当前位置:网站首页>MiniFlow -- 9.简单理解反向传播
MiniFlow -- 9.简单理解反向传播
2022-08-06 05:21:00 【xf8964】
我们先来实现sigmoid 类的backward 方法,这里先展示Layer的变化,Input和Linear的backpropagation 的工作方式
我们先看看Layer
class Layer:
def __init__(self, inbound_layers=[]):
# 本层的输入层列表
self.inbound_layers = inbound_layers
self.value = None
self.outbound_layers = []
# New property! Keys are the inputs to this layer and
# their values are the partials of this layer with
# respect to that input.
self.gradients = {
}
for layer in inbound_layers:
layer.outbound_layers.append(self)
def forward():
raise NotImplementedError
def backward():
raise NotImplementedError
可以发现,Layer添加了私有变量 self.gradients ,他是一个字典,如下
self.gradients = {
inbound_layer_n: partial_loss_with_respect_to_inbound_layer_n,
...
}
在反响传播的过程中,会设置 self.gradients 的值。我们会想到 backward()怎么起到作用。网络会利用每一层上的输入的梯度来更变权重和偏移
单个变量的更新公式可以写成
上面的公式里面w_i和b_i是网络里面一个层中单个权重和偏移,根据这个公式,w_i和b_i都是已知的,那个n样子的变量就是学习率,也是一个全局变量,所以,这里唯一不知道的是每一个变量相对于网络的损失,事实上,这个你会在后向传播的过程中得到
这个一段翻译不出原文意思,直接看原文
Here, w_i and b_i represent a single weight or bias of the weights or biases collection. Looking at these equations, both w_i and b_i are known ahead of time. η is effectively a global variable that you pass into the network. The only unknown is the partial of the network cost with respect to each variable. In fact, this is what you will find during backpropagation.
这里看看他在Linear里面是怎么工作的
class Linear(Layer):
def __init__(self, inbound_layer, weights, bias):
Layer.__init__(self, [inbound_layer, weights, bias])
def forward(self):
inputs = self.inbound_layers[0].value
weights = self.inbound_layers[1].value
bias = self.inbound_layers[2].value
self.value = np.dot(inputs, weights) + bias
def backward(self):
# Initialize a partial for each of the inbound_layers.
self.gradients = {
n: np.zeros_like(n.value) for n in self.inbound_layers}
# Cycle through the outputs. The gradient will change depending
# on each output.
for n in self.outbound_layers:
# Get the partial of the outbound layer with respect to this layer.
grad = n.gradients[self]
# Set the partial of the loss with respect to this layer's inputs.
self.gradients[self.inbound_layers[0]] += np.dot(grad, self.inbound_layers[1].value.T)
# Set the partial of the loss with respect to this layer's weights.
self.gradients[self.inbound_layers[1]] += np.dot(self.inbound_layers[0].value.T, grad)
# Set the partial of the loss with respect to this layer's bias.
self.gradients[self.inbound_layers[2]] += np.sum(grad, axis=0, keepdims=False)
让我们写下数学版本的代码的解决方式,然后温习一下

是不是觉得这里的T觉得很奇怪,在公式2中,X和W遵循行列式的规则,并遵循行列式的乘法规则,为什么到了下面的公式里面就出现了转置呢,我的理解是在实际是算过程中使用矩阵的广播计算更为方便,使用广播,让X和W拥有相同的列数,然后让X对W进行广播,结果为X的第一行和W的第一行相乘,作为结果的第一行第一列,用X的第一行和W的第二行相乘作为第一行第二列,一次类推,结果形状为,X的行数为结果的行数,WT的行(hang)数为结果的列数
我们将 Linear方法写成标量的表示方法
- X => mxn
- W => nxk
- z => mxk
- i =>m; j =>n; l=>k
m是X的批次,n是X的特征数,k是输出特征数量
上面的公式是X的行i和W的列j的点乘(dot product)
让我们看看Z关于X的偏导数计算,下面是标量计算
然后再来看看矩阵的计算
然后是通过矩阵计算损失C关于X的偏导数,
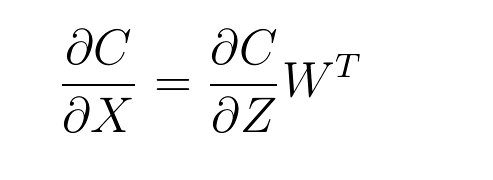
边栏推荐
- 说说转行
- 动手学深度学习PyTorch(四):多层感知机
- 指定变量和函数保存位置
- Discussion on Distributed Photovoltaic Grid-connected Power Generation in Expressway Service Area-Susie Week
- 通用信息抽取UIE论文笔记
- Acrel-3000WEB电能管理系统在都巴高速的应用-Susie 周
- pycharm使用anaconda下载的库
- [MM32] eMiniBoard's PWM drive passive buzzer + ADC to adjust LED brightness reference routine (on)
- ARM Cortex-M 调试
- MDK Debug prompts No ULINK/ME Device found after selecting JLINK
猜你喜欢









随机推荐
说说转行
【模块介绍】6×6矩阵键盘(硬件部分和扫描方式)
串口USART和UART
【STM32】【HAL库】【实用制作】数控收音机(软件设计)
【基础知识】SPI通信协议
Qt 使用ffmpeg库播放音视频
动手学深度学习PyTorch(四):多层感知机
PointNet和PointNet++论文解读
【MM32】PWM Sine Wave Modulation Audio - FDS Configuration of Timer
热修复、插件化、组件化的区别
[MM32] eMiniBoard's PWM drive passive buzzer + ADC to adjust LED brightness reference routine (on)
[MM32] eMiniBoard's PWM drive passive buzzer + ADC to adjust LED brightness reference routine (below)
读写数据的路径设置
VTK从vtkPolyData数据获取点的坐标
【转载】以太网自动协商原理
RESTful API简介及flask实现
STM32ADC
jupyter notebook 文件 无显示
VS报错合集(持续更新ing)
【模块介绍】WS2812(硬件部分)