当前位置:网站首页>Detailed understanding of anonymous functions and all built-in functions (Part 2)
Detailed understanding of anonymous functions and all built-in functions (Part 2)
2022-08-10 15:33:00 【HUAWEI CLOUD】
文章目录
️前言
️前言
以下我要讲解的是Python中最后剩余的重要内置函数,其中比较重要的会详细讲解,比较简单的会直接结合代码进行剖析
一、reversed内置函数
描述
reversed 函数返回一个反转的迭代器.语法
reversed(seq)
参数
seq -- 要转换的序列,可以是 tuple, string, list 或 range.
返回值
返回一个反转的迭代器.#使用reverse后原列表就不见了l = [1,2,3,4,5]l.reverse()print(l)#保留原列表,返回一个反向的迭代器l = [1,2,3,4,5]l2 = reversed(l)print(l2)输出解果:[5, 4, 3, 2, 1]<list_reverseiterator object at 0x000001BF41858F40>
二、slice内置函数
描述
slice() 函数实现切片对象,主要用在切片操作函数里的参数传递.语法
slice 语法:class slice(stop)
class slice(start, stop[, step])
参数说明:start -- 起始位置
stop -- 结束位置
step -- 间距
返回值
返回一个切片对象.l = (1,2,3,4,5,6)#先得到了一个切片规则sli = slice(1,5,2)#按切片规则进行切分print(l[sli])输出结果:(2, 4)
三、format内置函数
知识点:
四、bytes内置函数
描述
bytes 函数返回一个新的 bytes 对象,该对象是一个 0 <= x < 256 区间内的整数不可变序列.它是 bytearray 的不可变版本.语法
以下是 bytes 的语法:class bytes([source[, encoding[, errors]]])
参数
如果 source 为整数,则返回一个长度为 source 的初始化数组;
如果 source 为字符串,则按照指定的 encoding 将字符串转换为字节序列;
如果 source 为可迭代类型,则元素必须为[0 ,255] 中的整数;
如果 source 为与 buffer 接口一致的对象,则此对象也可以被用于初始化 bytearray.
如果没有输入任何参数,默认就是初始化数组为0个元素.
返回值
返回一个新的 bytes 对象.注意:
网络编程只能传二进制
照片和视频也是以二进制存储
html网页爬取到的也是编码
#我拿到的是gbk编码的,我想转成utf-8编码print(bytes('你好',encoding='gbk').decode('gbk'))#unicode转换为utf-8的bytesprint(bytes('你好',encoding='utf-8'))输出结果:你好b'\xe4\xbd\xa0\xe5\xa5\xbd'
五、bytearray内置函数
描述
bytearray() 方法返回一个新字节数组.这个数组里的元素是可变的,并且每个元素的值范围: 0 <= x < 256.语法
bytearray()方法语法:class bytearray([source[, encoding[, errors]]])
参数
如果 source 为整数,则返回一个长度为 source 的初始化数组;
如果 source 为字符串,则按照指定的 encoding 将字符串转换为字节序列;
如果 source 为可迭代类型,则元素必须为[0 ,255] 中的整数;
如果 source 为与 buffer 接口一致的对象,则此对象也可以被用于初始化 bytearray.
如果没有输入任何参数,默认就是初始化数组为0个元素.
返回值
返回新字节数组.b_array = bytearray('你好',encoding='utf-8')print(b_array)print(b_array[0])输出结果:bytearray(b'\xe4\xbd\xa0\xe5\xa5\xbd')228
六、memoryview内置函数
描述
memoryview() 函数返回给定参数的内存查看对象(memory view).所谓内存查看对象,是指对支持缓冲区协议的数据进行包装,在不需要复制对象基础上允许Python代码访问.
语法
memoryview(obj)
参数说明:obj -- 对象
返回值
返回元组列表.
#切片 —— 字节类型的切片v = memoryview(bytearray("abcd", 'utf-8'))print(v[1])输出结果:98
七、ord、chr和ascii内置函数
#ord 将字符按照unicode转数字>>>print(ord('a'))>>>print(ord('A'))>>>print(ord('1'))976549#chr 数字按照unicode转字符>>>print(chr(65))>>>print(chr(97))Aa#ascii 只要是ASCII码中的内容就打印出来,不是就转换为\u#ascii 包括字母、数字、符号、拉丁文>>>print(ascii('你好'))>>>print(ascii(1))>>>print(ascii("_12"))>>>print(ascii('a'))'\u4f60\u597d'1'_12''a'
八、repr内置函数
描述
repr() 函数将对象转化为供解释器读取的形式.语法
以下是 repr() 方法的语法:repr(object)
参数
object -- 对象.
返回值
返回一个对象的 string 格式.#可以判断控制台输出的数据是何类型print(repr('1'))print(repr(1))输出结果:'1'1
九、enumerate内置函数
描述
enumerate() 函数用于将一个可遍历的数据对象(如列表、元组或字符串)组合为一个索引序列,同时列出数据和数据下标,一般用在 for 循环当中.语法
以下是 enumerate() 方法的语法:enumerate(sequence, [start=0])
参数
sequence -- 一个序列、迭代器或其他支持迭代对象.
start -- 下标起始位置.
返回值
返回 enumerate(枚举) 对象.lst = ['a','b','c']print(list(enumerate(lst)))for i in enumerate(lst): print(i)输出结果:[(0, 'a'), (1, 'b'), (2, 'c')](0, 'a')(1, 'b')(2, 'c')
十、all和any内置函数
- all:用于判断给定的可迭代参数 iterable 中的所有元素是否有bool值为False,如果有则返回 True,否则返回 False.元素除了是 0、空、None、False 外都算 True.
- any:用于判断给定的可迭代参数 iterable 是否有bool值为 True的元素,如果有一个为 True,没有一个则返回 False.元素除了是 0、空、FALSE 外都算 TRUE.
print(all([1,'','a']))print(all([1,'a']))print(all([0,123]))输出结果:FalseTrueFalseprint(any(['','Ture',123]))print(any(['',0]))输出结果:TrueFalse
十一、zip内置函数
描述
zip() 函数用于将可迭代的对象作为参数,将对象中对应的元素打包成一个个元组,然后返回由这些元组组成的对象,这样做的好处是节约了不少的内存.我们可以使用 list() 转换来输出列表.
如果各个迭代器的元素个数不一致,则返回列表长度与最短的对象相同,利用 * 号操作符,可以将元组解压为列表.
zip 方法在 Python 2 和 Python 3 中的不同:在 Python 2.x zip() 返回的是一个列表.
语法
zip 语法:zip([iterable, ...])
参数说明:iterabl -- 一个或多个迭代器;
返回值
返回一个对象.l1 = [1,2,3]l2 = ['a','b','c','d']l3 = [{1,2},'**']print(zip(l1,l2))for i in zip(l1,l2): print(i)print("=======================")for i in zip(l1,l2,l3): print(i)输出结果:<zip object at 0x000001967CE0B600>(1, 'a')(2, 'b')(3, 'c')=======================(1, 'a', {1, 2})(2, 'b', '**')
十二、filter和map内置函数
1、filter内置函数
filter() 函数用于过滤序列,过滤掉不符合条件的元素,返回一个迭代器对象,如果要转换为列表,可以使用 list() 来转换.
该接收两个参数,第一个为函数,第二个为序列,序列的每个元素作为参数传递给函数进行判断,然后返回 True 或 False,最后将返回 True 的元素放到新列表中.
def is_odd(x): return x % 2 == 1ret = filter(is_odd,[1,2,4,7,9])print(ret)print([i for i in ret])输出结果:<filter object at 0x000001FF38B48640>[1, 7, 9]2、map内置函数
map() 函数会根据提供的函数对指定序列做映射.
第一个参数 function 以参数序列中的每一个元素调用 function 函数,返回包含每次 function 函数返回值的新列表.
ret = map(abs,[1,-4,6,-9])print(ret)print([i for i in ret])输出结果:<map object at 0x000001CF1D7C90A0>[1, 4, 6, 9]3、总结
filter 执行了filter之后的结果集合元素个数 <= 执行之前的个数
filter只管筛选,执行前后不会改变原来的值
map 执行前后元素个数保持不变
map执行前后原来的值可能会发生改变
十三、sorted内置函数
十四、匿名函数
匿名函数:为了解决那些功能很简单的需求而设计的一句话函数
#将以下函数变为匿名函数def add1(x,y): return x + yadd2 = lambda x,y : x + yprint(add1(1,3))print(add2(2,4))输出结果:46

边栏推荐
猜你喜欢
Yi Gene|In-depth review: epigenetic regulation of m6A RNA methylation in brain development and disease
微信小程序,自定义输入框与导航胶囊对其

中学数学建模书籍及相关的视频等(2022.08.09)

富爸爸穷爸爸之读书笔记

容器化 | 在 S3 实现定时备份
E. Cross Swapping (and check out deformation/good questions)
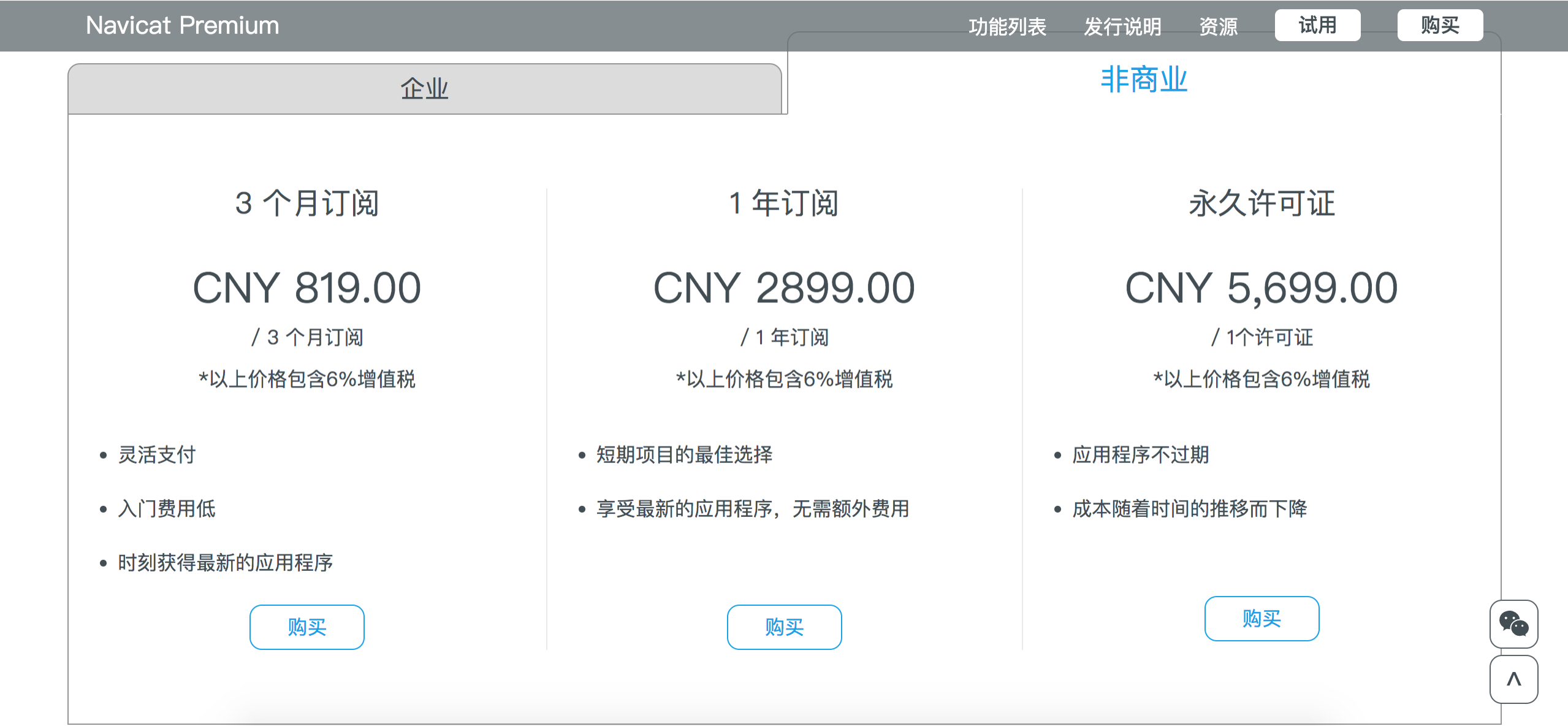
推荐几款最好用的MySQL开源客户端,建议收藏!
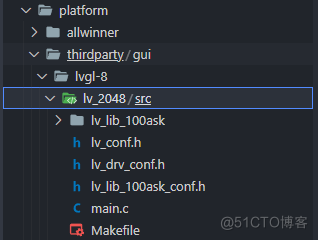
全志V853开发板移植基于 LVGL 的 2048 小游戏
BCG库简介
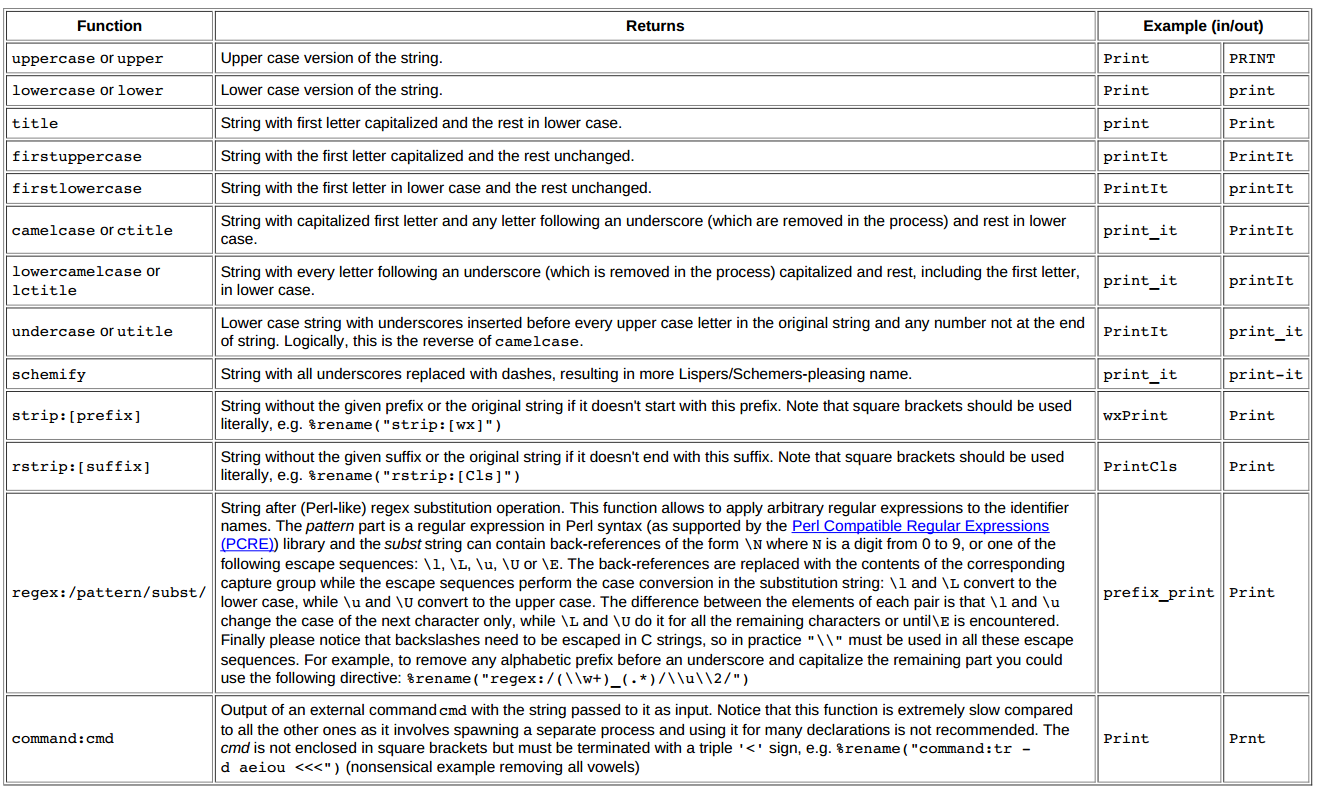
SWIG tutorial "two"
随机推荐
学习MySQL 临时表
【芯片】人人皆可免费造芯?谷歌开源芯片计划已释放90nm、130nm和180nm工艺设计套件
【教程】HuggingFace的Optimum组件已支持加速Graphcore和英特尔Habana芯片
老板加薪!看我做的WPF Loading!!!
[Data warehouse design] Why should enterprise data warehouses be layered?(six benefits)
MySQL批量更新与批量更新多条记录的不同值实现方法
Redis -- Nosql
请查收 2022华为开发者大赛备赛攻略
SWIG教程《二》
systemui状态栏添加新图标
MySQL命令行导出导入数据库
华为云DevCloud获信通院首批云原生技术架构成熟度评估的最高级认证
SWIG Tutorial "One"
全部内置函数详细认识(中篇)
SWIG tutorial "two"
第贰章模块大全之《 collections模块》
关于async\await 的理解和思考
无线网络、HTTP缓存、IPv6
“蔚来杯“2022牛客暑期多校训练营7
Systemui status bar to add a new icon