusion . Characteristics of figure Integrate By Ci After linear interpolation and maxpool Got , stay Refine In this step Non-local, about Non-local If you don't understand, you can read the original paper :https://arxiv.org/abs/1711.07971v1, Here is a general introduction Non-local: Follow self-attention be similar ,Non-local The purpose is to obtain global information , It can be understood as spatial attention mechanism (Non-local Module and Self-attention The relationship and difference between ). Why use here Non-local Well , The explanation given by the author in the original text is : Due to the characteristic diagram Integrate Fusion of multiple scales of information , Can cause serious information confusion , Therefore, the method of non local attention is used to further improve the detection performance ( The original said Refine This step can be used 3x3 Convolution layer or Non-local, If you use Non-local The amount of calculation is a little large , But use 3x3 The improvement of convolution effect is not obvious , So I finally chose to use Non-local). after Refine after , Or use linear interpolation and maxpool To get Ri(i=2,3,4,5), And will Ci And Ri Add up , Get the final prediction feature layer .
3. Balanced L1
Balanced L1 loss From the tradition smooth L1 loss, In this loss function , An inflection point is set to separate the inner value point from the outlier , And the maximum value is 1.0 The large gradient generated by the outliers of ( As shown in the figure below ), The purpose of this is to promote the regression of key gradients .
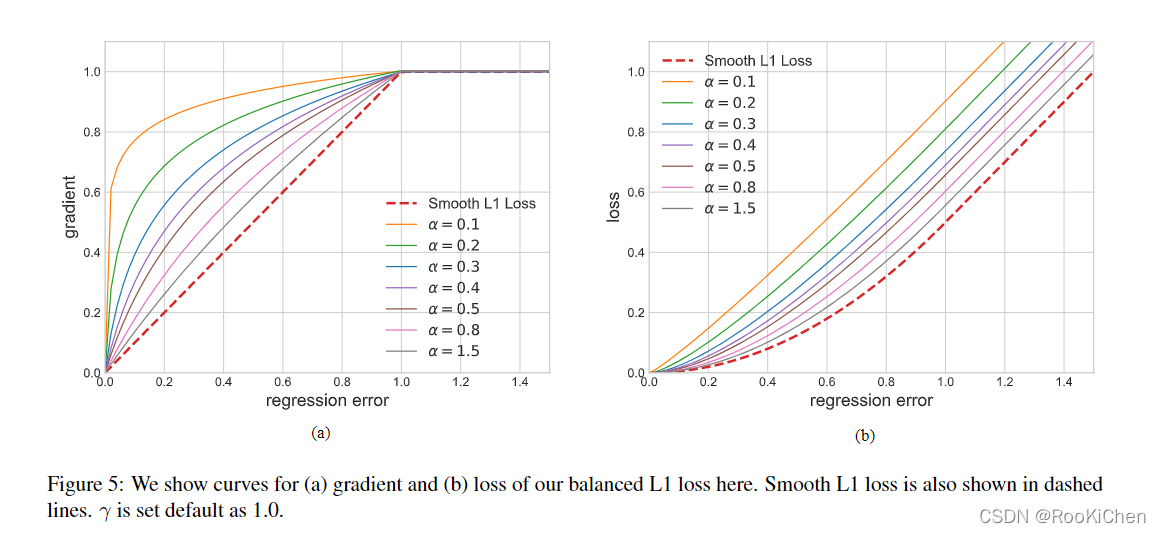
The original text gives α and γ The specific value of , Just integrate the following formula to get the loss function .
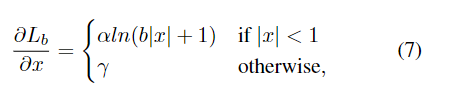
After integration, we can get the loss function L by :
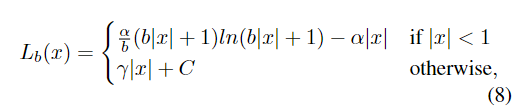
among C It's a constant :C = γ / b - α * 1
This part is also relatively simple to implement , Just tap the code into the formula and it's done :
def balanced_l1_loss(input, target, beta=1.0, alpha=0.5, gamma=1.5):
assert beta > 0
assert input.size() == target.size() and target.numel() > 0
diff = torch.abs(input - target)
b = np.e ** (gamma / alpha) - 1
loss = torch.where(
diff < beta, alpha / b *
(b * diff + 1) * torch.log(b * diff / beta + 1) - alpha * diff,
gamma * diff + gamma / b - alpha * beta)
return loss.sum()
What I use here is sum, Because I did it outside mean, The official code is obtained directly mean.
Two 、 Training strategy
use 8 individual GPU( Every GPU 2 Images ) To proceed 12 Round training , The initial learning rate is 0.02, If not specified , In the 8 And the 11 Lower them respectively after the wheel 0.1 times . Other super parameters refer to the code of my last blog :https://github.com/RooKichenn/CEFPN. No, 8 A small partner of a card can use four , each 4 Zhang image , The effect of training is no different .
3、 ... and 、 Duplicate code
Code synchronized to GitHub, welcome star:https://github.com/RooKichenn/LibraRCNN
版权声明
本文为[RooKiChen]所创,转载请带上原文链接,感谢
https://yzsam.com/2022/04/202204211432565170.html
边栏推荐
- 回归预测 | MATLAB实现Bayes-GRU(贝叶斯优化门控循环单元)多输入单输出
- Mysql数据库(3)
- Insect binary tree
- Object类
- 德鲁伊 数据库链接问题
- Detect and open WhatsApp
- leetcode答题笔记(一)
- [error record] file search strategy in groovy project (SRC / main / groovy / script. Groovy | groovy script directly uses the relative path of code in the main function)
- May day financial products have no income?
- 如何在excel中插入文件?Excel插入对象和附件有什么区别?(插入对象能直接显示内容,但我没显示?)
猜你喜欢

软件测试(三)p51-p104 软件测试用例方法、缺陷

pytorch图像分类篇:pytorch官方demo实现一个分类器(LeNet)

Mysql数据库(2)

Qt网络与通信(TCP聊天室)
![[groovy] mop meta object protocol and meta programming (use groovy meta programming to intercept functions and call other methods of the class through metaclass invokemethod method)](/img/d1/4944c77d1daf3d6ee1457a7934954f.png)
[groovy] mop meta object protocol and meta programming (use groovy meta programming to intercept functions and call other methods of the class through metaclass invokemethod method)
使用枚举做的红绿灯,有界面

LNK2001 - unresolved external symbol in PCL test program

英特尔最新成果:制造出大规模硅基量子比特

存储系统及存储器

阿里云云效研发协同服务相关协议条款 |云效
随机推荐
Bug file operation
虫子 Makefile
VS企业版代码图
虫子 插入 希尔
OpenSea 是如何成为最受欢迎的 NFT 市场的?
MySQL下载和安装教程
PCL测试程序出现LNK2001-无法解析的外部符号
股价暴跌 Robinhood收购英国加密公司求扩张
How to provide CPU branch prediction efficiency at the code level
阿里云云效研发协同服务相关协议条款 |云效
虫子 PWM
2023年大连理工大学资源与环境考研上岸前辈备考经验指导
接口需要向前兼容,不兼容时开v2接口
Mysql8.0以上重置初始密码的方法
swap交易所套利夹子机器人系统开发详情
SQL server variable assignment and batch processing
如何在excel中插入文件?Excel插入对象和附件有什么区别?(插入对象能直接显示内容,但我没显示?)
Insect stack to queue queue to stack
js正则表达式--个人常用
用数字“钥匙”打开发展新空间