当前位置:网站首页>(imdb数据集)电影评论分类实战:二分类问题
(imdb数据集)电影评论分类实战:二分类问题
2022-08-07 14:46:00 【ㄣ知冷煖*】
目录
前言
对于imdb数据集的评论分类实战一、电影评论分类实战
1-1、数据集介绍&数据集导入&分割数据集
# 加载imdb数据集
# 25000条训练和25000条测试数据
# 训练集和测试集都包含50%的正面评论和50%的负面评论。
from keras.datasets import imdb
# 已经经历过预处理,评论,单词序列已经转化为整数序列。
# 加载数据:训练数据、训练标签;测试数据、测试标签。
# num_words=10000:保留训练数据中前10000个最常出现的单词,低频单词将被舍弃。这样得到的向量数据不会太大,便于处理。
(train_data,train_labels),(test_data,test_labels) = imdb.load_data(num_words=10000)
# 查看训练数据
train_data[0:2]
输出:可以看到单词序列已经被转化为了整数序列,否则的话我们还需要手动搭建词典并且将其转化为整数序列。
1-2、字典的键值对颠倒&数字评论解码
# get_word_index: 是imdb自带的方法,获取字典。
# 将单词映射为整数索引的字典。
word_index = imdb.get_word_index()
# 键值颠倒,将整数索引映射为单词。
# 颠倒之后,前边是整数索引,后边是对应的单词。
reverse_word_index = dict(
[(value, key) for (key, value) in word_index.items()])
# 将评论解码,注意,索引减去了3,是因为0、1、2是特殊含义的字符。
decoded_review = ' '.join(
# 根据整数索引,查找对应的单词,然后使用空格来进行连接,如果没有找到相关的索引,那就用问号代替
[reverse_word_index.get(i - 3, '?') for i in train_data[0]])
# 看一下颠倒后的词典
print(reverse_word_index)
# 查看一下解码后的评论
print(decoded_review)
输出reverse_word_index:
输出decoded_review:
1-3、将整数序列转化为张量(训练数据和标签)
# 我们不可以直接把训练数据对应的整数序列输入到神经网络中,所以我们需要先进行转换。
import numpy as np
def vectorize_sequences(sequences,dimension=10000):
"""
将整数序列转化为二进制矩阵的函数
"""
results = np.zeros((len(sequences), dimension))
for i, sequences in enumerate(sequences):
# 相应列上的元素置为1,其他位置上的元素都为0。
results[i, sequences] = 1
return results
# 这里只是预处理的一种方式,即单词序列编码为二进制向量,当然也可以采用其他方式,
# 比如说直接填充列表,然后使其具有相同的长度,然后将其转化为张量,并且网络第一层使用能够处理这种整数张量的层,即Embedding层。
# 训练数据向量化,即将其转化为二进制矩阵
x_train = vectorize_sequences(train_data)
x_test = vectorize_sequences(test_data)
# 将标签向量化·············
y_train = np.asarray(train_labels).astype('float32')
y_test = np.asarray(test_labels).astype('float32')
# 查看一下训练集
x_train
输出:
1-4、搭建神经网络&选择损失函数和优化器&划分出验证集
from keras import models
from keras import layers
model = models.Sequential()
model.add(layers.Dense(16, activation='relu', input_shape=(10000,)))
model.add(layers.Dense(16, activation='relu'))
# 二分类问题的话,网络的最后一层应该是只有一个单元并且使用sigmoid激活的Dense层,输出是0-1范围内的标量,表示概率值。
model.add(layers.Dense(1, activation='sigmoid'))
# rmsprop通常是通用的优化器
model.compile(optimizer='rmsprop',
loss='binary_crossentropy',
metrics=['accuracy'])
x_val = x_train[:10000]
partial_x_train = x_train[10000:]
y_val = y_train[:10000]
partial_y_train = y_train[10000:]
1-5、开始训练&绘制训练损失和验证损失&绘制训练准确率和验证准确率
epochs = 3
history = model.fit(
partial_x_train,
partial_y_train,
epochs=epochs,
batch_size=512,
validation_data=(x_val, y_val)
)
训练过程:
绘制训练损失和验证损失:
import plotly.express as px
import plotly.graph_objects as go
history_dic = history.history
loss_val = history_dic['loss']
val_loss_values = history_dic['val_loss']
# epochs = range(1, len(loss_val)+1)
# np.linspace:作为序列生成器, numpy.linspace()函数用于在线性空间中以均匀步长生成数字序列
# 左闭右闭,所以是从整数1到20.
# 参数:起始、结束、生成的点
epochs = np.linspace(1, epochs, epochs)
fig = go.Figure()
# Add traces
fig.add_trace(go.Scatter(x=epochs, y=loss_val,
mode='markers',
name='Training loss'))
fig.add_trace(go.Scatter(x=epochs, y=val_loss_values,
mode='lines+markers',
name='Validation loss'))
fig.show()
输出:
绘制训练准确率和验证准确率:
acc = history_dic['accuracy']
val_acc = history_dic['val_accuracy']
fig = go.Figure()
# Add traces
fig.add_trace(go.Scatter(x=epochs, y=acc,
mode='markers',
name='Training acc'))
fig.add_trace(go.Scatter(x=epochs, y=val_acc,
mode='lines+markers',
name='Validation acc'))
fig.show()
输出: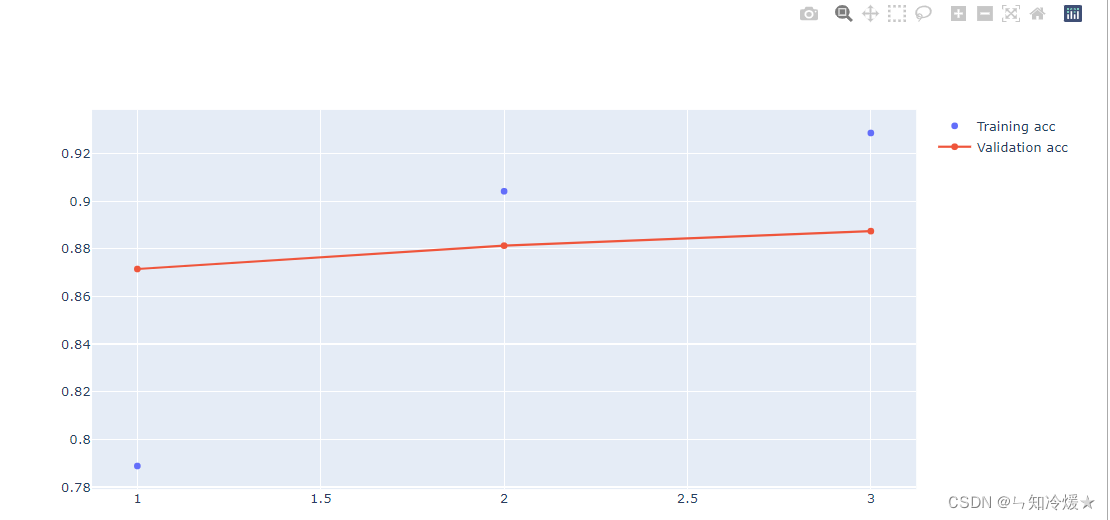
1-6、在测试集上验证准确率
# 两层隐藏层
# 隐藏单元: 16
# 训练20轮次,得到73的损失,85的准确率。
# 训练10轮次,得到41的损失,86的准确率。
# 训练5轮次,得到30的损失,87的准确率。
# 训练4轮次, 得到32的损失,86的准确率。
# 训练3轮次,得到29的损失,88.3的准确率。
# 隐藏单元:32
# 训练4轮次,得到30的损失,87.9的准确率。
# 隐藏单元:64
# 训练3轮次,得到30的损失,87.8的准确率。
model.evaluate(x_test, y_test)
# model.predict(x_test): 得到测试集上评论为正面的可能性大小。

二、调参总结
调参总结:
1、训练轮次:先选择较大的轮次,一般设置为20,观察数据在验证集上的表现,训练是为了拟合一般数据,所以当模型在验证集上准确率下降时,那就不要再继续训练了。
2、隐藏单元设置:二分类选择较小的单元数,如果是多分类的话,可以试着设置较大的单元数,比如说64、128等。
3、隐藏层数设置:同隐藏单元的设置规则,这里设置的层数较少,如果数据复杂,可以多加几层来观察数据的整体表现。
4、标签直接设置为one-hot编码时,则对应设置损失为categorical_crossentropy(分类交叉熵损失函数),若标签直接转化为张量,则对应设置损失为sparse_categorical_crossentropy(稀疏交叉熵损失)。
总结
呱呱呱。
边栏推荐
- WeChat automatic card issuance robot description
- The location identified by the @RequestMapping annotation
- RPG游戏地图场景管理维护(服务器)
- 自定义视频播放器
- 手工测试转自动化,学习路线必不可少,更有【117页】测开面试题,欢迎来预测
- Is it safe to use a straight flush in stocks?Will the funds be transferred?
- 使用同花顺软件炒股安全吗?
- 基于TCP的聊天系统
- Programming Experts in C Chapter 8 Why Programmers Can't Tell the Difference Between Halloween and Christmas 8.9 How and Why Casting
- Codeforces Round #812 (Div. 2)
猜你喜欢









随机推荐
多线程-Lambda表示
微信自动发卡机器人说明
005_Ribbon负载均衡
LeetCode 热题 HOT 100(4.寻找两个正序数组的中位数)
AQS synchronization component - Semaphore (semaphore) analysis and case
我住得比较远,有好的开户途径么?手机开户股票开户安全吗?
Next Generation Wireless LAN - High Throughput
LeetCode Hot Questions HOT 100 (1. Sum of two numbers)
LeetCode Hot Questions HOT 100 (8. Sum of Three Numbers)
C专家编程 第8章 为什么程序员无法分清万圣节和圣诞节 8.2 根据位模式构筑图形
Programming Experts in C Chapter 8 Why Programmers Can't Tell the Difference Between Halloween and Christmas 8.1 The Portzebie Weights and Measures System
Research on the relationship between Yun and Enmo on "HTAP" and "Intelligent Warehouse Lake"
Li Mu d2l(9)--Model Construction
Expert C Programming Chapter 8 Why Programmers Can't Tell the Difference Between Halloween and Christmas 8.3 Types Change While Waiting
注销/撤销/吊销
HJ3 obvious random number
[YOLOv7] Combined with GradCAM heat map visualization
联盛德W801系列1-flash保存数据例程:保存wifi配网信息
002_认识微服务
基于RK3566中RTL8201F网口百兆调试笔记