当前位置:网站首页>TPLinker: Single-stage Joint Extraction of Entities and Relations Through Token Pair Linking
TPLinker: Single-stage Joint Extraction of Entities and Relations Through Token Pair Linking
2022-08-08 06:24:00 【hithithithithit】
目录
写作动机(Movitation):
为了解决联合抽取中的暴露偏差的问题,首次提出了one-stage的解决方法。
相关工作(Related Work):
1.pipeline
a. 易发生级联错误(Li and Ji, 2014):
https://aclanthology.org/P14-1038.pdf https://aclanthology.org/P14-1038.pdf2. joint
https://aclanthology.org/P14-1038.pdf2. joint
a. 统一标记方案将联合抽取问题转换为序列标注问题,但是无法解决重叠关系(Zheng et al. (2017))。
Joint extraction of entities and relations based on a novel tagging schemehttps://arxiv.org/pdf/1706.05075.pdfEPO和SEO问题的解决方案:
a. decoder-based(Zeng et al., 2018; Nayak and Ng, 2020): 像机器翻译一样每次产生一个词或一个token。
Extracting relational facts by an end-to-end neural model with copy mechanismhttps://aclanthology.org/P18-1047.pdf
Effective modeling of encoder-decoder architecture for joint entity and relation extractionhttps://arxiv.org/abs/1911.09886v1 b. decomposition-based(Li et al., 2019; Yu et al., 2020; Wei et al., 2020):首先识别出句子中的主体,在识别出每个主体对应的客体和关系。
提出的方法(Methods):
将句子中的所有word进行组合,对词对之间的词头对应和词尾对应进行抽取的同时,对以上对应关系进行预测,并且抽取出实体内部的头尾映射,从而解决SEO和EPO以及暴露偏差的问题。如下图所示,我们需要做的任务分为一下三种:1.对于给定的关系R,判断词p1,p2是否使两个实体的第一个词;2.对于给定的关系R,判断词p1,p2是否使两个实体的最后一个词;3.对于同一个实体内的词,判断是否是同一个实体内的第一个词和最后一个词。
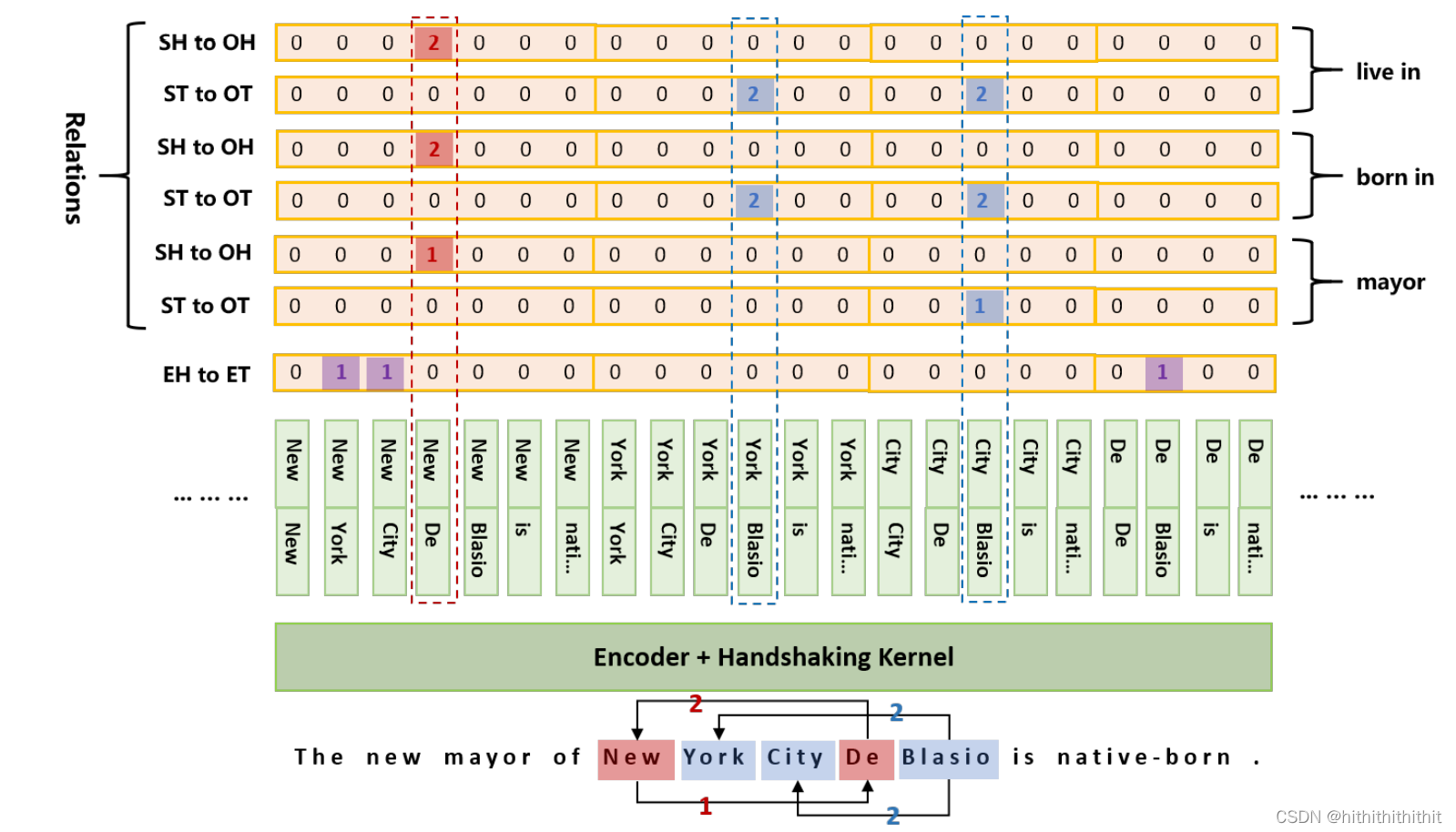
token-pair表示

Handshaking Tagger
 表示预测为关系
表示预测为关系  的概率。
的概率。
损失函数:
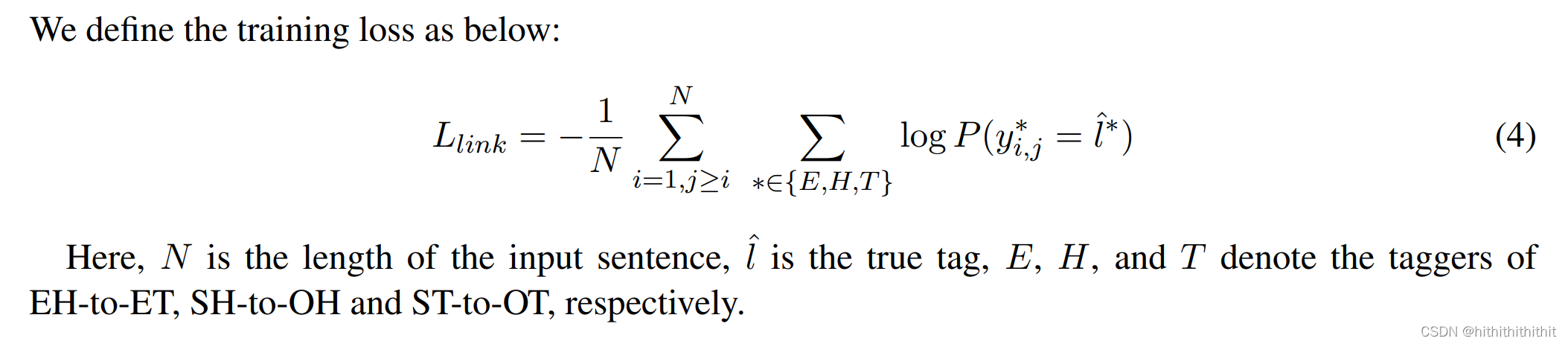
使用的技术(Techniques):
优化器:Adam
编码器:采用了两个编码器
1.300维的Glove向量,2层堆叠的BiLSTM,2层分别为300和600的隐藏层。
2.bert-base-uncased,
遇到的困难(Difficulties):
矩阵的稀疏性:

将矩阵转换为上三角矩阵,之后将转换后的矩阵展平为序列,并记住在原始矩阵中的位置信息。
SEO问题和嵌入式NER问题:
图2左边已经表明本方法可以解决单实体关系重复问题和嵌入式命名实体识别问题。
EPO问题:
我们对每一种关系都进行判断这样就可以解决实体对之间多关系类型的问题了。
实验结果(Results):
语料:

实验结果:

计算速度对比:

做出的贡献(Contributions):
1.提出了one-stage的新范式来解决联合抽取在训练阶段和推理阶段标签不一致可能导致错误累积的问题;
2.提出了有效解决SEO(multiple relations)、EPO(overlapping relations)、nested NER问题的方法;
未来展望(Future Work):
将任务泛化到nestedNER和EE等信息抽取任务中。
边栏推荐
猜你喜欢
![[WUSTCTF2020]CV Maker1](/img/be/989b1ea8597f31f4b82c2edc6345d5.png)
[WUSTCTF2020]CV Maker1
[WUSTCTF2020]CV Maker1
![[BSidesCF 2020] Had a bad day1](/img/18/872d1c4a87608c618d2add0a65c4ba.png)
[BSidesCF 2020] Had a bad day1

Mybaits笔记

行业调研:2022年养老保险市场现状及前景分析

RCNN目标检测原文理解
Detailed explanation of Scrapy crawler framework - comprehensive detailed explanation

Plant spice market research: China's market development status and business model analysis in 2022
Learning How to Ask: Querying LMs with Mixtures of Soft Prompts

玫瑰精油市场研究:目前市场产值超过23亿元,市场需求缺口约10%
随机推荐
四. Redis 事务、锁机制秒杀
Chemical Industry Research: Current Situation and Scale Analysis of Organic Silica Gel Market
总结:numpy常用方法
玫瑰精油市场研究:目前市场产值超过23亿元,市场需求缺口约10%
Google Colab 快速上手
1.Mysql索引的原理
1. TF2 Common Commands
ACM latex
消费品行业报告:椰子油市场现状研究分析与发展前景预测
3.多线程两种实现方式的区别
MongoDB自带的监控工具mongostat与mongotop
Map和Set
食品行业报告:辣椒市场现状研究分析与发展前景预测
Mysql(四)
Scrapy_Redis 分布式处理
Research analysis and development prospect forecast of electric shaver market status
逻辑回归推导
Market research report - the food additive industry output of 9.74 million tons
hyperledger-fabric documention official documentation
Industry Research: Analysis of the Status and Prospects of the Pension Insurance Market in 2022