当前位置:网站首页>快照集成(Snapshot Ensemble)
快照集成(Snapshot Ensemble)
2022-08-08 20:54:00 【yddcs】
快照集成
Snapshot Ensemble
发表于 ICLR 2017 论文地址及代码见下
Paper: https://arxiv.org/pdf/1704.00109.pdf
找论文搭配 Sci-Hub 食用更佳
Sci-Hub 实时更新 : https://tool.yovisun.com/scihub/
公益科研通文献求助:https://www.ablesci.com/
代码在最下面,也可以访问Github,及其他集成学习代码也在
只需要训练一次就可以得到收敛于多个不同最小值处的模型,从而进行模型集成。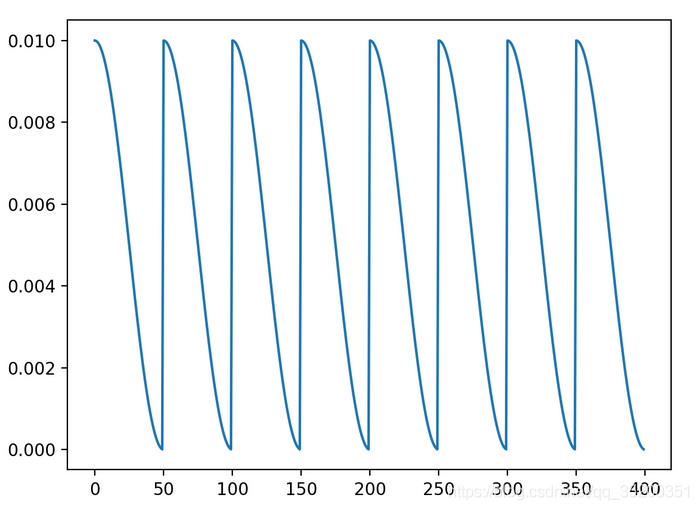
快拿去测试你的数据吧!
from sklearn.datasets import make_blobs
from keras.utils import to_categorical
from keras.models import Sequential
from keras.layers import Dense
from keras.callbacks import Callback
from keras.optimizers import SGD
from keras import backend
from math import pi, cos, floor
from sklearn.datasets import make_blobs
from sklearn.metrics import accuracy_score
from keras.models import load_model, Sequential
from keras.layers import Dense
from matplotlib import pyplot
from numpy import std, mean, array, argmax
import numpy as np
# snapshot ensemble with custom learning rate schedule
class SnapshotEnsemble(Callback):
# constructor
def __init__(self, n_epochs, n_cycles, lrate_max, verbose=0):
self.epochs = n_epochs
self.cycles = n_cycles
self.lr_max = lrate_max
self.lrates = list()
# calculate learning rate for epoch
def cosine_annealing(self, epoch, n_epochs, n_cycles, lrate_max):
epochs_per_cycle = floor(n_epochs/n_cycles)
cos_inner = (pi * (epoch % epochs_per_cycle)) / (epochs_per_cycle)
return lrate_max/2 * (cos(cos_inner) + 1)
# calculate and set learning rate at the start of the epoch
def on_epoch_begin(self, epoch, logs={
}):
# calculate learning rate
lr = self.cosine_annealing(epoch, self.epochs, self.cycles, self.lr_max)
# set learning rate
backend.set_value(self.model.optimizer.lr, lr)
# log value
self.lrates.append(lr)
# save models at the end of each cycle
def on_epoch_end(self, epoch, logs={
}):
# check if we can save model
epochs_per_cycle = floor(self.epochs / self.cycles)
if epoch != 0 and (epoch + 1) % epochs_per_cycle == 0:
# save model to file
filename = "snapshot_model_energy_%d.h5" % int((epoch + 1) / epochs_per_cycle)
self.model.save(filename)
print('>saved snapshot %s, epoch %d' % (filename, epoch))
# load models from file
def load_all_models(n_models):
all_models = list()
for i in range(n_models):
# define filename for this ensemble
filename = 'snapshot_model_energy_' + str(i + 1) + '.h5'
# load model from file
model = load_model(filename)
# add to list of members
all_models.append(model)
print('>loaded %s' % filename)
return all_models
# make an ensemble prediction for multi-class classification
def ensemble_predictions(members, testX):
# make predictions
yhats = [model.predict(testX) for model in members]
yhats = array(yhats)
# sum across ensemble members
summed = np.sum(yhats, axis=0) # soft voting
# argmax across classes
result = argmax(summed, axis=1)
return result
# evaluate a specific number of members in an ensemble
def evaluate_n_members(members, n_members, testX, testy):
# select a subset of members
subset = members[:n_members]
# make prediction
yhat = ensemble_predictions(subset, testX)
# calculate accuracy
return accuracy_score(testy, yhat) # precision f1 recall
from sklearn.model_selection import train_test_split
# load data train_test_split
data_train = np.loadtxt(open("D:/what.csv", encoding='gb18030', errors="ignore"), delimiter=",", skiprows=0)
X_train, y_train = data_train[:, :-1], data_train[:, -1]
trainX, testX, trainy, testy = train_test_split(X_train, y_train, test_size = .3, random_state = 3)
# print(trainX.shape, testX.shape, trainy.shape)
trainy_enc = to_categorical(trainy)
testy_enc = to_categorical(testy)
#print(trainX.shape, testX.shape, trainy.shape)
# define model
model = Sequential()
model.add(Dense(96, input_dim=28*28, activation='relu'))
model.add(Dense(10, activation='softmax'))
opt = SGD(momentum=0.99)
model.compile(loss='categorical_crossentropy', optimizer=opt, metrics=['accuracy'])
# create snapshot ensemble callback
n_epochs = 400
n_cycles = n_epochs / 50
batch_size = 128
ca = SnapshotEnsemble(n_epochs, n_cycles, 0.001)
# fit model
model.fit(trainX, trainy_enc, batch_size=batch_size, validation_data=(testX, testy_enc), epochs=n_epochs, verbose=0, callbacks=[ca])
# load models in order
members = load_all_models(10)
print('Loaded %d models' % len(members))
# reverse loaded models so we build the ensemble with the last models first
members = list(reversed(members))
# evaluate different numbers of ensembles on hold out set
single_scores, ensemble_scores = list(), list()
for i in range(1, len(members)+1):
# evaluate model with i members
ensemble_score = evaluate_n_members(members, i, testX, testy)
# evaluate the i'th model standalone
_, single_score = members[i-1].evaluate(testX, testy_enc, verbose=0)
# summarize this step
print('> %d: single=%.5f, ensemble=%.5f' % (i, single_score, ensemble_score))
ensemble_scores.append(ensemble_score)
single_scores.append(single_score)
# summarize average accuracy of a single final model
print('Accuracy %.5f (%.5f)' % (mean(single_scores), std(single_scores)))
# plot score vs number of ensemble members
x_axis = [i for i in range(1, len(members)+1)]
pyplot.plot(x_axis, single_scores, marker='o', linestyle='None')
pyplot.plot(x_axis, ensemble_scores, marker='x')
pyplot.show()
边栏推荐
猜你喜欢






随机推荐
使用fontforge修改字体,只保留数字
有幸与美团大佬共同探讨单节点连接数超1.5W的问题
Flask 教程 第七章:错误处理
Flask 教程 第三章:Web表单
Use fontforge to modify font, keep only numbers
jmeter逻辑控制器使用
源码分析MyCat专栏
学习笔记:线性表的顺序表示和实现(二级指针实现)
Kotlin笔记-ForEach与ForEachIndexed区别
jmeter简单压测
随手记:laravel、updateOrCreate 和 updateOrInsert 的区别
常见的病毒(攻击)分类
Kotlin parsing String path knowledge
安装sentry
The new library online | CnOpenDataA shares of the listed company basic information data
mysql8设置远程连接
Educational Codeforces Round 112 D. Say No to Palindromes
内网渗透之代理转发
Flask 教程 第九章:分页
怎样在网上开户买股票比较安全?如何办理开户业务?