当前位置:网站首页>Take yourself to learn paddle (4)
Take yourself to learn paddle (4)
2022-04-22 05:02:00 【MC. zeeyoung】
Item 1 Handwritten digit recognition
Review above , It has been revealed so far SGD as well as GPU Configuration mode , Now we will introduce how to integrate the drawing function and regularization
l2 norm
# Regularization terms can be added to various optimization algorithms , Avoid overfitting , Parameters regularization_coeff Adjust the weight of the regularization term
opt_norm=paddle.optimizer.Adam(learning_rate=1e-3,weight_decay=paddle.regularizer.L2Decay(coeff=1e-5),parameters=model.parameters())
drawing
Or use it matplotlib drawing , I modified the functions of the tutorial here
Go straight to the code
import matplotlib.pyplot as plt
import numpy as np
def plot_line(train_set,valid_set,title):
plt.figure()
plt.title("{}".format(title), fontsize=24)
plt.xlabel('epoch', fontsize=14)
plt.ylabel('value', fontsize=14)
epoch_id=np.arange(0,len(train_set))
plt.plot(epoch_id, train_set, color='blue', label='train {}'.format(title))
plt.plot(epoch_id, valid_set, color='red', label='valid {}'.format(title))
plt.grid()
plt.legend()
plt.show()
Finally, the overall code is as follows :
dataset.py
import os
import random
import paddle
import numpy as np
from PIL import Image
import gzip
import json
def load_data(mode='train'):
datafile='./work/mnist.json.gz'
print("loading mnist dataset from {} ...".format(datafile))
data=json.load(gzip.open(datafile))
train_set,val_set,eval_set=data
IMG_ROWS=28
IMG_COLS=28
# Assignment training 、 verification 、 test
if mode=='train':
imgs=train_set[0]
labels=train_set[1]
elif mode=='valid':
imgs=val_set[0]
labels=val_set[1]
elif mode=='eval':
imgs=eval_set[0]
labels=eval_set[1]
imgs_length=len(imgs)
assert len(imgs)==len(labels),"length of train_imgs({}) should be the same as train_labels({})".format(
len(imgs),len(labels)
)
index_list=list(range(imgs_length))
BATCH_SIZE=100
def data_generator():
if mode=='train':
random.shuffle(index_list)
imgs_list=[]
labels_list=[]
for i in index_list:
img=np.reshape(imgs[i],[1,IMG_ROWS,IMG_COLS]).astype('float32')
label=np.reshape(labels[i],[1]).astype('int64')
imgs_list.append(img)
labels_list.append(label)
# If the current data cache reaches batchsize, Just return a batch data
if len(imgs_list)==BATCH_SIZE:
yield np.array(imgs_list),np.array(labels_list)
imgs_list=[]
labels_list=[]
if len(imgs_list)>0:
yield np.array(imgs_list),np.array(labels_list)
return data_generator
network.py
import paddle.nn.functional as F
from paddle.nn import Conv2D,MaxPool2D,Linear
import paddle
class MNIST(paddle.nn.Layer):
def __init__(self):
super(MNIST, self).__init__()
# Define convolutions
self.conv1=Conv2D(in_channels=1,out_channels=20,kernel_size=5,stride=1,padding=2)
# Define the pooling layer
self.max_pool1=MaxPool2D(kernel_size=2,stride=2)
# Define convolutions
self.conv2=Conv2D(in_channels=20,out_channels=20,kernel_size=5,stride=1,padding=2)
# Define the pooling layer
self.max_pool2=MaxPool2D(kernel_size=2,stride=2)
# Fully connected layer
self.fc=Linear(in_features=980,out_features=10)
def forward(self,inputs,labels):
x=self.conv1(inputs)
x=F.relu(x)
x=self.max_pool1(x)
x=F.relu(x)
x=self.conv2(x)
x=F.relu(x)
x=self.max_pool2(x)
x=paddle.reshape(x,[x.shape[0],980])
x=self.fc(x)
if labels is not None:
acc=paddle.metric.accuracy(input=x,label=labels)
return x,acc
else:
return x
The main function
from dataset import load_data
from network import MNIST
import paddle.nn.functional as F
import paddle
import numpy as np
from plot import plot_line
def train(model):
model.train()
opt=paddle.optimizer.Adam(learning_rate=1e-3,parameters=model.parameters())
# # Regularization terms can be added to various optimization algorithms , Avoid overfitting , Parameters regularization_coeff Adjust the weight of the regularization term
opt_norm=paddle.optimizer.Adam(learning_rate=1e-3,weight_decay=paddle.regularizer.L2Decay(coeff=1e-5),parameters=model.parameters())
EPOCH_NUM=5
train_acc_set = []
train_avg_loss_set = []
valid_acc_set = []
valid_avg_loss_set = []
for epoch_id in range(EPOCH_NUM):
acc_set = []
avg_loss_set = []
for batch_id,data in enumerate(train_loader()):
images,labels=data
images=paddle.to_tensor(images)
labels=paddle.to_tensor(labels)
predicts,acc=model(images,labels)
loss=F.cross_entropy(predicts,labels)
avg_loss=paddle.mean(loss)
acc_set.append(float(acc.numpy()))
avg_loss_set.append(float(avg_loss.numpy()))
if batch_id % 200 == 0:
print("epoch:{}, batch:{}, loss is {}, acc is {}".format(
epoch_id,batch_id,avg_loss.numpy(),acc.numpy()
))
avg_loss.backward()
opt_norm.step()
opt_norm.clear_grad()
# Count one epoch Of loss as well as train acc
acc_val_mean = np.array(acc_set).mean()
avg_loss_val_mean = np.array(avg_loss_set).mean()
val_acc_set,val_avg_loss_set=evaluation(model)
train_acc_set.append(acc_val_mean)
train_avg_loss_set.append(avg_loss_val_mean)
valid_acc_set.append(val_acc_set)
valid_avg_loss_set.append(val_avg_loss_set)
paddle.save(model.state_dict(),'mnist.pdparams')
return train_acc_set,train_avg_loss_set,valid_acc_set,valid_avg_loss_set
def evaluation(model):
model.eval()
eval_loader=load_data('valid')
acc_set=[]
avg_loss_set=[]
for batch_id,data in enumerate(eval_loader()):
images,labels=data
images=paddle.to_tensor(images)
labels=paddle.to_tensor(labels)
predicts,acc=model(images,labels)
loss=F.cross_entropy(input=predicts,label=labels)
avg_loss=paddle.mean(loss)
acc_set.append(float(acc.numpy()))
avg_loss_set.append(float(avg_loss.numpy()))
acc_val_mean=np.array(acc_set).mean()
avg_loss_val_mean=np.array(avg_loss_set).mean()
print("loss:{} acc:{}".format(avg_loss_val_mean,acc_val_mean))
return acc_val_mean,avg_loss_val_mean
def test(model):
print("start evaluation.............")
params_file_path='mnist.pdparams'
param_dict=paddle.load(params_file_path)
model.load_dict(param_dict)
model.eval()
eval_loader=load_data('eval')
acc_set=[]
avg_loss_set=[]
iters = []
iter = 0
losses = []
for batch_id,data in enumerate(eval_loader()):
images,labels=data
images=paddle.to_tensor(images)
labels=paddle.to_tensor(labels)
predicts,acc=model(images,labels)
loss=F.cross_entropy(input=predicts,label=labels)
avg_loss=paddle.mean(loss)
iters.append(iter)
losses.append(avg_loss.numpy())
iter = iter + 1
acc_set.append(float(acc.numpy()))
avg_loss_set.append(float(avg_loss.numpy()))
acc_val_mean=np.array(acc_set).mean()
avg_loss_val_mean=np.array(avg_loss_set).mean()
print("loss:{} acc:{}".format(avg_loss_val_mean,acc_val_mean))
return iters,losses
train_loader=load_data('train')
use_gpu=True
paddle.set_device("gpu:0") if use_gpu else paddle.set_device("cpu")
model=MNIST()
train_acc_set,train_avg_loss_set,valid_acc_set,valid_avg_loss_set=train(model)
test(model)
''' drawing '''
plot_line(train_acc_set,valid_acc_set,'loss')
plot_line(train_avg_loss_set,valid_avg_loss_set,'acc')
Training effect :
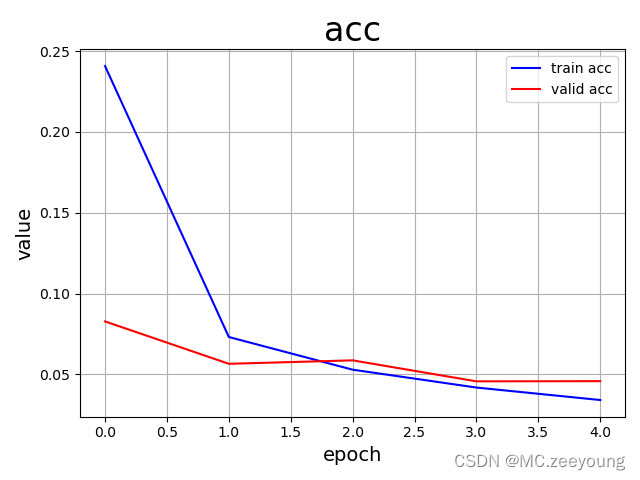

The next two sections will experience the process of re training breakpoints and converting dynamic graphs to static graphs , expect hhhh
版权声明
本文为[MC. zeeyoung]所创,转载请带上原文链接,感谢
https://yzsam.com/2022/04/202204210717153287.html
边栏推荐
- Paper reading - access pattern disclosure on searchable encryption: allocation, attack and deviation (2012)
- On the unsuccessful creation of SQLite database in Android development real machine debugging
- Interpretation of the report Download | the future of database and the development trend and challenges of database in the 14th five year plan
- What is idempotency
- Servlet lifecycle
- Swagger UI简介
- 常见的测试方式
- Inotify Brief
- Jackson
- [SQL Server accelerated path] database and table (II)
猜你喜欢
【板栗糖GIS】arcmap—如何制作带缓冲区的图幅结合表

Logistic regression -- case: cancer classification and prediction

JVM - common parameters
Combined sum leetcode

Carina 的根基与诞生背景|深入了解 Carina 系列 第一期
Carina's foundation and birth background | deeply understand the first issue of carina series

Autojs automation script how to develop on the computer, detailed reliable tutorial!!!
![[I. XXX pest detection project] 2. Trying to improve the network structure: resnet50, Se, CBAM, feature fusion](/img/78/c50eaa02e26ef7c5e88ec8ad92ab13.png)
[I. XXX pest detection project] 2. Trying to improve the network structure: resnet50, Se, CBAM, feature fusion

Several key points of logistic regression

【Selenium】Yaml数据驱动
随机推荐
Request and response objects
Application of an open current transformer with switching value
JVM throughput
[chestnut sugar GIS] ArcMap - Model Builder - batch clipping grid data
[SQL Server accelerated path] database and table (II)
【板栗糖GIS】supermap—如何為數據制造超鏈接
Chapter 6 Association query
Prometheus basic knowledge brain map
Calculator (force buckle)
EMO-DB 数据集的 Speech 特征提取
Inotify Brief
Linear regression of machine learning
Chapter 2 MySQL data types and operators
How does docker access redis service 6379 port in the host
Carina 的根基与诞生背景|深入了解 Carina 系列 第一期
Junit簡介與入門
Jackson
JUnit assertion
Introduction to swagger UI
Visio setting network topology