当前位置:网站首页>yolov5 口罩检测flask部署
yolov5 口罩检测flask部署
2022-04-22 09:22:00 【Sink Arsenic】
- 这个报错不知道怎么解决,网上查了解决方案加 import matplotlib 和 matplotlib.use(‘Agg’) 还是没用。不过只是关闭界面才出现的,应该不影响使用。
OSError: [Errno 41] Protocol wrong type for socket
Assertion failed: (NSViewIsCurrentlyBuildingLayerTreeForDisplay() != currentlyBuildingLayerTree), function NSViewSetCurrentlyBuildingLayerTreeForDisplay, file /System/Volumes/Data/SWE/macOS/BuildRoots/e90674e518/Library/Caches/com.apple.xbs/Sources/AppKit/AppKit-2022.50.114/AppKit.subproj/NSView.m, line 13412.
Process finished with exit code 132 (interrupted by signal 4: SIGILL)
参考资料
阿里云Ubuntu 部署
github flask yolov3 部署
flask 在浏览器中播放rtsp实时流
只能调用电脑摄像头
from flask import Flask, render_template, Response
import argparse
from pathlib import Path
import os
import cv2
import torch
import torch.backends.cudnn as cudnn
from numpy import random
import numpy as np
import sys
from models.common import DetectMultiBackend
from utils.datasets import IMG_FORMATS, VID_FORMATS, LoadImages, LoadStreams
from utils.general import (LOGGER, check_file, check_img_size, check_imshow, check_requirements, colorstr,
increment_path, non_max_suppression, print_args, scale_coords, strip_optimizer, xyxy2xywh)
from utils.plots import Annotator, colors, save_one_box
from utils.torch_utils import select_device, time_sync
''' ***模型初始化*** '''
@torch.no_grad()
def model_load(weights="/Users/sinkarsenic/Downloads/mask_detect/权重/best.pt", # model.pt path(s)
device='cpu', # cuda device, i.e. 0 or 0,1,2,3 or cpu
half=False, # use FP16 half-precision inference
dnn=False, # use OpenCV DNN for ONNX inference
):
device = select_device(device)
half &= device.type != 'cpu' # half precision only supported on CUDA
device = select_device(device)
model = DetectMultiBackend(weights, device=device, dnn=dnn)
stride, names, pt, jit, onnx = model.stride, model.names, model.pt, model.jit, model.onnx
# Half
half &= pt and device.type != 'cpu' # half precision only supported by PyTorch on CUDA
if pt:
model.model.half() if half else model.model.float()
print("模型加载完成!")
return model
app = Flask(__name__, static_url_path='',
static_folder='static',
template_folder='templates')
@app.route('/')
def index():
return render_template('index.html')
def gen():
model = model_load()
device = select_device('cpu')
imgsz = [640, 640] # inference size (pixels)
conf_thres = 0.25 # confidence threshold
iou_thres = 0.45 # NMS IOU threshold
max_det = 1000 # maximum detections per image
view_img = False # show results
save_txt = False # save results to *.txt
save_conf = False # save confidences in --save-txt labels
save_crop = False # save cropped prediction boxes
nosave = False # do not save images/videos
classes = None # filter by class: --class 0, or --class 0 2 3
agnostic_nms = False # class-agnostic NMS
augment = False # ugmented inference
visualize = False # visualize features
line_thickness = 3 # bounding box thickness (pixels)
hide_labels = False # hide labels
hide_conf = False # hide confidences
half = False # use FP16 half-precision inference
dnn = False # use OpenCV DNN for ONNX inference
source = str(0)
webcam = True
stride, names, pt, jit, onnx = model.stride, model.names, model.pt, model.jit, model.onnx
imgsz = check_img_size(imgsz, s=stride) # check image size
save_img = not nosave and not source.endswith('.txt') # save inference images
# Dataloader
if webcam:
view_img = check_imshow()
cudnn.benchmark = True # set True to speed up constant image size inference
dataset = LoadStreams(source, img_size=imgsz, stride=stride, auto=pt and not jit)
bs = len(dataset) # batch_size
else:
dataset = LoadImages(source, img_size=imgsz, stride=stride, auto=pt and not jit)
bs = 1 # batch_size
vid_path, vid_writer = [None] * bs, [None] * bs
# Run inference
if pt and device.type != "cpu":
model(torch.zeros(1, 3, *imgsz).to(device).type_as(next(model.model.parameters()))) # warmup
dt, seen = [0.0, 0.0, 0.0], 0
for path, im, im0s, vid_cap, s in dataset:
t1 = time_sync()
im = torch.from_numpy(im).to(device)
im = im.half() if half else im.float() # uint8 to fp16/32
im /= 255 # 0 - 255 to 0.0 - 1.0
if len(im.shape) == 3:
im = im[None] # expand for batch dim
t2 = time_sync()
dt[0] += t2 - t1
# Inference
# visualize = increment_path(save_dir / Path(path).stem, mkdir=True) if visualize else False
pred = model(im, augment=augment, visualize=visualize)
t3 = time_sync()
dt[1] += t3 - t2
# NMS
pred = non_max_suppression(pred, conf_thres, iou_thres, classes, agnostic_nms, max_det=max_det)
dt[2] += time_sync() - t3
# Second-stage classifier (optional)
# pred = utils.general.apply_classifier(pred, classifier_model, im, im0s)
# Process predictions
for i, det in enumerate(pred): # per image
seen += 1
if webcam: # batch_size >= 1
p, im0, frame = path[i], im0s[i].copy(), dataset.count
s += f'{
i}: '
else:
p, im0, frame = path, im0s.copy(), getattr(dataset, 'frame', 0)
p = Path(p) # to Path
# save_path = str(save_dir / p.name) # im.jpg
# txt_path = str(save_dir / 'labels' / p.stem) + (
# '' if dataset.mode == 'image' else f'_{frame}') # im.txt
s += '%gx%g ' % im.shape[2:] # print string
gn = torch.tensor(im0.shape)[[1, 0, 1, 0]] # normalization gain whwh
imc = im0.copy() if save_crop else im0 # for save_crop
annotator = Annotator(im0, line_width=line_thickness, example=str(names))
if len(det):
# Rescale boxes from img_size to im0 size
det[:, :4] = scale_coords(im.shape[2:], det[:, :4], im0.shape).round()
# Print results
for c in det[:, -1].unique():
n = (det[:, -1] == c).sum() # detections per class
s += f"{
n} {
names[int(c)]}{
's' * (n > 1)}, " # add to string
# Write results
for *xyxy, conf, cls in reversed(det):
if save_txt: # Write to file
xywh = (xyxy2xywh(torch.tensor(xyxy).view(1, 4)) / gn).view(
-1).tolist() # normalized xywh
line = (cls, *xywh, conf) if save_conf else (cls, *xywh) # label format
# with open(txt_path + '.txt', 'a') as f:
# f.write(('%g ' * len(line)).rstrip() % line + '\n')
if save_img or save_crop or view_img: # Add bbox to image
c = int(cls) # integer class
label = None if hide_labels else (names[c] if hide_conf else f'{
names[c]} {
conf:.2f}')
annotator.box_label(xyxy, label, color=colors(c, True))
# if save_crop:
# save_one_box(xyxy, imc, file=save_dir / 'crops' / names[c] / f'{p.stem}.jpg',
# BGR=True)
# Print time (inference-only)
LOGGER.info(f'{
s}Done. ({
t3 - t2:.3f}s)')
# Stream results
im0 = annotator.result()
if view_img:
cv2.imshow(str(p), im0)
cv2.waitKey(1) # 1 millisecond
cv2.imwrite('frame.jpg', im0)
yield (b'--frame\r\n'
b'Content-Type: image/jpeg\r\n\r\n' + open('frame.jpg', 'rb').read() + b'\r\n')
# String results
print(s)
# wait key to break
if cv2.waitKey(1) & 0xFF == ord('q'):
break
@app.route('/video_feed')
def video_feed():
return Response(gen(),
mimetype='multipart/x-mixed-replace; boundary=frame')
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('--weights', nargs='+', type=str, default='/Users/sinkarsenic/Downloads/mask_detect/权重/best.pt', help='model.pt path(s)')
parser.add_argument('--source', type=str, default='0', help='source') # file/folder, 0 for webcam
parser.add_argument('--img-size', type=int, default=640, help='inference size (pixels)')
parser.add_argument('--conf-thres', type=float, default=0.15, help='object confidence threshold')
parser.add_argument('--iou-thres', type=float, default=0.45, help='IOU threshold for NMS')
parser.add_argument('--device', default='', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
parser.add_argument('--classes', nargs='+', type=int, help='filter by class: --class 0, or --class 0 2 3')
parser.add_argument('--agnostic-nms', action='store_true', help='class-agnostic NMS')
parser.add_argument('--augment', action='store_true', help='augmented inference')
parser.add_argument('--update', action='store_true', help='update all models')
parser.add_argument('--project', default='runs/detect', help='save results to project/name')
parser.add_argument('--name', default='exp', help='save results to project/name')
parser.add_argument('--exist-ok', action='store_true', help='existing project/name ok, do not increment')
parser.add_argument('--frame-rate', default=0, type=int, help='sample rate')
opt = parser.parse_args()
app.run(debug=True)
使用 rstp 推流
用的是伊拉克电视台的
from flask import Flask, render_template, Response
import argparse
from pathlib import Path
import os
import cv2
import torch
import torch.backends.cudnn as cudnn
from numpy import random
import numpy as np
import sys
from models.common import DetectMultiBackend
from utils.datasets import IMG_FORMATS, VID_FORMATS, LoadImages, LoadStreams
from utils.general import (LOGGER, check_file, check_img_size, check_imshow, check_requirements, colorstr,
increment_path, non_max_suppression, print_args, scale_coords, strip_optimizer, xyxy2xywh)
from utils.plots import Annotator, colors, save_one_box
from utils.torch_utils import select_device, time_sync
''' ***模型初始化*** '''
@torch.no_grad()
def model_load(weights="/Users/sinkarsenic/Downloads/mask_detect/权重/best.pt", # model.pt path(s)
device='cpu', # cuda device, i.e. 0 or 0,1,2,3 or cpu
half=False, # use FP16 half-precision inference
dnn=False, # use OpenCV DNN for ONNX inference
):
device = select_device(device)
half &= device.type != 'cpu' # half precision only supported on CUDA
device = select_device(device)
model = DetectMultiBackend(weights, device=device, dnn=dnn)
stride, names, pt, jit, onnx = model.stride, model.names, model.pt, model.jit, model.onnx
# Half
half &= pt and device.type != 'cpu' # half precision only supported by PyTorch on CUDA
if pt:
model.model.half() if half else model.model.float()
print("模型加载完成!")
return model
app = Flask(__name__, static_url_path='',
static_folder='static',
template_folder='templates')
@app.route('/')
def index():
return render_template('index.html')
def gen():
model = model_load()
sourse = "rtmp://ns8.indexforce.com/home/mystream"
device = select_device('cpu')
imgsz = [640, 640] # inference size (pixels)
conf_thres = 0.25 # confidence threshold
iou_thres = 0.45 # NMS IOU threshold
max_det = 1000 # maximum detections per image
view_img = False # show results
save_txt = False # save results to *.txt
save_conf = False # save confidences in --save-txt labels
save_crop = False # save cropped prediction boxes
nosave = True # do not save images/videos
classes = None # filter by class: --class 0, or --class 0 2 3
agnostic_nms = False # class-agnostic NMS
augment = False # ugmented inference
visualize = False # visualize features
line_thickness = 3 # bounding box thickness (pixels)
hide_labels = False # hide labels
hide_conf = False # hide confidences
half = False # use FP16 half-precision inference
dnn = False # use OpenCV DNN for ONNX inference
source = str(sourse)
#webcam = False
stride, names, pt, jit, onnx = model.stride, model.names, model.pt, model.jit, model.onnx
imgsz = check_img_size(imgsz, s=stride) # check image size
save_img = not nosave and not source.endswith('.txt') # save inference images
is_file = Path(source).suffix[1:] in (IMG_FORMATS + VID_FORMATS)
is_url = source.lower().startswith(('rtsp://', 'rtmp://', 'http://', 'https://'))
webcam = source.isnumeric() or source.endswith('.txt') or (is_url and not is_file)
if is_url and is_file:
source = check_file(source) # download
# Dataloader
if webcam:
view_img = check_imshow()
cudnn.benchmark = True # set True to speed up constant image size inference
dataset = LoadStreams(source, img_size=imgsz, stride=stride, auto=pt and not jit)
bs = len(dataset) # batch_size
else:
dataset = LoadImages(source, img_size=imgsz, stride=stride, auto=pt and not jit)
bs = 1 # batch_size
vid_path, vid_writer = [None] * bs, [None] * bs
# Run inference
if pt and device.type != "cpu":
model(torch.zeros(1, 3, *imgsz).to(device).type_as(next(model.model.parameters()))) # warmup
dt, seen = [0.0, 0.0, 0.0], 0
for path, im, im0s, vid_cap, s in dataset:
t1 = time_sync()
im = torch.from_numpy(im).to(device)
im = im.half() if half else im.float() # uint8 to fp16/32
im /= 255 # 0 - 255 to 0.0 - 1.0
if len(im.shape) == 3:
im = im[None] # expand for batch dim
t2 = time_sync()
dt[0] += t2 - t1
# Inference
# visualize = increment_path(save_dir / Path(path).stem, mkdir=True) if visualize else False
pred = model(im, augment=augment, visualize=visualize)
t3 = time_sync()
dt[1] += t3 - t2
# NMS
pred = non_max_suppression(pred, conf_thres, iou_thres, classes, agnostic_nms, max_det=max_det)
dt[2] += time_sync() - t3
# Second-stage classifier (optional)
# pred = utils.general.apply_classifier(pred, classifier_model, im, im0s)
# Process predictions
for i, det in enumerate(pred): # per image
seen += 1
if webcam: # batch_size >= 1
p, im0, frame = path[i], im0s[i].copy(), dataset.count
s += f'{
i}: '
else:
p, im0, frame = path, im0s.copy(), getattr(dataset, 'frame', 0)
p = Path(p) # to Path
# save_path = str(save_dir / p.name) # im.jpg
# txt_path = str(save_dir / 'labels' / p.stem) + (
# '' if dataset.mode == 'image' else f'_{frame}') # im.txt
s += '%gx%g ' % im.shape[2:] # print string
gn = torch.tensor(im0.shape)[[1, 0, 1, 0]] # normalization gain whwh
imc = im0.copy() if save_crop else im0 # for save_crop
annotator = Annotator(im0, line_width=line_thickness, example=str(names))
if len(det):
# Rescale boxes from img_size to im0 size
det[:, :4] = scale_coords(im.shape[2:], det[:, :4], im0.shape).round()
# Print results
for c in det[:, -1].unique():
n = (det[:, -1] == c).sum() # detections per class
s += f"{
n} {
names[int(c)]}{
's' * (n > 1)}, " # add to string
# Write results
for *xyxy, conf, cls in reversed(det):
if save_txt: # Write to file
xywh = (xyxy2xywh(torch.tensor(xyxy).view(1, 4)) / gn).view(
-1).tolist() # normalized xywh
line = (cls, *xywh, conf) if save_conf else (cls, *xywh) # label format
# with open(txt_path + '.txt', 'a') as f:
# f.write(('%g ' * len(line)).rstrip() % line + '\n')
if save_img or save_crop or view_img: # Add bbox to image
c = int(cls) # integer class
label = None if hide_labels else (names[c] if hide_conf else f'{
names[c]} {
conf:.2f}')
annotator.box_label(xyxy, label, color=colors(c, True))
# if save_crop:
# save_one_box(xyxy, imc, file=save_dir / 'crops' / names[c] / f'{p.stem}.jpg',
# BGR=True)
# Print time (inference-only)
LOGGER.info(f'{
s}Done. ({
t3 - t2:.3f}s)')
# Stream results
im0 = annotator.result()
if view_img:
cv2.imshow(str(p), im0)
cv2.waitKey(1) # 1 millisecond
cv2.imwrite('frame.jpg', im0)
yield (b'--frame\r\n'
b'Content-Type: image/jpeg\r\n\r\n' + open('frame.jpg', 'rb').read() + b'\r\n')
# String results
print(s)
# wait key to break
if cv2.waitKey(1) & 0xFF == ord('q'):
break
@app.route('/video_feed')
def video_feed():
return Response(gen(),
mimetype='multipart/x-mixed-replace; boundary=frame')
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('--weights', nargs='+', type=str, default='/Users/sinkarsenic/Downloads/mask_detect/权重/best.pt', help='model.pt path(s)')
parser.add_argument('--source', type=str, default='rtmp://ns8.indexforce.com/home/mystream', help='source') # file/folder, 0 for webcam
parser.add_argument('--img-size', type=int, default=640, help='inference size (pixels)')
parser.add_argument('--conf-thres', type=float, default=0.15, help='object confidence threshold')
parser.add_argument('--iou-thres', type=float, default=0.45, help='IOU threshold for NMS')
parser.add_argument('--device', default='', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
parser.add_argument('--classes', nargs='+', type=int, help='filter by class: --class 0, or --class 0 2 3')
parser.add_argument('--agnostic-nms', action='store_true', help='class-agnostic NMS')
parser.add_argument('--augment', action='store_true', help='augmented inference')
parser.add_argument('--update', action='store_true', help='update all models')
parser.add_argument('--project', default='runs/detect', help='save results to project/name')
parser.add_argument('--name', default='exp', help='save results to project/name')
parser.add_argument('--exist-ok', action='store_true', help='existing project/name ok, do not increment')
parser.add_argument('--frame-rate', default=0, type=int, help='sample rate')
opt = parser.parse_args()
app.run(debug=False)
版权声明
本文为[Sink Arsenic]所创,转载请带上原文链接,感谢
https://blog.csdn.net/qq_44846756/article/details/124293582
边栏推荐
- ShardingSphere分库分表
- New dynamic video wallpaper wechat applet source code_ Support multiple categories of short videos - there are also static wallpapers
- 2022G3锅炉水处理上岗证题目及答案
- How to add mailbox email in MySQL data table
- 【建议收藏】吐血整理Golang面试干货21问-吊打面试官-1
- Halo 开源项目学习(一):项目启动
- Detailed explanation of Navicat 15 installation and related problems
- sqlserver 数据传输到 mysql
- 手动搭建hyperledger fabric v2.x 生产网络(四)创建通道,链码的生命周期
- push()与pop()的使用
猜你喜欢

一文学会text-justify,orientation,combine文本属性
在线YAML转Properties工具

The penultimate node in the linked list (sequential search, speed pointer)
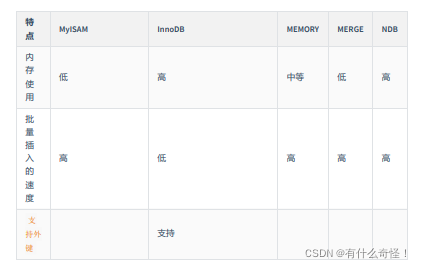
Mysql-advanced-5 storage engine

电脑拆机清灰及机械硬盘安装记录
Online yaml to properties tool

从辩证法角度,如何认知产品

在销量压力下,国产手机开始降价了,但还没有放下最后的面子

Examples of cmake basic knowledge II: single file, multiple files, dynamic and static library and use

There is no product yet. Musk's "boring company" is valued at $5.7 billion
随机推荐
Separate linked list (create two empty linked lists)
Using docker to build LNMP + redis development environment suitable for thinkphp5
idea中如何将Services调出并将启动类显示在Services中
2022G3锅炉水处理上岗证题目及答案
2022年熔化焊接与热切割操作证考试题模拟考试平台操作
2022年高处安装、维护、拆除特种作业证考试题库模拟考试平台操作
新动态视频壁纸微信小程序源码_支持多种分类短视频-也有静态壁纸
unity之动态批处理和静态批处理
Construire manuellement le tissu hyperledger V2. X réseau de production (IV) Création de canaux, cycle de vie des codes de chaîne
Unicorn Bio筹集320万美元资金 将用于培养肉的原型设备变成商业产品
【ValueError: math domain error】
Flink流处理引擎系统学习(三)
14 py games source code sharing
微搭低代码零基础入门课
server 2019服务器可用内存是实际内存的一半
网站域名申请问题
L3-005 垃圾箱分布 (30 分)(dijkstar
mysql主备配置 二进制日志问题
Using stack to realize queue (double stack, input stack and output stack)
多线程技术核心