当前位置:网站首页>Basic training process of image classification -- Based on mobilenet_ V3 as an example
Basic training process of image classification -- Based on mobilenet_ V3 as an example
2022-04-21 13:48:00 【Effort volume】
Experience summary from b standing up Lord ——7.2.2 Use Pytorch build MobileNetV3 And training based on transfer learning _ Bili, Bili _bilibili
1. use gpu still cpu To deal with
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")2. Define the method of data preprocessing
data_transform = {
"train": transforms.Compose([transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])]),
"val": transforms.Compose([transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])])}3. Define the dataset file directory
data_root = os.path.abspath(os.path.join(os.getcwd(), "../.."))
image_path = os.path.join(data_root, "data_set", "flower_data")
train_dataset = datasets.ImageFolder(root = os.path.join(image_path, "train"),
transform = data_transform["train"])4. Get data set class_to_idx After that, the key and key value are exchanged , Write file after exchange
train_num = len(train_dataset)
# {'daisy':0, 'dandelion':1, 'roses':2, 'sunflower':3, 'tulips':4}
flower_list = train_dataset.class_to_idx
cla_dict = dict((val, key) for key, val in flower_list.items())
# write dict into json file
json_str = json.dumps(cla_dict, indent=4)
with open('class_indices.json', 'w') as json_file:
json_file.write(json_str)5. Generate iterators
train_loader = torch.utils.data.DataLoader(train_dataset,
batch_size=batch_size, shuffle=True,
num_workers=0)
validate_dataset = datasets.ImageFolder(root=os.path.join(image_path, "val"),
transform=data_transform["val"])
val_num = len(validate_dataset)
validate_loader = torch.utils.data.DataLoader(validate_dataset,
batch_size=batch_size, shuffle=False,
num_workers=0)6. Instantiated neural networks
net = mobilenet_v3_large(num_classes=5)7. Read the pre training weight file and delete the classified weight
# load pretrain weights
# download url: https://download.pytorch.org/models/mobilenet_v2-b0353104.pth
model_weight_path = "./mobilenet_v3_large.pth"
assert os.path.exists(model_weight_path), "file {} dose not exist.".format(model_weight_path)
pre_weights = torch.load(model_weight_path, map_location=device)
# delete classifier weights
pre_dict = {k: v for k, v in pre_weights.items() if net.state_dict()[k].numel() == v.numel()}
missing_keys, unexpected_keys = net.load_state_dict(pre_dict, strict=False)8. Freeze some or all weights
# freeze features weights
for param in net.features.parameters():
param.requires_grad = False9. Define the loss function and optimizer
# define loss function
loss_function = nn.CrossEntropyLoss()
# construct an optimizer
params = [p for p in net.parameters() if p.requires_grad]
optimizer = optim.Adam(params, lr=0.0001)10. Start training
best_acc = 0.0
# Save training weight path
save_path = './MobileNetV3.pth'
train_steps = len(train_loader)
for epoch in range(epochs):
# train
net.train()
running_loss = 0.0
train_bar = tqdm(train_loader)
for step, data in enumerate(train_bar):
images, labels = data
optimizer.zero_grad()
logits = net(images.to(device))
loss = loss_function(logits, labels.to(device))
loss.backward()
optimizer.step()
# print statistics
running_loss += loss.item()
train_bar.desc = "train epoch[{}/{}] loss:{:.3f}".format(epoch + 1,
epochs,
loss)11. Verify and save the training weight file
# validate
net.eval()
acc = 0.0 # accumulate accurate number / epoch
with torch.no_grad():
val_bar = tqdm(validate_loader)
for val_data in val_bar:
val_images, val_labels = val_data
outputs = net(val_images.to(device))
# loss = loss_function(outputs, test_labels)
predict_y = torch.max(outputs, dim=1)[1]
acc += torch.eq(predict_y, val_labels.to(device)).sum().item()
val_bar.desc = "valid epoch[{}/{}]".format(epoch + 1,
epochs)
val_accurate = acc / val_num
print('[epoch %d] train_loss: %.3f val_accuracy: %.3f' %
(epoch + 1, running_loss / train_steps, val_accurate))
if val_accurate > best_acc:
best_acc = val_accurate
torch.save(net.state_dict(), save_path)
Attached separately MobileNet_v3 Network code
from typing import Callable, List, Optional
import torch
from torch import nn, Tensor
from torch.nn import functional as F
from functools import partial
def _make_divisible(ch, divisor=8, min_ch=None):
"""
This function is taken from the original tf repo.
It ensures that all layers have a channel number that is divisible by 8
It can be seen here:
https://github.com/tensorflow/models/blob/master/research/slim/nets/mobilenet/mobilenet.py
"""
if min_ch is None:
min_ch = divisor
new_ch = max(min_ch, int(ch + divisor / 2) // divisor * divisor)
# Make sure that round down does not go down by more than 10%.
if new_ch < 0.9 * ch:
new_ch += divisor
return new_ch
class ConvBNActivation(nn.Sequential):
def __init__(self,
in_planes: int,
out_planes: int,
kernel_size: int = 3,
stride: int = 1,
groups: int = 1,
norm_layer: Optional[Callable[..., nn.Module]] = None,
activation_layer: Optional[Callable[..., nn.Module]] = None):
padding = (kernel_size - 1) // 2
if norm_layer is None:
norm_layer = nn.BatchNorm2d
if activation_layer is None:
activation_layer = nn.ReLU6
super(ConvBNActivation, self).__init__(nn.Conv2d(in_channels=in_planes,
out_channels=out_planes,
kernel_size=kernel_size,
stride=stride,
padding=padding,
groups=groups,
bias=False),
norm_layer(out_planes),
activation_layer(inplace=True))
# Attention mechanism
class SqueezeExcitation(nn.Module):
def __init__(self, input_c: int, squeeze_factor: int = 4):
super(SqueezeExcitation, self).__init__()
squeeze_c = _make_divisible(input_c // squeeze_factor, 8)
self.fc1 = nn.Conv2d(input_c, squeeze_c, 1)
self.fc2 = nn.Conv2d(squeeze_c, input_c, 1)
def forward(self, x: Tensor) -> Tensor:
scale = F.adaptive_avg_pool2d(x, output_size=(1, 1))
scale = self.fc1(scale)
scale = F.relu(scale, inplace=True)
scale = self.fc2(scale)
scale = F.hardsigmoid(scale, inplace=True)
return scale * x
class InvertedResidualConfig:
def __init__(self,
input_c: int,
kernel: int,
expanded_c: int,
out_c: int,
use_se: bool,
activation: str,
stride: int,
width_multi: float):
self.input_c = self.adjust_channels(input_c, width_multi)
self.kernel = kernel
self.expanded_c = self.adjust_channels(expanded_c, width_multi)
self.out_c = self.adjust_channels(out_c, width_multi)
self.use_se = use_se
self.use_hs = activation == "HS" # whether using h-swish activation
self.stride = stride
@staticmethod
def adjust_channels(channels: int, width_multi: float):
return _make_divisible(channels * width_multi, 8)
class InvertedResidual(nn.Module):
def __init__(self,
cnf: InvertedResidualConfig,
norm_layer: Callable[..., nn.Module]):
super(InvertedResidual, self).__init__()
if cnf.stride not in [1, 2]:
raise ValueError("illegal stride value.")
self.use_res_connect = (cnf.stride == 1 and cnf.input_c == cnf.out_c)
layers: List[nn.Module] = []
activation_layer = nn.Hardswish if cnf.use_hs else nn.ReLU
# expand
if cnf.expanded_c != cnf.input_c:
layers.append(ConvBNActivation(cnf.input_c,
cnf.expanded_c,
kernel_size=1,
norm_layer=norm_layer,
activation_layer=activation_layer))
# depthwise
layers.append(ConvBNActivation(cnf.expanded_c,
cnf.expanded_c,
kernel_size=cnf.kernel,
stride=cnf.stride,
groups=cnf.expanded_c,
norm_layer=norm_layer,
activation_layer=activation_layer))
if cnf.use_se:
layers.append(SqueezeExcitation(cnf.expanded_c))
# project
layers.append(ConvBNActivation(cnf.expanded_c,
cnf.out_c,
kernel_size=1,
norm_layer=norm_layer,
activation_layer=nn.Identity))
self.block = nn.Sequential(*layers)
self.out_channels = cnf.out_c
self.is_strided = cnf.stride > 1
def forward(self, x: Tensor) -> Tensor:
result = self.block(x)
if self.use_res_connect:
result += x
return result
class MobileNetV3(nn.Module):
def __init__(self,
inverted_residual_setting: List[InvertedResidualConfig],
last_channel: int,
num_classes: int = 1000,
block: Optional[Callable[..., nn.Module]] = None,
norm_layer: Optional[Callable[..., nn.Module]] = None):
super(MobileNetV3, self).__init__()
if not inverted_residual_setting:
raise ValueError("The inverted_residual_setting should not be empty.")
elif not (isinstance(inverted_residual_setting, List) and
all([isinstance(s, InvertedResidualConfig) for s in inverted_residual_setting])):
raise TypeError("The inverted_residual_setting should be List[InvertedResidualConfig]")
if block is None:
block = InvertedResidual
if norm_layer is None:
norm_layer = partial(nn.BatchNorm2d, eps=0.001, momentum=0.01)
layers: List[nn.Module] = []
# building first layer
firstconv_output_c = inverted_residual_setting[0].input_c
layers.append(ConvBNActivation(3,
firstconv_output_c,
kernel_size=3,
stride=2,
norm_layer=norm_layer,
activation_layer=nn.Hardswish))
# building inverted residual blocks
for cnf in inverted_residual_setting:
layers.append(block(cnf, norm_layer))
# building last several layers
lastconv_input_c = inverted_residual_setting[-1].out_c
lastconv_output_c = 6 * lastconv_input_c
layers.append(ConvBNActivation(lastconv_input_c,
lastconv_output_c,
kernel_size=1,
norm_layer=norm_layer,
activation_layer=nn.Hardswish))
self.features = nn.Sequential(*layers)
self.avgpool = nn.AdaptiveAvgPool2d(1)
self.classifier = nn.Sequential(nn.Linear(lastconv_output_c, last_channel),
nn.Hardswish(inplace=True),
nn.Dropout(p=0.2, inplace=True),
nn.Linear(last_channel, num_classes))
# initial weights
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode="fan_out")
if m.bias is not None:
nn.init.zeros_(m.bias)
elif isinstance(m, (nn.BatchNorm2d, nn.GroupNorm)):
nn.init.ones_(m.weight)
nn.init.zeros_(m.bias)
elif isinstance(m, nn.Linear):
nn.init.normal_(m.weight, 0, 0.01)
nn.init.zeros_(m.bias)
def _forward_impl(self, x: Tensor) -> Tensor:
x = self.features(x)
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.classifier(x)
return x
def forward(self, x: Tensor) -> Tensor:
return self._forward_impl(x)
def mobilenet_v3_large(num_classes: int = 1000,
reduced_tail: bool = False) -> MobileNetV3:
"""
Constructs a large MobileNetV3 architecture from
"Searching for MobileNetV3" <https://arxiv.org/abs/1905.02244>.
weights_link:
https://download.pytorch.org/models/mobilenet_v3_large-8738ca79.pth
Args:
num_classes (int): number of classes
reduced_tail (bool): If True, reduces the channel counts of all feature layers
between C4 and C5 by 2. It is used to reduce the channel redundancy in the
backbone for Detection and Segmentation.
"""
width_multi = 1.0
bneck_conf = partial(InvertedResidualConfig, width_multi=width_multi)
adjust_channels = partial(InvertedResidualConfig.adjust_channels, width_multi=width_multi)
reduce_divider = 2 if reduced_tail else 1
inverted_residual_setting = [
# input_c, kernel, expanded_c, out_c, use_se, activation, stride
bneck_conf(16, 3, 16, 16, False, "RE", 1),
bneck_conf(16, 3, 64, 24, False, "RE", 2), # C1
bneck_conf(24, 3, 72, 24, False, "RE", 1),
bneck_conf(24, 5, 72, 40, True, "RE", 2), # C2
bneck_conf(40, 5, 120, 40, True, "RE", 1),
bneck_conf(40, 5, 120, 40, True, "RE", 1),
bneck_conf(40, 3, 240, 80, False, "HS", 2), # C3
bneck_conf(80, 3, 200, 80, False, "HS", 1),
bneck_conf(80, 3, 184, 80, False, "HS", 1),
bneck_conf(80, 3, 184, 80, False, "HS", 1),
bneck_conf(80, 3, 480, 112, True, "HS", 1),
bneck_conf(112, 3, 672, 112, True, "HS", 1),
bneck_conf(112, 5, 672, 160 // reduce_divider, True, "HS", 2), # C4
bneck_conf(160 // reduce_divider, 5, 960 // reduce_divider, 160 // reduce_divider, True, "HS", 1),
bneck_conf(160 // reduce_divider, 5, 960 // reduce_divider, 160 // reduce_divider, True, "HS", 1),
]
last_channel = adjust_channels(1280 // reduce_divider) # C5
return MobileNetV3(inverted_residual_setting=inverted_residual_setting,
last_channel=last_channel,
num_classes=num_classes)
def mobilenet_v3_small(num_classes: int = 1000,
reduced_tail: bool = False) -> MobileNetV3:
"""
Constructs a large MobileNetV3 architecture from
"Searching for MobileNetV3" <https://arxiv.org/abs/1905.02244>.
weights_link:
https://download.pytorch.org/models/mobilenet_v3_small-047dcff4.pth
Args:
num_classes (int): number of classes
reduced_tail (bool): If True, reduces the channel counts of all feature layers
between C4 and C5 by 2. It is used to reduce the channel redundancy in the
backbone for Detection and Segmentation.
"""
width_multi = 1.0
bneck_conf = partial(InvertedResidualConfig, width_multi=width_multi)
adjust_channels = partial(InvertedResidualConfig.adjust_channels, width_multi=width_multi)
reduce_divider = 2 if reduced_tail else 1
inverted_residual_setting = [
# input_c, kernel, expanded_c, out_c, use_se, activation, stride
bneck_conf(16, 3, 16, 16, True, "RE", 2), # C1
bneck_conf(16, 3, 72, 24, False, "RE", 2), # C2
bneck_conf(24, 3, 88, 24, False, "RE", 1),
bneck_conf(24, 5, 96, 40, True, "HS", 2), # C3
bneck_conf(40, 5, 240, 40, True, "HS", 1),
bneck_conf(40, 5, 240, 40, True, "HS", 1),
bneck_conf(40, 5, 120, 48, True, "HS", 1),
bneck_conf(48, 5, 144, 48, True, "HS", 1),
bneck_conf(48, 5, 288, 96 // reduce_divider, True, "HS", 2), # C4
bneck_conf(96 // reduce_divider, 5, 576 // reduce_divider, 96 // reduce_divider, True, "HS", 1),
bneck_conf(96 // reduce_divider, 5, 576 // reduce_divider, 96 // reduce_divider, True, "HS", 1)
]
last_channel = adjust_channels(1024 // reduce_divider) # C5
return MobileNetV3(inverted_residual_setting=inverted_residual_setting,
last_channel=last_channel,
num_classes=num_classes)
版权声明
本文为[Effort volume]所创,转载请带上原文链接,感谢
https://yzsam.com/2022/04/202204211347167074.html
边栏推荐
- EsgynDB 清理不一致对象
- Benchmark cell detection scheme based on violence matching threshold
- 过滤字符串只保留串中的字母字符 (10 分)请编写一个函数fun,函数的功能是:输入一个字符串,过滤此串,只保留串中的字母字符,并统计新生成串中包含的字母个数。
- 【栈和队列专题】—— 双队列模拟栈
- Access的BOM开发(3)BOM展开
- Use of hystrix
- 北京大学ACM Problems 1012:Maya Calendar
- BOM development of access (3) BOM expansion
- 定位子元素的结构伪类
- 北京大学ACM Problems 1008:Maya Calendar
猜你喜欢

Unittest单元测试(五)

【leetcode】144.二叉树的前序遍历
Markdown grammar and test
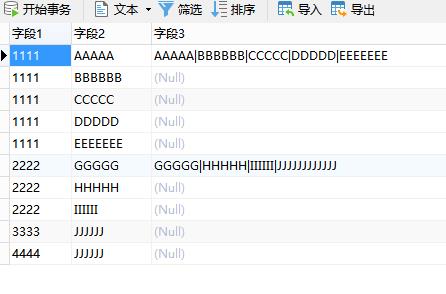
If the field lines are the same, they will be merged into another field SQL statement?
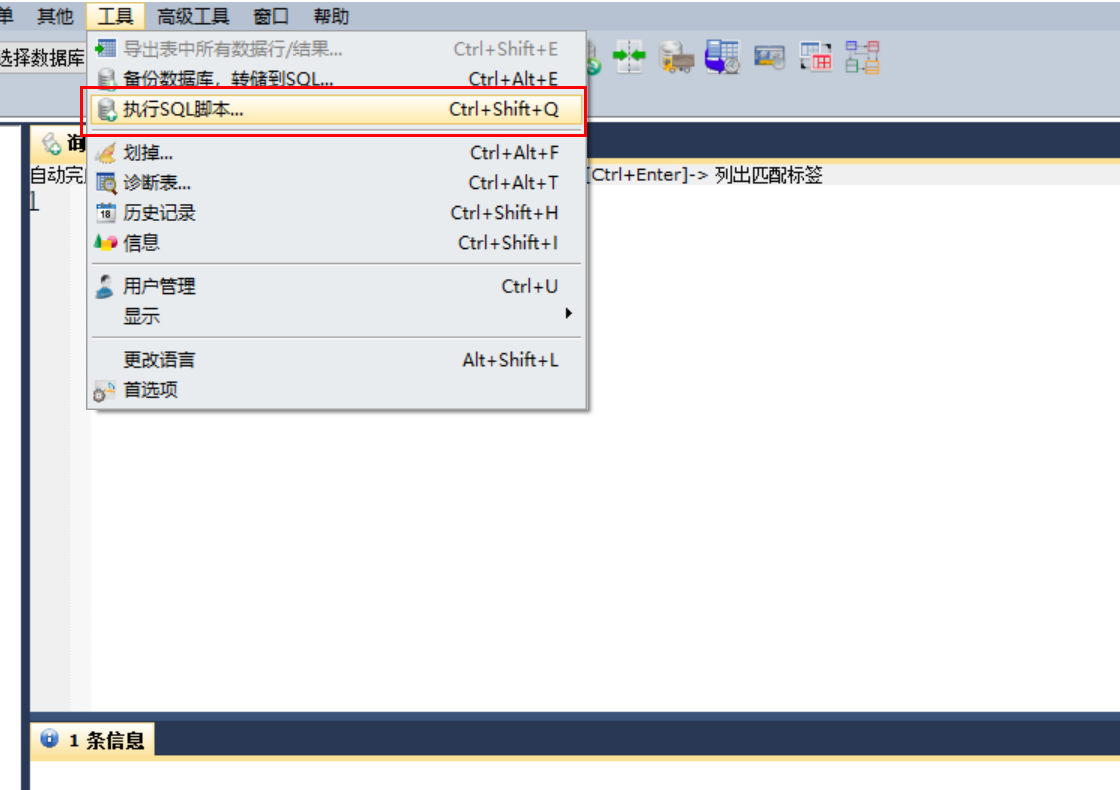
Sqlyog import SQL file
Forced to choose an outsourcing company

New technology is coming again, embrace agp7 0, are you ready to say goodbye to transform?

Exercise questions and answers of basic theories and relevant laws and regulations in 2022 supervision engineer examination

Réaliser l'affichage aléatoire de l'étiquette, de la taille de la police et de la couleur

mysql-三星索引和cost值成本计算
随机推荐
EsgynDB 关于带索引的DELETE性能提升
json-server的使用
String - 1 String length (10 points) the C language standard function library includes the strlen function, which is used to calculate the length of the string. As an exercise, we write a function wit
EsgynDB之TRIM函数
EsgynDB SQL统计模式下各对象个数
String - 1. Longueur de la chaîne (10 points) La Bibliothèque de fonctions standard du langage C comprend une fonction strlen qui calcule la longueur de la chaîne. Comme exercice, nous écrivons nous -
EsgynDB CQD-traf_lock_ddl
被迫选择了到了外包公司
字符串 - 1. 字符串長度 (10 分)C語言標准函數庫中包括 strlen 函數,用於計算字符串的長度。作為練習,我們自己編寫一個功能與之相同的函數。
Chapter 4 - hierarchical query of SQL query
Wechat hidden function series: wechat regular reminder, 2 steps, to relax yourself when you are busy
Work function of boost ASIO
软件工程-基础篇刷题
Number II that occurs only once (hash, bit operation, logic circuit, finite state automata)
Longest ascending subsequence (2) (greedy + dichotomy)
Number of effective triangles (double pointer (reverse scanning) + bisection)
并发编程之CAS和Atomic原子操作类
JVM內存分配機制詳解
国际物流集运系统源码,海外仓储跨境转运系统源码
Ali Tianchi competition -- street view character coding recognition