当前位置:网站首页>日常学习记录——读取自定义数据集
日常学习记录——读取自定义数据集
2022-04-22 05:40:00 【锂盐块呀】
sklearn读取自定义数据集
import csv
from sklearn.utils import Bunch
# 读取西瓜数据集
def readWatermelonDataSet():
FeatureNames = []
FeatureList = []
LabelList = []
ifile = open("E:\My Word\study\RL0314\data.csv", "r")
reader = csv.reader(ifile)
cnt = 0
for row in reader:
if cnt == 0: # 读取属性名称
headers = row
FeatureNames = headers[1:len(headers) - 1]
# print(FeatureNames)
else: # 读取数据和标签
headers = row
FeatureList.append(headers[1:len(headers) - 1])
LabelList.append(headers[len(headers) - 1])
cnt = cnt + 1
print(FeatureNames)
print(FeatureList)
print(LabelList)
return Bunch(
data=FeatureList,
target=LabelList,
feature_names=FeatureNames,
)
注意:如果想要直接使用sklearn后续算法,数据集里应该为数值型的数据,但凡加入西瓜数据集其他栏后续都会报错,需要做好数据预处理。
这里使用的数据集是这样的:
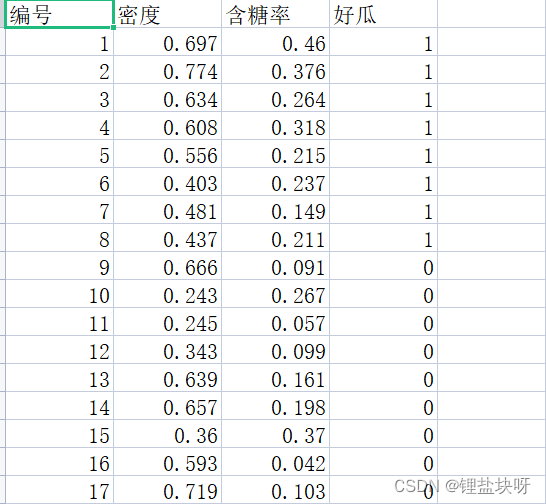
完整决策树生成代码:
import csv
from sklearn.utils import Bunch
from sklearn import tree
from sklearn.model_selection import train_test_split
import pandas as pd
import graphviz
import os
# 读取西瓜数据集
def readWatermelonDataSet():
FeatureNames = []
FeatureList = []
LabelList = []
ifile = open("E:\My Word\study\RL0314\data.csv", "r")
reader = csv.reader(ifile)
cnt = 0
for row in reader:
if cnt == 0: # 读取属性名称
headers = row
FeatureNames = headers[1:len(headers) - 1]
# print(FeatureNames)
else: # 读取数据和标签
headers = row
FeatureList.append(headers[1:len(headers) - 1])
LabelList.append(headers[len(headers) - 1])
cnt = cnt + 1
print(FeatureNames)
print(FeatureList)
print(LabelList)
return Bunch(
data=FeatureList,
target=LabelList,
feature_names=FeatureNames,
)
def main():
watermelon = readWatermelonDataSet() # 西瓜数据
pd.concat([pd.DataFrame(watermelon.data), pd.DataFrame(watermelon.target)], axis=1)
Xtrain, Xtest, Ytarin, Ytest = train_test_split(watermelon.data, watermelon.target, test_size=0.3) # 测试集30%训练集70%
"""建立模型"""
clf = tree.DecisionTreeClassifier(criterion="entropy") # 实例化,分类树
clf = clf.fit(Xtrain, Ytarin)
score = clf.score(Xtest, Ytest)
score
dot_data = tree.export_graphviz(clf
, feature_names=watermelon.feature_names
, class_names=["好瓜", "坏瓜"]
, filled=True
, rounded=True
, special_characters=True
, fontname="Microsoft YaHei")
graph = graphviz.Source(dot_data)
os.environ["PATH"] += os.pathsep + 'D:/DiyProgram/graphviz/bin/'
graph.render("watermelon1", view=True)
if __name__ == "__main__":
main()
运行结果:


版权声明
本文为[锂盐块呀]所创,转载请带上原文链接,感谢
https://blog.csdn.net/weixin_39276221/article/details/124298854
边栏推荐
- MYSQL知识点总结大全
- C语言--经典100题
- Simple DP questions - cow breeding and super stair climbing
- Musk updates wechat push (Dog Coin)
- Dictionary tree template
- LeetCode 1770. Maximum score for performing multiplication -- interval DP
- Several ways to exchange two variable values without the third variable
- 13 - container - List
- 马斯克更新微信推送(狗狗币)
- Miniconda source swap (add image)
猜你喜欢







随机推荐
Torch uses stepping on the pit diary and matrix to speed up the operation
14 - 容器-元组
Complete knapsack problem
Optimization theory: transportation problem (I) finding the minimum freight [northwest corner method, minimum element method, Vogel method]
07- 运算符
蓝桥杯31天冲刺 Day17
正在读取软件包列表... 完成 正在分析软件包的依赖关系树 正在读取状态信息... 完成 有一些软件包无法被安装。如果您用的是 unstable 发行版,这也许是 因为系统
13 - container - List
ip数据报中首部 总长度 片偏移的单位
CONDA command
scikit-learn中的PCA
2021 408 考研大纲更改项
Telbot load balancing settings
考研结束了
Two ways of JS array value
Explanation of "write a byte to the output stream. The bytes to be written are the eight low bits of parameter B. the 24 high bits of B will be ignored"
时钟
06 - data type
golang学习和校招经历
LeetCode 589. Preorder traversal of n-ary tree