当前位置:网站首页>Linear regression and logistic regression (logistic regression and linear regression)
Linear regression and logistic regression (logistic regression and linear regression)
2022-08-06 18:32:00 【sweetheart7-7】
文章目录
Linear regression is generally used for data prediction,The predicted results are generally real numbers.
Logistic regression is generally used for classification prediction,The prediction results are generally some kind of probabilities.

线性回归
Step 1: Model
定义模型
Step 2: Goodness of Function
定义 Loss 函数,Used to judge whether the model is good or bad,selected here MSE
通过最小化 Loss 函数,来得到更好的模型
Step 3: Gradient Descent
Parameters are optimized by gradient descent
Gradient descent with two parameters
可视化
Linear regression There is no local optimal solution
分别对 w w w 和 b b b 求偏导
How’s the results?

Model Selection
Introduce multiple items,定义更复杂的 Model
It may appear when the model is more complex Overfitting 的情况
Back to step 1: Redesign the Model
重新定义模型,Consider the effect of species on the results

考虑其他 feature 对结果的影响,重新定义Model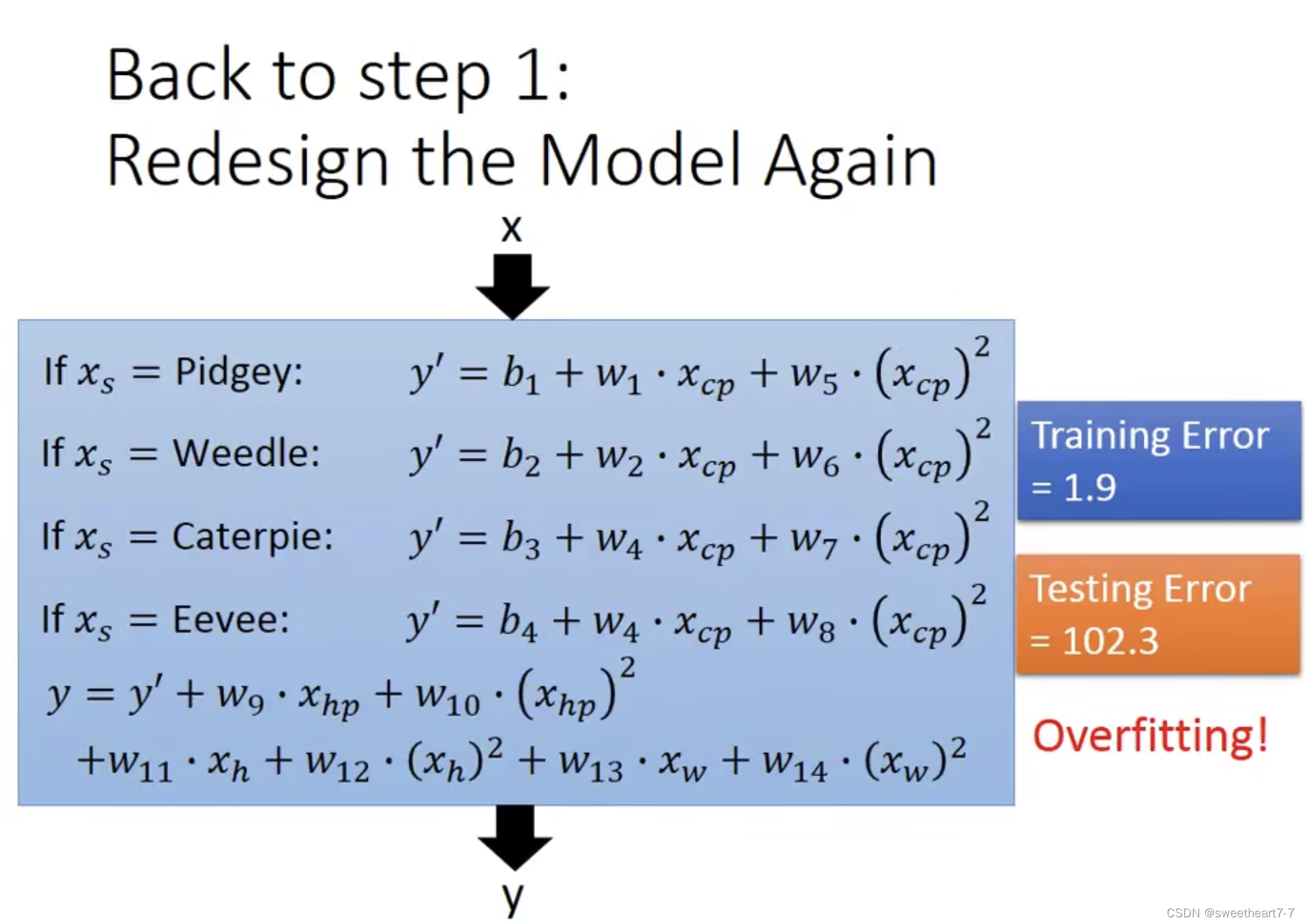
Back top step 2: Regularization
对 Loss function 加入 正则化来解决 Overfitting 问题

Regularization
正则化:Expect smaller parameters function,越平滑,output 对输入的变化是比较不敏感的,Can be insensitive to noise.

λ The bigger the description, the more consideration w w w 本身大小,And the less you think about yourself Loss 大小,所以在 training data performance is getting worse.
为什么不考虑 b b b,Because what we need is a smooth one function,而 b b b 的大小不会改变 function 的平滑程度.
逻辑回归
Ideally define the model function for the classification task

Solved by Gaussian distribution
The data is assumed to belong to a Gaussian distribution(Other distributions can also be assumed,There are subjective conscious influences here),The problem is then solved by a Gaussian model.
Generative Model


最大化 Likelihood

求出 μ 和 ∑

used allfeature ,The result was still broken

Consider giving twoModel 公用 covariance matrix,这样就只需要较少的 parameters(不容易 overfitting)
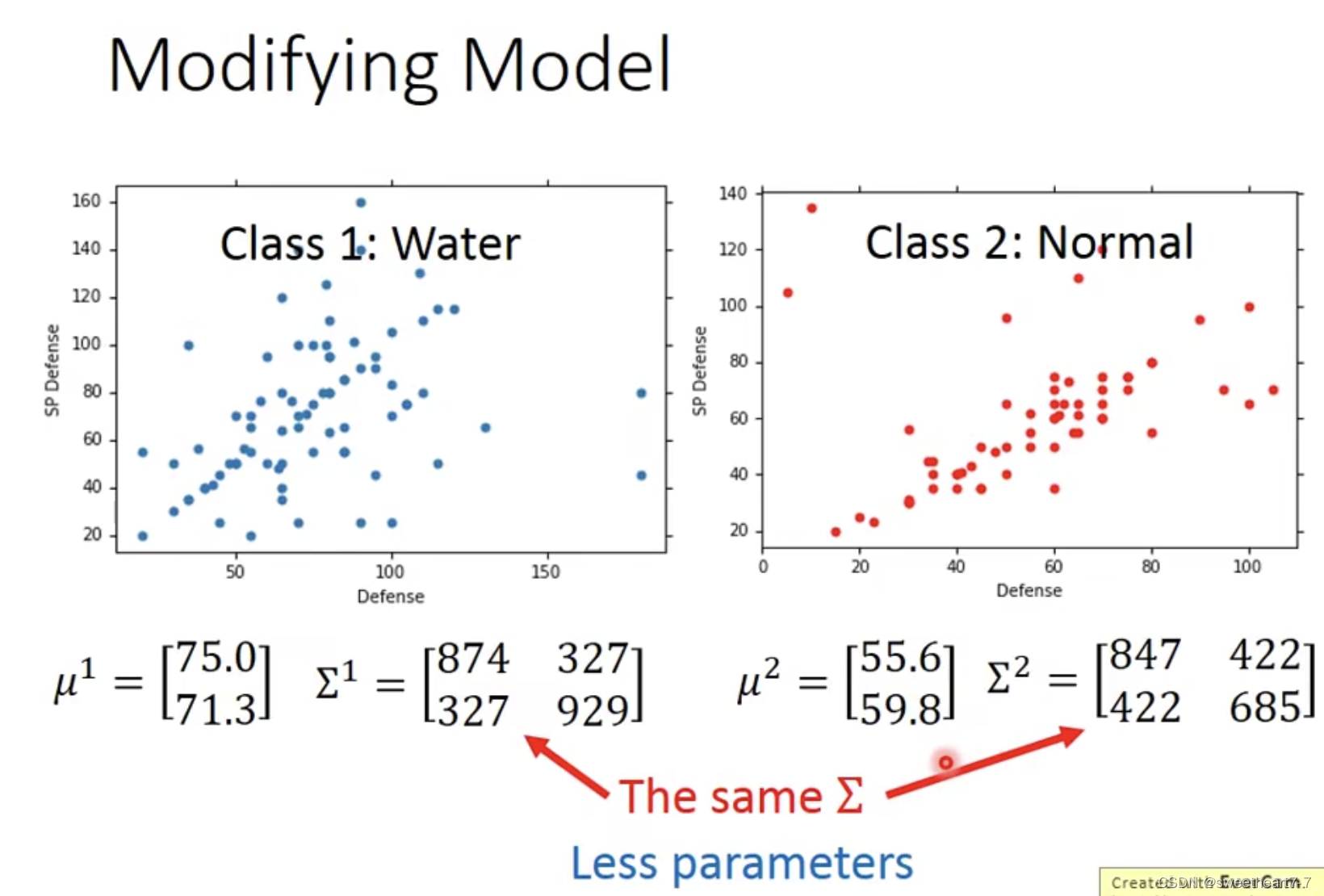
求出 μ 和 ∑

found public ∑ 后,此时的 boundary 是线性的,The accuracy rate has improved a lot.
Three Steps
So the summary is as follows 3 步:
Naive Bayes Classifier
假设所有的 feture 是 independent,Its probability can be expressed in the following form,This model belongs to Naive Bayes Classifier

Posterior Probility
分析 Posterior Probability




Discovered by formula derivation:It can eventually also be written as σ ( w ∗ x + b ) σ(w * x + b) σ(w∗x+b)
Step 1: Function Set
推出来的 σ 就是 sigmoid 函数,其图像表示如下:

It can be represented in the form as follows:

Step 2: Goodness of a Function

最大化 Likelihood 就是最小化 − l n L ( w , b ) -ln L(w, b) −lnL(w,b),Expand as follows:

这种 Loss 函数就是 cross entropy The meaning of representation is two distribution 有多接近,越小越接近

Step 3: Find the best function



w w w 的 update Depends on three things:
- learning rate
- x i x_i xi 来自于 data
- y ^ − f ( x n ) \hat{y} - f(x^n) y^−f(xn),代表 f 的 output 与 理想的 目标值 y ^ \hat{y} y^差距有多大,离目标越远,update the larger the amount

Why can't logistic regression be used MSE 作为 Loss 函数?


- 当 y ^ = 1 \hat{y} = 1 y^=1 时,If the predicted result is f ( x ) = 0 f(x) = 0 f(x)=0,At this time, it is clearly far from the target value,But the gradient value at this time is 0 0 0!
- 当 y ^ = 0 \hat{y} = 0 y^=0 时,If the predicted result is f ( x ) = 1 f(x) = 1 f(x)=1,At this time, it is clearly far from the target value,But the gradient value at this time is 0 0 0!
Cross Entropy vs Square Error

If the logistic regression problem is used square error 时,The gradient may appear in the distance 0 的情况,而不能更新.
Discriminative vs Generative
Discriminative Model Just define the function directly,Then optimize the function Model,Let the machine find it by itself distribution.
Generative Model is to assume one first distribution,Then find the parameter value (μ 和 ∑) 带入 Model.

Accuracy varies

Generative Model made some assumptions
举例:
Used in this example Generative Model 得到 data1 probability is less than 0.5(因为 Navie Bayes Model 假设两个 feature 独立)


在 training data 少的时候,Generative Model 可能表现更好,Not easily affected by noise.

Multi-class Classification
Multi-classification can be solved with the following model
softmax 也可以通过 Gaussain Model 推导出来

多分类问题 Loss 函数 也可以用 Cross Entropy 定义

Limitation of Logistic Regression
The following situation is difficult to solve with logistic regression.

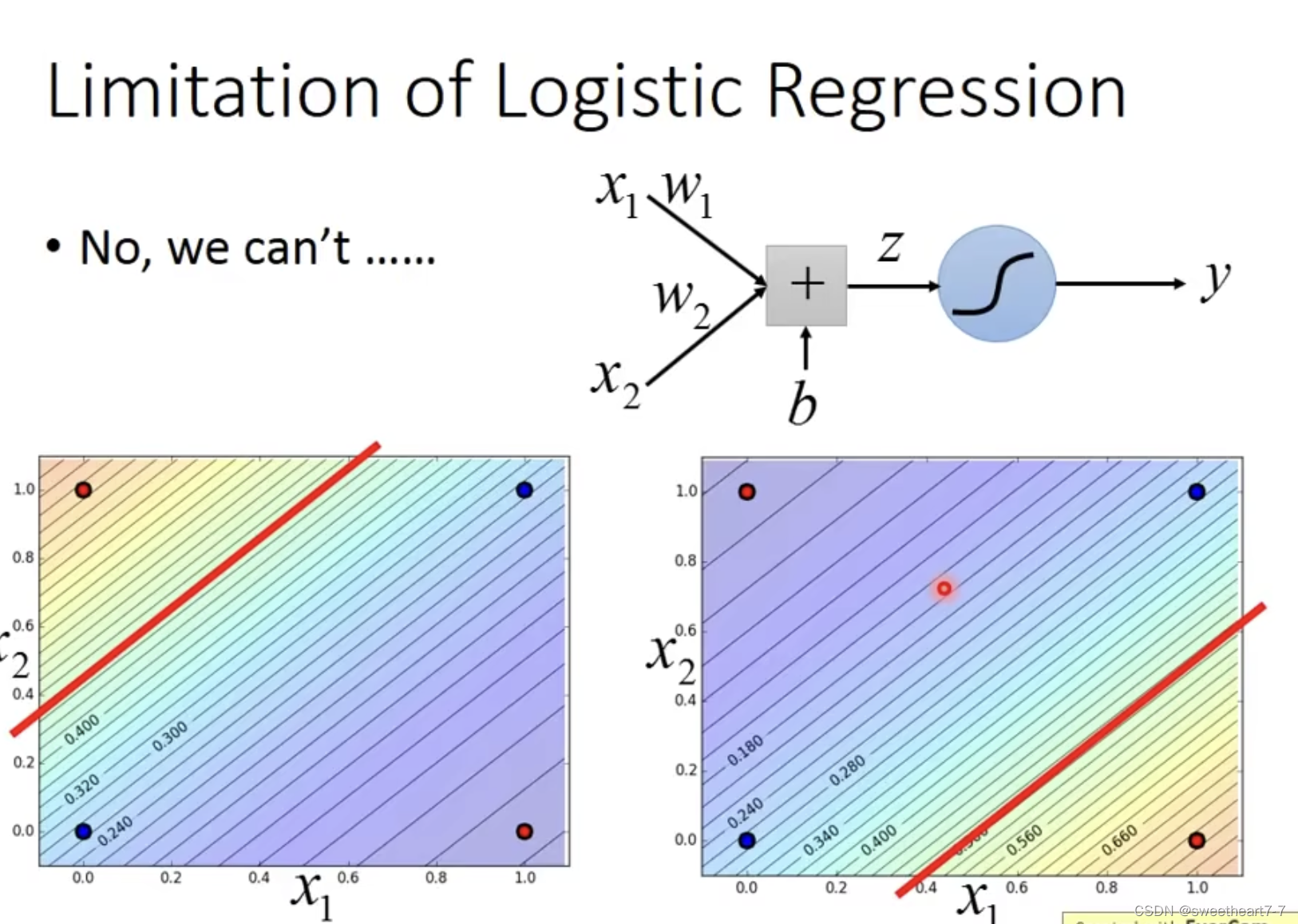
So we can consider pairs of features (feature) 进行转换,Then use logistic regression to solve it

可以将 logistic regression models 多个 cascading 起来,Let the machine find it by itself feature transformation

What the machine finds out is as follows:

可以把这些 Logistic Regression 叠在一起,某一个 Logistic Regression 可以是其他 Logistic Regression 的 output.

可以给这个 Model 一个新名字:Neural Network (Deep learning)
边栏推荐
- C# 将文件转换为 Stream
- 华为设备用户接入与认证配置命令
- A dream in a cave, a thousand years in the capital of Fujian, the immersive performance of the tunnel of "Dream in the Capital of Mind" made a stunning appearance!
- 分享一个在单片机中使用的RTOS代码框架
- ssh 设置密钥认证登录
- js数组遍历常用方法 0802二
- Getting Started with PreScan Quickly to Proficient in Lecture 21: Driver Model Drivers in the Loop
- bootz 启动 kernel
- 最全的交换机知识汇总,看完这一篇就全明白了
- [The Beauty of Software Engineering - Column Notes] 39 | Project Summary: Do a good job in project review and turn experience into ability
猜你喜欢










随机推荐
考研政治 | 自用笔记记录
Linux安装MySQL
ESLint 插件规则编写的正确打开方式
How do Meikeduo and Shopee evaluate self-supporting accounts?
Uncaught ReferenceError: Cannot access ‘f1‘ before initialization
PHP two-dimensional array to heavy
Euro-NCAP-2023-安全驾驶辅助驾驶员状态监测DMS和限速辅助测试流程-中文版
吴恩达深度学习deeplearning.ai——第一门课:神经网络与深度学习——第三节:浅层神经网络
jenkins pipeline reads json file
PyTorch framework builds flower image classification model (Resnet network, transfer learning)
DDNS 动态域名服务
antd的表格有多选框时翻页记住之前选择的数据
对标西湖大学,年薪60万博士后招聘来了
PyTorch框架构建花朵图像分类模型(Resnet网络,迁移学习)
小熊派的学习——内核开发(信息量、事件管理、互斥锁、消息队列)
CarSim Simulation Advanced Advanced (3) ---VS Command Line (3)
数据化管理洞悉零售及电子商务运营——销售中的数据化管理
深入浅出富文本编辑器
Butterfly魔改:网址卡片外挂标签
After resigning naked, I slapped the interviewer of a large factory. After I got an offer from Ali, I still chose Meituan.