当前位置:网站首页>kaggle实战4.1--时间序列预测问题
kaggle实战4.1--时间序列预测问题
2022-04-22 04:40:00 【会震pop的码农】
这个时间预测序列对应的是kaggle上Time Series的course,course的连接贴在下方
时间序列预测kaggle教程
本文使用的数据集的地址:
图书销售量数据集
第一课 线性回归和时间序列
引言
预测可能是机器学习在现实世界中最常见的应用。企业预测产品需求,政府预测经济和人口增长,气象学家预测天气。对未来事物的理解是整个科学、政府和行业的迫切需要(更不用说我们的个人生活了!),这些领域的从业者正越来越多地应用机器学习来满足这一需求。
时间序列预测是一个具有悠久历史的广泛领域。本课程的重点是将现代机器学习方法应用于时间序列数据,目的是产生最准确的预测。
时间序列
预测的基本对象是时间序列,它是一组随时间变化而记录的观测值。在预测应用中,观察结果通常以固定的频率记录,如每天或每月。

这里我们将数据集打开,并且我们这里舍弃paperback(平装本)只看hardcover(精装本)这一个特征和时间之间的关系。
这个数据集记录了一个零售店在30天内销售的精装书的数量。请注意,我们有一列观察值Hardcover,其时间指数为Date。
时间序列的线性回归
在本课程的第一部分,我们将使用线性回归算法来构建预测模型。线性回归在实践中被广泛使用,甚至可以自然地适应复杂的预测任务。
线性回归算法学习如何从其输入特征中进行加权求和。对于两个特征,我们会有如下的式子:
target = weight_1 * feature_1 + weight_2 * feature_2 + bias
其中feature代表的是数据的特征,也可以理解为数据的维度。
在训练过程中,回归算法学习了最适合目标的参数权重_1、权重_2和偏置值。(这种算法通常被称为普通最小二乘法,因为它选择的是目标和预测之间平方误差最小的值)。权重也被称为回归系数,偏置也被称为截距,因为它告诉你这个函数的图形与Y轴的交叉点。
时间步长的特征
时间步长的特征
时间序列有两种特有的特征:时间步长特征 (time-step features) 和滞后特征 (lag features)。
时间步长特征是我们可以直接从时间的变化中得到的特征。最基本的时间步长特征是time dummy,它将系列中的时间步长从开始到结束进行计数。
这里解释一下time dummy变量是个什么意思。一开始博主在看到这里的时候也不太能李姐这是个什么东西,后来搜了一下发现其实这个就是我们一直用的one-hot vector(独热编码)。就是当我们的时间变量为某个值时,我们就将这个变量所对应的设置为1,其它的时间点都设置为0,这样的话其它时间点就不会对我们所讨论的当前时间点造成任何影响。
在本题中设置这样一个time dummy变量是为了代替原来数据中用年月日表示的时间。因为这数据集中时间是连续的,所以我们也直接选取了30个连续的数字来替换掉原来的时间,这样会让我们线性回归的x轴看起来更简单。

import matplotlib.pyplot as plt
import seaborn as sns
plt.style.use("seaborn-whitegrid")
plt.rc(
"figure",
autolayout = True,
figsize = (11, 4),
titlesize = 8,
titleweight = 'bold',
)#这一大坨是设置画布的各种参数
plt.rc(
"axes",
labelweight = 'bold',
labelsize = 'large',
titleweight = 'bold',
titlesize = 16,
titlepad = 10,
)#这一大坨是设置坐标轴的各种参数
%config InlineBackend.figure_format = 'retina'
fig, ax = plt.subplots()
ax.plot('Time','Hardcover', data = df, color = '0.75')
ax = sns.regplot(x = 'Time', y='Hardcover', data= df, ci =None, scatter_kws = dict(color = '0.25'))
ax.set_title('Time Plot of Hardcover Sales')
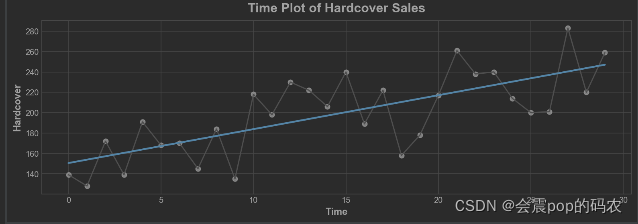
时间步长的特点让你对时间的依赖性进行建模。如果一个系列的数值可以从它们发生的时间来预测,那么它就是时间依赖的。在 "精装销售 "系列中,我们可以预测,本月晚些时候的销售量通常高于月初的销售量。
滞后特征
为了制造一个滞后特征,我们将目标序列的观测值进行移动,使它们看起来在时间上更晚发生。在这里,我们创建了一个1级的滞后特征,虽然也可以进行多级的移动。

这里我们可以看到lag_1那一列的数据将原先所有的Hardcover的那一列数据都后移了一天。
那么对于滞后特征的线性回归我们的回归方程就是这样的:
target = weight * lag + bias
因此,滞后特征让我们可以将曲线拟合到滞后图上,在滞后图上,一个系列的每个观测值都与前一个观测值相对应。

我们可以从滞后图中看到,某一天的销售额(Hardcover)与前一天的销售额(Lag_1)是相关的。当你看到这样的关系时,你就知道滞后特征将是有用的。
更一般地说,滞后特征可以让你建立序列依赖的模型。当一个观察值可以从以前的观察值中预测出来时,一个时间序列就具有序列依赖性。在Hardcover Sales中,我们可以预测某天的高销售额通常意味着第二天的高销售额。
版权声明
本文为[会震pop的码农]所创,转载请带上原文链接,感谢
https://blog.csdn.net/qq_51764183/article/details/124143985
边栏推荐
猜你喜欢

The website is linked to the gambling dark chain

6_ Data analysis modeling

Financial retail map - transaction flow warning map

队列第二篇
Mapbox creates multiple draggable marker points

Will the expired data of redis be deleted immediately?
软件测试的测试方法你知道多少?

SCI paper writing -- word template of IEEE Journal (also available in latex)

Keras deep learning practice (2) -- using keras to construct neural network
![[experience] Why does the IP address of HP printer start with 169.254](/img/e7/5068a565b57f066377fcb5754bc4bd.png)
[experience] Why does the IP address of HP printer start with 169.254
随机推荐
JVM tuning notes
CommDGI: Community detection oriented deep graph infomax 2020 CIKM
requires XXX>=YYY, but you‘ll have XXXX=ZZZ which is incompatible
15. Bufferevent client test connection server
goland汉化解决方法(下载插件失败的情况下)
pipeline communication
Sequence traversal of binary tree
仿真生成随机数计算生成每个同学生日
[concurrent programming 045] what is pseudo shared memory sequence conflict? How to avoid?
软件测试成行业“薪”贵?
链表第四篇
Queue II
MUI-弹出菜单
How much do you know about the testing methods of software testing?
Mapbox creates multiple draggable marker points
LeetCode 剑指 Offer 22. 链表中倒数第k个节点
Keras深度学习实战(2)——使用Keras构建神经网络
2022g2 boiler operator certificate examination question bank and online simulation examination
一文告诉你分析即服务(AaaS)到底是什么
LeetCode 剑指 Offer 15. 二进制中1的个数