当前位置:网站首页>[PRANET] thesis and code interpretation (RESNET part) -- Jiang Nie
[PRANET] thesis and code interpretation (RESNET part) -- Jiang Nie
2022-04-22 01:22:00 【cfsongbj】
1.ResNet Structure Introduction
ResNet—— The most important idea of residual neural network is to convolute the received data (F(x)), And then with their own identity(x) Add additivity ( namely F(x)+x), Then we passed together relu layer , Such a module is called the residual module , The residual neural network is composed of multiple residual modules and other layers .

Residual neural network has 18 layer 、34 layer 、50 Layers and so on , It is worth mentioning that from the 50 There are some differences between the residual module at the beginning of the layer and that before —— A few more 1*1 The convolution of layer , The purpose is to solve the problem at the end F(x)+x Problems with different dimensions during operation , At the same time, it can reduce the computational complexity of our network , This can be seen from the table FLOPs The value of .

2.ResNet Code details
a.BasicBlock class
class BasicBlock(nn.Module):
expansion: int = 1
def __init__(
self,
inplanes: int,
planes: int,
stride: int = 1,
downsample: Optional[nn.Module] = None,
groups: int = 1,
base_width: int = 64,
dilation: int = 1,
norm_layer: Optional[Callable[..., nn.Module]] = None
) -> None:
super(BasicBlock, self).__init__()
if norm_layer is None:
norm_layer = nn.BatchNorm2d
if groups != 1 or base_width != 64:
raise ValueError('BasicBlock only supports groups=1 and base_width=64')
if dilation > 1:
raise NotImplementedError("Dilation > 1 not supported in BasicBlock")
# Both self.conv1 and self.downsample layers downsample the input when stride != 1
self.conv1 = conv3x3(inplanes, planes, stride)
self.bn1 = norm_layer(planes)
self.relu = nn.ReLU(inplace=True)
self.conv2 = conv3x3(planes, planes)
self.bn2 = norm_layer(planes)
self.downsample = downsample
self.stride = stride
def forward(self, x: Tensor) -> Tensor:
identity = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
if self.downsample is not None:
identity = self.downsample(x)
out += identity
out = self.relu(out)
return out
b.Bottleneck class
class Bottleneck(nn.Module):
# Bottleneck in torchvision places the stride for downsampling at 3x3 convolution(self.conv2)
# while original implementation places the stride at the first 1x1 convolution(self.conv1)
# according to "Deep residual learning for image recognition"https://arxiv.org/abs/1512.03385.
# This variant is also known as ResNet V1.5 and improves accuracy according to
# https://ngc.nvidia.com/catalog/model-scripts/nvidia:resnet_50_v1_5_for_pytorch.
expansion: int = 4
def __init__(
self,
inplanes: int,
planes: int,
stride: int = 1,
downsample: Optional[nn.Module] = None,
groups: int = 1,
base_width: int = 64,
dilation: int = 1,
norm_layer: Optional[Callable[..., nn.Module]] = None
) -> None:
super(Bottleneck, self).__init__()
if norm_layer is None:
norm_layer = nn.BatchNorm2d
width = int(planes * (base_width / 64.)) * groups
# Both self.conv2 and self.downsample layers downsample the input when stride != 1
self.conv1 = conv1x1(inplanes, width)
self.bn1 = norm_layer(width)
self.conv2 = conv3x3(width, width, stride, groups, dilation)
self.bn2 = norm_layer(width)
self.conv3 = conv1x1(width, planes * self.expansion)
self.bn3 = norm_layer(planes * self.expansion)
self.relu = nn.ReLU(inplace=True)
self.downsample = downsample
self.stride = stride
def forward(self, x: Tensor) -> Tensor:
identity = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu(out)
out = self.conv3(out)
out = self.bn3(out)
if self.downsample is not None:
identity = self.downsample(x)
out += identity
out = self.relu(out)
return out
Above a And b Class is the code of the residual module used in the lower and higher layers of the network structure , adopt forward The function can correspond to the network structure mentioned at the beginning .
c.ResNet class
class ResNet(nn.Module):
def __init__(
self,
block: Type[Union[BasicBlock, Bottleneck]],
layers: List[int],
num_classes: int = 1000,
zero_init_residual: bool = False,
groups: int = 1,
width_per_group: int = 64,
replace_stride_with_dilation: Optional[List[bool]] = None,
norm_layer: Optional[Callable[..., nn.Module]] = None
) -> None:
super(ResNet, self).__init__()
if norm_layer is None:
norm_layer = nn.BatchNorm2d
self._norm_layer = norm_layer
self.inplanes = 64
self.dilation = 1
if replace_stride_with_dilation is None:
# each element in the tuple indicates if we should replace
# the 2x2 stride with a dilated convolution instead
replace_stride_with_dilation = [False, False, False]
if len(replace_stride_with_dilation) != 3:
raise ValueError("replace_stride_with_dilation should be None "
"or a 3-element tuple, got {}".format(replace_stride_with_dilation))
self.groups = groups
self.base_width = width_per_group
self.conv1 = nn.Conv2d(3, self.inplanes, kernel_size=7, stride=2, padding=3,
bias=False)
self.bn1 = norm_layer(self.inplanes)
self.relu = nn.ReLU(inplace=True)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.layer1 = self._make_layer(block, 64, layers[0])
self.layer2 = self._make_layer(block, 128, layers[1], stride=2,
dilate=replace_stride_with_dilation[0])
self.layer3 = self._make_layer(block, 256, layers[2], stride=2,
dilate=replace_stride_with_dilation[1])
self.layer4 = self._make_layer(block, 512, layers[3], stride=2,
dilate=replace_stride_with_dilation[2])
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.fc = nn.Linear(512 * block.expansion, num_classes)
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
elif isinstance(m, (nn.BatchNorm2d, nn.GroupNorm)):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
# Zero-initialize the last BN in each residual branch,
# so that the residual branch starts with zeros, and each residual block behaves like an identity.
# This improves the model by 0.2~0.3% according to https://arxiv.org/abs/1706.02677
if zero_init_residual:
for m in self.modules():
if isinstance(m, Bottleneck):
nn.init.constant_(m.bn3.weight, 0) # type: ignore[arg-type]
elif isinstance(m, BasicBlock):
nn.init.constant_(m.bn2.weight, 0) # type: ignore[arg-type]
def _make_layer(self, block: Type[Union[BasicBlock, Bottleneck]], planes: int, blocks: int,
stride: int = 1, dilate: bool = False) -> nn.Sequential:
norm_layer = self._norm_layer
downsample = None
previous_dilation = self.dilation
if dilate:
self.dilation *= stride
stride = 1
if stride != 1 or self.inplanes != planes * block.expansion:
downsample = nn.Sequential(
conv1x1(self.inplanes, planes * block.expansion, stride),
norm_layer(planes * block.expansion),
)
layers = []
layers.append(block(self.inplanes, planes, stride, downsample, self.groups,
self.base_width, previous_dilation, norm_layer))
self.inplanes = planes * block.expansion
for _ in range(1, blocks):
layers.append(block(self.inplanes, planes, groups=self.groups,
base_width=self.base_width, dilation=self.dilation,
norm_layer=norm_layer))
return nn.Sequential(*layers)
def _forward_impl(self, x: Tensor) -> Tensor:
# See note [TorchScript super()]
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.fc(x)
return x
def forward(self, x: Tensor) -> Tensor:
return self._forward_impl(x)
版权声明
本文为[cfsongbj]所创,转载请带上原文链接,感谢
https://yzsam.com/2022/04/202204220052293771.html
边栏推荐
- Shallow comparison between oceanbase and tidb - implementation plan
- Redis个人笔记:Redis应用场景,Redis常见命令,Reids缓存击穿穿透,Redis分布式锁实现方案,秒杀设计思路,Redis消息队列,Reids持久化,Redis主从哨兵分片集群
- 【PraNet】论文代码解读(损失函数部分)——Blank
- How does PR resize the cropped video to the desired size?
- A bug with a probability of occurrence less than one in ten thousand was captured
- April 21, 2022, day 14
- It's enough to study butterfly theme beautification
- On software development skills of swen2003
- 腾讯安卓开发面试经验,HR的话扎心了
- Redis personal notes: redis application scenario, redis common commands, redis cache breakdown and penetration, redis distributed lock implementation scheme, spike design idea, redis message queue, Re
猜你喜欢
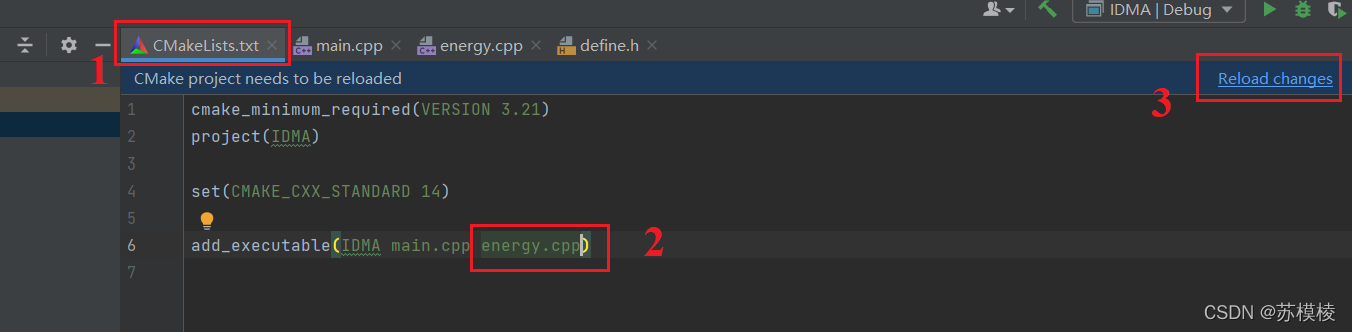
CLion中“This file does not belong to any project, code insight features might not work properly”的报错

In 2022, crud alone can't meet the interview and upgrading notes of large factories in spring recruitment

Live broadcast of goods, delivery of takeout and freight transportation. Airlines rely on sidelines to "return blood"
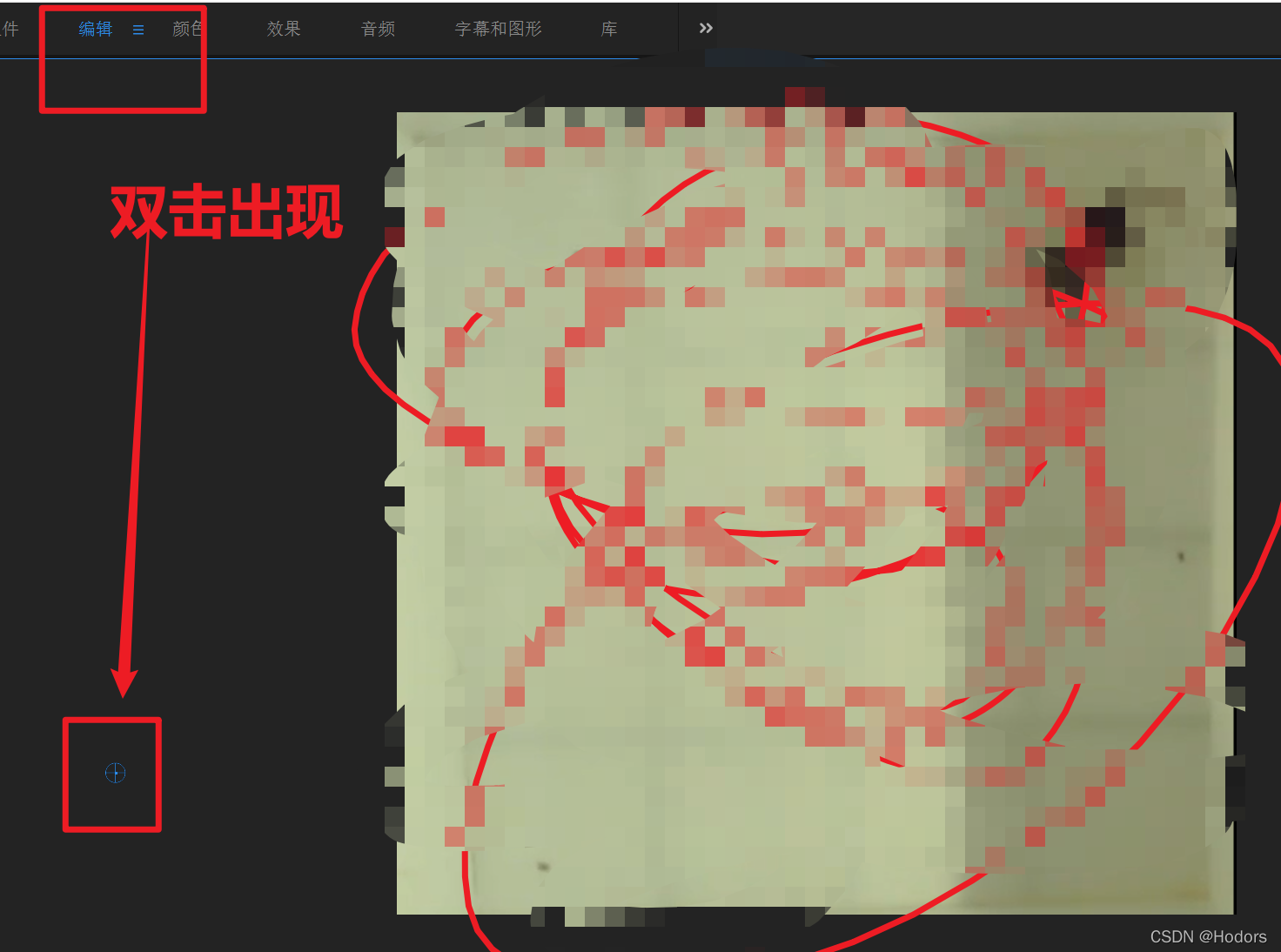
How does PR resize the cropped video to the desired size?
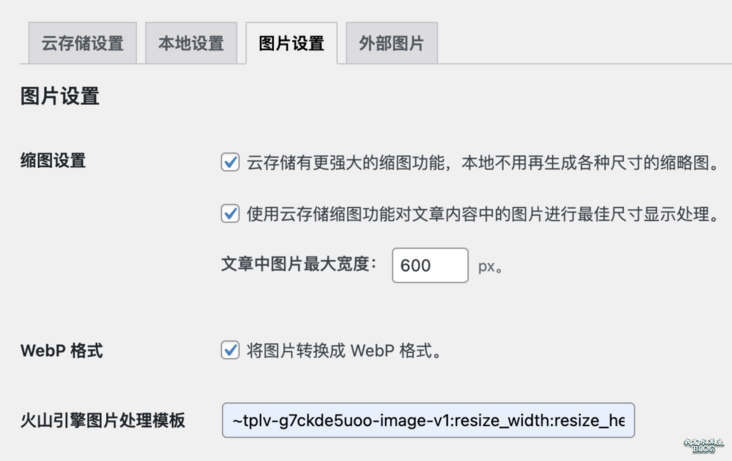
精品:千字长文教你使用字节跳动的火山引擎ImageX

Embedded GUI inventory - how many do you know?

3D 沙盒游戏之人物的点击行走移动

春招高频面试题:怎样设计秒杀系统?

This problem occurs if you are running in 64 bit mode with 32-bit Oracle client components installed
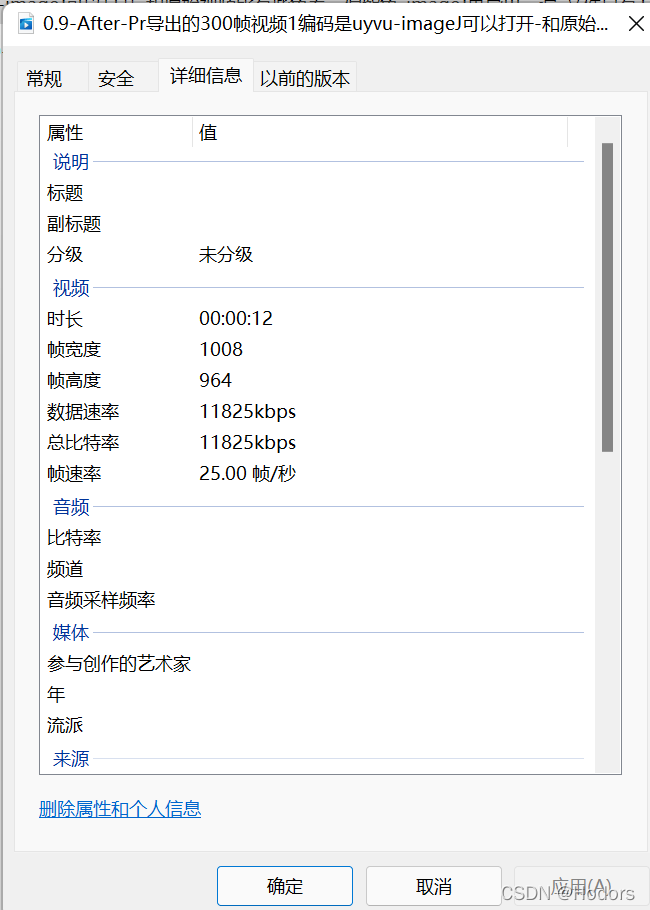
PR如何调整导出的数据速率和总比特率
随机推荐
Tencent team strength to create an introduction course to fluent, 1-3 years of Android Development Engineer Interview Experience Sharing
编译型VS解释型、动态类型VS静态类型
落地实例:带你六步拆解DDD
sql server 2008使用over(PARTITION BY..ORDER BY.. ) 显示有语法错误
While hoarding goods, it's time to recognize cans again
Boutique: thousand word long text teaches you to use byte beating volcanic engine imagex
Prometheus 的使用
The R language coin package is applied to permutation tests for independence problems and Wilcox Test function performs Wilcoxon signed rank test for two groups of data and wilcoxsign is used_ Test fu
In 2022, crud alone can't meet the interview and upgrading notes of large factories in spring recruitment
腾讯安卓开发面试经验,HR的话扎心了
Blazor University (12)组件 — 组件生命周期
简单理解变量的结构赋值
精品:千字长文教你使用字节跳动的火山引擎ImageX
The latest interview question of redis in 2022 Part 1 - basic knowledge of redis
Redis个人笔记:Redis应用场景,Redis常见命令,Reids缓存击穿穿透,Redis分布式锁实现方案,秒杀设计思路,Redis消息队列,Reids持久化,Redis主从哨兵分片集群
【Pranet】论文及代码解读(ResNet部分)——jialiang nie
April 21, 2022, day 14
PaddlePaddle基本用法详解(四)、PaddlePaddle训练文本分类模型
Servlet
谈谈SWEN20003软件开发技巧