当前位置:网站首页>YoloV4训练自己的数据集(三)
YoloV4训练自己的数据集(三)
2022-08-08 06:20:00 【开门大弟子】
上文已经测试GPU和OpenCV版本的YoloV4,本文主要介绍如何使用YoloV4建立自己的数据集并且把数据集转换为相应的格式。
1.建立数据集
如果你自己有数据集,可以直接跳过本部分。可以使用Labelimg对于自己的图片进行标注,关于Labelimg的安装,大家可以看这篇博客。标注之后会生成.xml文件,其中包含了图片路径、图片色彩通道、大小、标注框的大小。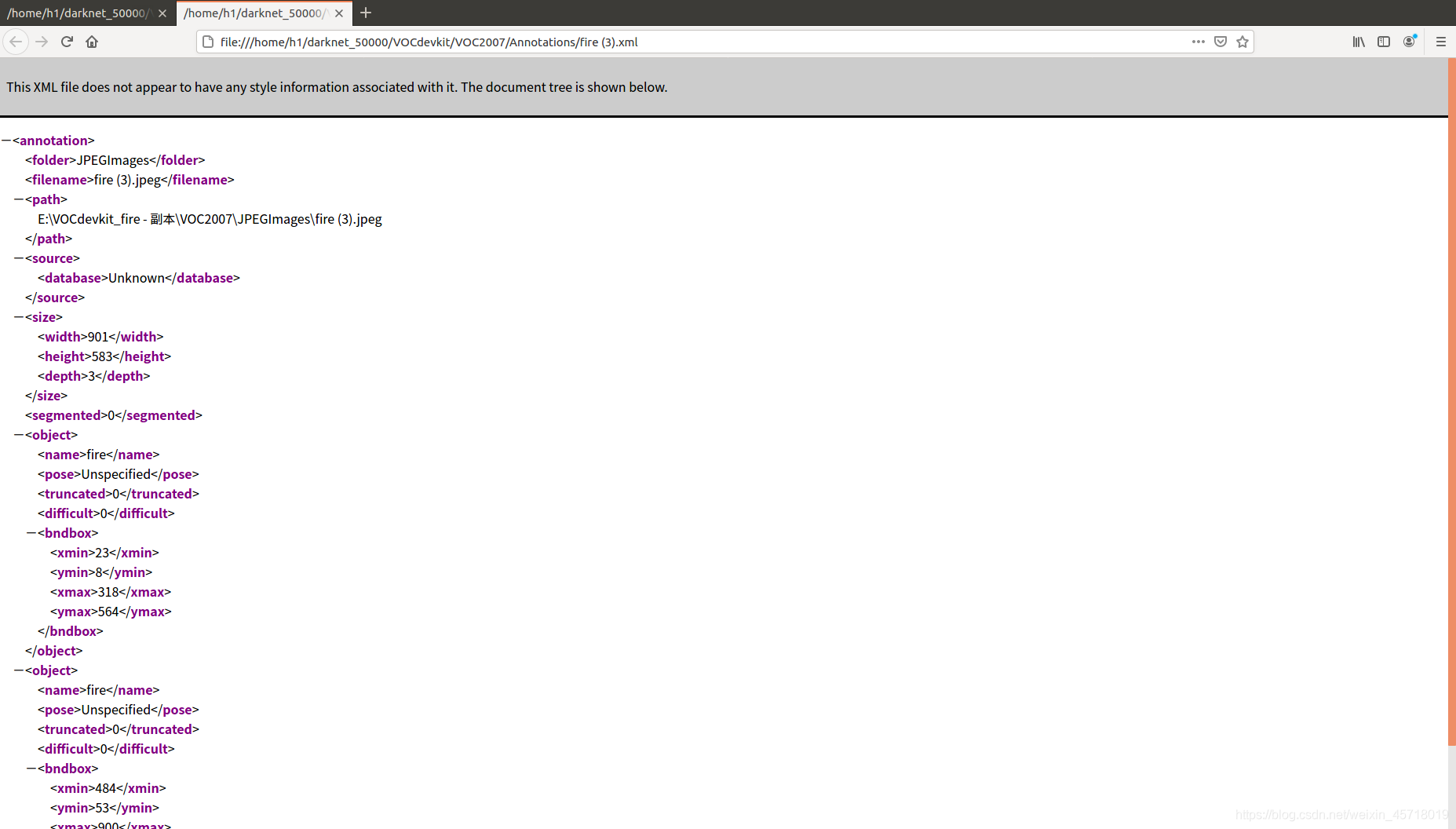
2.建立数据集格式
Yolo使用PASCAL VOC数据集的目录结构,其结构如下: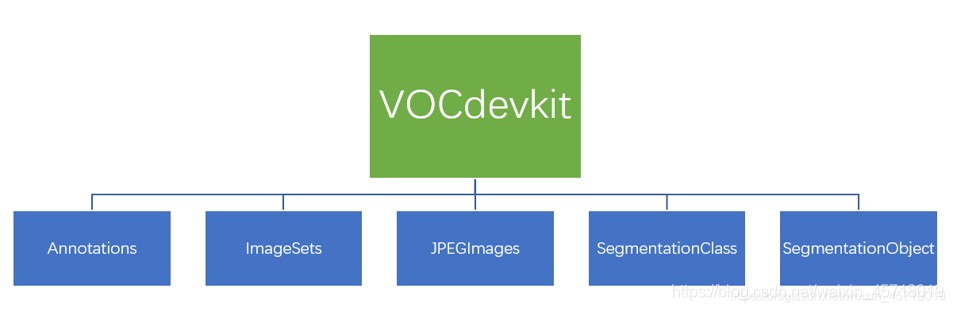

目标检测仅使用Annotations以及JPEGImagets这两个文件夹。
3.转换并且划分数据集
需要把标注的.xml文件转换为Yolo的txt文本并且把数据集划分为训练集和测试集。我使用的Python3,程序如下:只需要把其中的 classes改为自己的类别。如果是多类别注意用英文逗号隔开。
import xml.etree.ElementTree as ET
import pickle
import os
from os import listdir, getcwd
from os.path import join
import random
classes=["fire"]
def clear_hidden_files(path):
dir_list = os.listdir(path)
for i in dir_list:
abspath = os.path.join(os.path.abspath(path), i)
if os.path.isfile(abspath):
if i.startswith("._"):
os.remove(abspath)
else:
clear_hidden_files(abspath)
def convert(size, box):
dw = 1./size[0]
dh = 1./size[1]
x = (box[0] + box[1])/2.0
y = (box[2] + box[3])/2.0
w = box[1] - box[0]
h = box[3] - box[2]
x = x*dw
w = w*dw
y = y*dh
h = h*dh
return (x,y,w,h)
def convert_annotation(image_id):
in_file = open('VOCdevkit/VOC2007/Annotations/%s.xml' %image_id)
out_file = open('VOCdevkit/VOC2007/labels/%s.txt' %image_id, 'w')
tree=ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult) == 1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text), float(xmlbox.find('ymax').text))
bb = convert((w,h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
in_file.close()
out_file.close()
wd = os.getcwd()
wd = os.getcwd()
work_sapce_dir = os.path.join(wd, "VOCdevkit/")
if not os.path.isdir(work_sapce_dir):
os.mkdir(work_sapce_dir)
work_sapce_dir = os.path.join(work_sapce_dir, "VOC2007/")
if not os.path.isdir(work_sapce_dir):
os.mkdir(work_sapce_dir)
annotation_dir = os.path.join(work_sapce_dir, "Annotations/")
if not os.path.isdir(annotation_dir):
os.mkdir(annotation_dir)
clear_hidden_files(annotation_dir)
image_dir = os.path.join(work_sapce_dir, "JPEGImages/")
if not os.path.isdir(image_dir):
os.mkdir(image_dir)
clear_hidden_files(image_dir)
VOC_file_dir = os.path.join(work_sapce_dir, "ImageSets/")
if not os.path.isdir(VOC_file_dir):
os.mkdir(VOC_file_dir)
VOC_file_dir = os.path.join(VOC_file_dir, "Main/")
if not os.path.isdir(VOC_file_dir):
os.mkdir(VOC_file_dir)
train_file = open(os.path.join(wd, "2007_train.txt"), 'w')
test_file = open(os.path.join(wd, "2007_test.txt"), 'w')
train_file.close()
test_file.close()
VOC_train_file = open(os.path.join(work_sapce_dir, "ImageSets/Main/train.txt"), 'w')
VOC_test_file = open(os.path.join(work_sapce_dir, "ImageSets/Main/test.txt"), 'w')
VOC_train_file.close()
VOC_test_file.close()
if not os.path.exists('VOCdevkit/VOC2007/labels'):
os.makedirs('VOCdevkit/VOC2007/labels')
train_file = open(os.path.join(wd, "2007_train.txt"), 'a')
test_file = open(os.path.join(wd, "2007_test.txt"), 'a')
VOC_train_file = open(os.path.join(work_sapce_dir, "ImageSets/Main/train.txt"), 'a')
VOC_test_file = open(os.path.join(work_sapce_dir, "ImageSets/Main/test.txt"), 'a')
list = os.listdir(image_dir) # list image files
probo = random.randint(1, 100)
print("Probobility: %d" % probo)
for i in range(0,len(list)):
path = os.path.join(image_dir,list[i])
if os.path.isfile(path):
image_path = image_dir + list[i]
voc_path = list[i]
(nameWithoutExtention, extention) = os.path.splitext(os.path.basename(image_path))
(voc_nameWithoutExtention, voc_extention) = os.path.splitext(os.path.basename(voc_path))
annotation_name = nameWithoutExtention + '.xml'
annotation_path = os.path.join(annotation_dir, annotation_name)
probo = random.randint(1, 100)
print("Probobility: %d" % probo)
if(probo < 75):
if os.path.exists(annotation_path):
train_file.write(image_path + '\n')
VOC_train_file.write(voc_nameWithoutExtention + '\n')
convert_annotation(nameWithoutExtention)
else:
if os.path.exists(annotation_path):
test_file.write(image_path + '\n')
VOC_test_file.write(voc_nameWithoutExtention + '\n')
convert_annotation(nameWithoutExtention)
train_file.close()
test_file.close()
VOC_train_file.close()
VOC_test_file.close()
执行程序之后在darknet文件夹下会生成两个文件,分别是2007test.txt以及2007train.txt。(其中数据集中的75%划分为训练集,25%划分为测试集,这个划分可以自己修改。)
数据集的建立、转换与划分结束。下文介绍如何使用自己的数据集进行训练。
边栏推荐
猜你喜欢
The pta patching simple graph theory

卷积神经网络 图像识别,卷积神经网络 图像处理
神经网络一般训练多少次,神经网络训练时间过长

cnn convolutional neural network backpropagation, convolutional neural network dimension change

PostgreSQL中想新建一个用户,让他仅能访问指定数据表,不能通过客户端工具看到表结构和函数内容,是否有方案可解决?

Completed - desktop interactive wizard design based on facial expressions (share the results, attach the data set of facial expressions and the yolov5 model trained by yourself and the interactive int
神经网络解决哪些问题,神经网络结果不稳定
The amount of parameters and calculation of neural network, is the neural network a parametric model?

使用XGboost进行分类,判断该患者是否患有糖尿病

Redis In Action —— Advanced —— 数据主从同步原理 —— 全量同步 与 增量同步 工作流程及原理 —— 以及如何利用 docker 容器技术快速模拟单机 Redis 集群
随机推荐
验证的计划
手写哈希表
【图像处理】matlab基础图像处理 | 图像载入、图像添加噪声、图像滤波、图像卷积
【微信小程序】一文学懂小程序的数据绑定和事件绑定
数字IC设计中为什么要避免锁存器(Latches)
Introduction to uvm
flex布局缺点
刚学,这是怎么回事,SQL怎么转运错误啊
Promise的使用与async/await的使用
Basic tools - NETCAT (Telnet - banner, transfer text message)
逻辑回归 判断学生能否被大学录取
tkinter-TinUI-xml实战(7)PDF分页与合并
主脑提示( Master-Mind Hints )
Threads, control, communications
docker修改mysql配置文件
np.iinfo和 np.finfo的用法
The CAP theorem instance analysis
Rust学习:4_基本类型
快要“金九银十”了,你开始准备了吗?
Tidb cdc