当前位置:网站首页>Reinforcement learning (practice): feedback, AC
Reinforcement learning (practice): feedback, AC
2022-04-22 22:33:00 【Yan Shuangying】
1,REINFORCE
In the pole environment REINFORCE Experiment of algorithm :
import gym import torch import torch.nn.functional as F import numpy as np import matplotlib.pyplot as plt from tqdm import tqdm import rl_utilsFirst, define the policy network
PolicyNet, Its input is a state , The output is the action probability distribution in this state , Here, we use the method of... In the discrete action spacesoftmax()Function to realize a learnable multinomial distribution .class PolicyNet(torch.nn.Module): def __init__(self, state_dim, hidden_dim, action_dim): super(PolicyNet, self).__init__() self.fc1 = torch.nn.Linear(state_dim, hidden_dim) self.fc2 = torch.nn.Linear(hidden_dim, action_dim) def forward(self, x): x = F.relu(self.fc1(x)) return F.softmax(self.fc2(x), dim=1)Define our REINFORCE Algorithm . In function
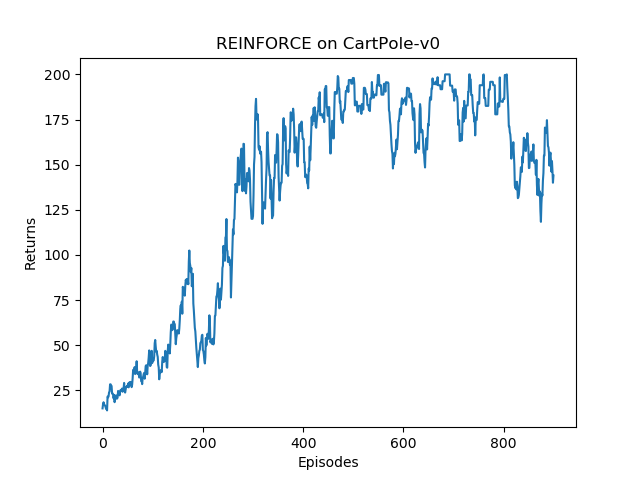
take_action()Function , We sample discrete actions through action probability distribution . During the update process , According to the algorithm, we write the loss function as the negative number of strategic return , namely , After the derivation, the strategy can be updated by gradient descent .class REINFORCE: def __init__(self, state_dim, hidden_dim, action_dim, learning_rate, gamma, device): self.policy_net = PolicyNet(state_dim, hidden_dim,action_dim).to(device) self.optimizer = torch.optim.Adam(self.policy_net.parameters(),lr=learning_rate) # Use Adam Optimizer self.gamma = gamma # The discount factor self.device = device def take_action(self, state): # Random sampling according to the action probability distribution state = torch.tensor([state], dtype=torch.float).to(self.device) probs = self.policy_net(state) action_dist = torch.distributions.Categorical(probs) action = action_dist.sample() return action.item() def update(self, transition_dict): reward_list = transition_dict['rewards'] state_list = transition_dict['states'] action_list = transition_dict['actions'] G = 0 self.optimizer.zero_grad() for i in reversed(range(len(reward_list))): # From the last step reward = reward_list[i] state = torch.tensor([state_list[i]],dtype=torch.float).to(self.device) action = torch.tensor([action_list[i]]).view(-1, 1).to(self.device) log_prob = torch.log(self.policy_net(state).gather(1, action)) G = self.gamma * G + reward loss = -log_prob * G # The loss function of each step loss.backward() # Back propagation calculation gradient self.optimizer.step() # gradient descentlearning_rate = 1e-3 num_episodes = 1000 hidden_dim = 128 gamma = 0.98 device = torch.device("cuda") if torch.cuda.is_available() else torch.device("cpu") env_name = "CartPole-v0" env = gym.make(env_name) env.seed(0) torch.manual_seed(0) state_dim = env.observation_space.shape[0] action_dim = env.action_space.n agent = REINFORCE(state_dim, hidden_dim, action_dim, learning_rate, gamma,device) return_list = [] for i in range(10): with tqdm(total=int(num_episodes / 10), desc='Iteration %d' % i) as pbar: for i_episode in range(int(num_episodes / 10)): episode_return = 0 transition_dict = { 'states': [], 'actions': [], 'next_states': [], 'rewards': [], 'dones': [] } state = env.reset() env.render() done = False while not done: action = agent.take_action(state) next_state, reward, done, _ = env.step(action) transition_dict['states'].append(state) transition_dict['actions'].append(action) transition_dict['next_states'].append(next_state) transition_dict['rewards'].append(reward) transition_dict['dones'].append(done) state = next_state episode_return += reward return_list.append(episode_return) agent.update(transition_dict) if (i_episode + 1) % 10 == 0: pbar.set_postfix({ 'episode': '%d' % (num_episodes / 10 * i + i_episode + 1), 'return': '%.3f' % np.mean(return_list[-10:]) }) pbar.update(1)stay CartPole-v0 Environment , The full score is 200 branch , We found that REINFORCE The algorithm works well , You can achieve 200 branch . Next, we draw the return change diagram of each track in the training process . Because the return jitter is relatively large , Often smooth .
episodes_list = list(range(len(return_list))) plt.plot(episodes_list, return_list) plt.xlabel('Episodes') plt.ylabel('Returns') plt.title('REINFORCE on {}'.format(env_name)) plt.show() mv_return = rl_utils.moving_average(return_list, 9) plt.plot(episodes_list, mv_return) plt.xlabel('Episodes') plt.ylabel('Returns') plt.title('REINFORCE on {}'.format(env_name)) plt.show()You can see , As more and more tracks are collected ,REINFORCE The algorithm effectively learns the optimal strategy . however , Compared to the previous DQN Algorithm ,REINFORCE The algorithm uses more sequences , This is because REINFORCE The algorithm is an online strategy algorithm , Previously collected trajectory data will not be reused . Besides ,REINFORCE The performance of the algorithm also fluctuates to a certain extent , This is mainly because the return value of each sampling track fluctuates greatly , This is also REINFORCE The main shortcomings of the algorithm .
2,Actor-Critic Algorithm
Still in Cartpole On the environment Actor-Critic Experiment of algorithm .
import gym import torch import torch.nn.functional as F import numpy as np import matplotlib.pyplot as plt import rl_utilsDefine our strategic network PolicyNet, And REINFORCE The algorithm is the same .
class PolicyNet(torch.nn.Module): def __init__(self, state_dim, hidden_dim, action_dim): super(PolicyNet, self).__init__() self.fc1 = torch.nn.Linear(state_dim, hidden_dim) self.fc2 = torch.nn.Linear(hidden_dim, action_dim) def forward(self, x): x = F.relu(self.fc1(x)) return F.softmax(self.fc2(x),dim=1)Actor-Critic An additional value network is introduced into the algorithm , The following code defines our value network ValueNet, The input is the State , The value of the output state .
class ValueNet(torch.nn.Module): def __init__(self, state_dim, hidden_dim): super(ValueNet, self).__init__() self.fc1 = torch.nn.Linear(state_dim, hidden_dim) self.fc2 = torch.nn.Linear(hidden_dim, 1) def forward(self, x): x = F.relu(self.fc1(x)) return self.fc2(x)Define our ActorCritic Algorithm . It mainly includes two functions: taking action and updating network parameters .
class ActorCritic: def __init__(self, state_dim, hidden_dim, action_dim, actor_lr, critic_lr, gamma, device): self.actor = PolicyNet(state_dim, hidden_dim, action_dim).to(device) self.critic = ValueNet(state_dim, hidden_dim).to(device) # Value network self.actor_optimizer = torch.optim.Adam(self.actor.parameters(), lr=actor_lr) self.critic_optimizer = torch.optim.Adam(self.critic.parameters(), lr=critic_lr) # Value network optimizer self.gamma = gamma def take_action(self, state): state = torch.tensor([state], dtype=torch.float) probs = self.actor(state) action_dist = torch.distributions.Categorical(probs) action = action_dist.sample() return action.item() def update(self, transition_dict): states = torch.tensor(transition_dict['states'], dtype=torch.float) actions = torch.tensor(transition_dict['actions']).view(-1, 1) rewards = torch.tensor(transition_dict['rewards'], dtype=torch.float).view(-1, 1) next_states = torch.tensor(transition_dict['next_states'], dtype=torch.float) dones = torch.tensor(transition_dict['dones'], dtype=torch.float).view(-1, 1) td_target = rewards + self.gamma * self.critic(next_states) * (1 - dones) # Timing difference target td_delta = td_target - self.critic(states) # Timing difference error log_probs = torch.log(self.actor(states).gather(1, actions)) actor_loss = torch.mean(-log_probs * td_delta.detach()) critic_loss = torch.mean(F.mse_loss(self.critic(states), td_target.detach())) # Mean square error loss function self.actor_optimizer.zero_grad() self.critic_optimizer.zero_grad() actor_loss.backward() # Calculate the gradient of the policy network critic_loss.backward() # Calculate the gradient of the value network self.actor_optimizer.step() # Update policy network parameters self.critic_optimizer.step() # Update value network parameters
According to the experimental results, we found that ,Actor-Critic The algorithm can quickly converge to the optimal strategy , And the training process is very stable , Compared with jitter REINFORCE The algorithm has been significantly improved , Thanks to the introduction of value function, the variance is reduced .

版权声明
本文为[Yan Shuangying]所创,转载请带上原文链接,感谢
https://yzsam.com/2022/04/202204222141349718.html
边栏推荐
- What are the functional problems of UI testing?
- Buffer of Muduo source code analysis
- Metawork: please, this remote pairing programming is cool!
- 略谈企业信息化的规律
- 7. 堪比JMeter的.Net压测工具 - Crank 总结篇 - crank带来了什么
- Text processing mode out of bootrap box
- 系列解读 SMC-R (二):融合 TCP 与 RDMA 的 SMC-R 通信 | 龙蜥技术
- Weekly Q & A highlights: is polardb-x fully compatible with MySQL?
- pcba/ IPQ6010 802.11ax 2x2 2.4G&5G /2.5Gbps Ethernet Port
- TCP/IP 协议及网络分层模型
猜你喜欢

智能名片小程序名片详情页功能实现关键代码

CrashSight 常规功能&特色功能介绍

OPLG:新一代云原生可观测最佳实践
为什么BI对企业这么重要?
【4.1】flink窗口算子的trigger触发器和Evictor清理器
Resource packaging dependency tree

优麒麟 22.04 LTS 版本正式发布 | UKUI 3.1开启全新体验!

Listing on the Shanghai Stock Exchange of CNOOC: market value of 6.515 billion and annual profit of 70.3 billion

Ivorysql unveiled at postgresconf SV 2022 Silicon Valley Postgres Conference

MetaWork:拜托,这样远程结对编程超酷的!
随机推荐
They are all intelligent in the whole house. What's the difference between aqara and homekit?
报名开启|QKE 容器引擎托管版暨容器生态发布会!
Tcp/ip protocol and network layered model
TS classic type gymnastics: how to turn the joint type into the cross type? We need to know three points: distribution law, inversion position, inversion and covariance
Web测试需要注意什么?
Leetcode 04 Median of Two Sorted Arrays
Yapi本地部署
The accuracy of this gyroscope is too high. It is recommended to prohibit its use.
JD side: how can a child thread get the value of the parent thread ThreadLocal? I got...
科创人·派拉软件CEO谭翔:零信任本质是数字安全,To B也要深研用户心智
Transport layer - connectionless transport: UDP (2)
PHP wechat refund certificate
ES6 transforms two-dimensional and multi-dimensional arrays into one-dimensional arrays
Series interpretation of smc-r (II): smc-r communication technology integrating TCP and RDMA
Weekly Q & A highlights: is polardb-x fully compatible with MySQL?
R language uses rjags and r2jags to establish Bayesian model
SSM框架
近期BSN开发常见问题答疑
Which is the most suitable educational financial product?
Reference policy example explanation