当前位置:网站首页>TIDB-PD-RECOVER的恢复方式
TIDB-PD-RECOVER的恢复方式
2022-08-07 00:23:00 【与数据交流的路上】
一、简介
1.背景
为了防止因pd出现问题导致pd不可用的情况,tidb官方给出了pd-recover的方法来处理这种情况,本着学习的精神,对几种预想到的想法进行了测试
2.工具下载
wget https://download.pingcap.org/tidb-version-linux-amd64.tar.gz
3.环境简介
一共三台pd的机器,集群名字tidb-1
二、模拟宕机
1.删除三台(全部为三台)pd机器的data目录模拟宕机
# 执行后会看到pd,tikv,tidb全部为down,很快pd变为了up
rm -r pd-2379
2.删除两台pd机器的data目录模拟宕机
3.删除两台或者三台pd机器的deploy目录模拟宕机
4.模拟之前的pd被错误释放,完全无法使用的情况
# 我这里是ubuntu,这个在所有pd机器上执行
# 查看防火墙状态
ufw status
# 开启防火墙
ufw enable
# 开启防火墙规则为默认放开原则
ufw default allow
# 禁止2379,2380的端口访问
ufw deny 2379
ufw deny 2380
三、恢复集群
1.针对宕机情况1的恢复
1.1 查看pd的cluster-id
# 方式一、通过pd日志获取,这时候会发现有两个cluster-id,这是因为所有pd-data删除之后新建了一个pd集群
cat pd.log | grep "init cluster id"
# 方式二、通过tidb日志获取
cat tidb.log | grep "init cluster id"
# 方式三、通过tikv日志获取
cat tikv.log | grep "connect to PD cluster"
1.2 获取已分配的id
# 方式一、通过tidb-cluster-pd面板下的cluster下的Current ID allocation 面板获取最大的已分配 ID,需要确保是pd leader(注:删除pd-data这种模拟方式会导致监控看不到数据)
# 方式二、通过pd日志查看,在所有pd机器执行以下命令,找到最大的id,我这里是4000
cat pd*.log | grep "idAllocator allocates a new id" | awk -F'=' '{print $2}' | awk -F']' '{print $1}' | sort -r -n | head -n 1
1.3 执行pd-recover
# 任意一个pd节点执行即可
# 注意这里的cluster-id是前一个cluster-id,因为后面的cluster-id是新建的pd集群的cluster-id
./pd-recover -endpoints http://192.168.1.1:2379 -cluster-id 6747551640615446306 -alloc-id 4000
1.4 重启pd集群
tiup cluster restart tidb_clustere -R pd
2.针对宕机情况2的恢复方式
2.1 重启pd集群
# 这时候直接重启pd集群即可,你会发现cluster-id和之前的cluster-id一致
tiup cluster restart tidb-cluster -R pd
3.针对宕机情况3的处理方法
3.1 新建一套只含有pd的集群
3.1.1 配置文件
# vim topology-pd.yaml
global:
user: "tidb"
ssh_port: 22
deploy_dir: "/data/tidb/tidb-deploy"
data_dir: "/data/tidb/tidb-data"
server_configs:
pd:
replication.enable-placement-rules: true
pd_servers:
- host: 192.168.1.4
- host: 192.168.1.5
- host: 192.168.1.6
3.1.2 部署
tiup cluster deploy tidb-2 v5.4.1 ./topology_pd.yaml --user tidb -p
3.2 迁移和更改文件
将deploy目录复制到之前的集群中,然后将scripts下run_pd.sh的对应信息更改即可
3.3 特殊情况处理
如果特别不幸的情况,你在迁移deploy目录之前重启了pd,然后导致pd起不来,用上面的方法也启动不起来,那么可能在上面的步骤后再次进行pd-recover操作
4.针对宕机情况4的处理方法
4.1 新建一套集群,方法可以参考3.1
4.2 对pd集群(tidb-2)进行pd-recover操作
# 任意一个pd节点执行即可,获取cluster-id和alloc-iid的ne
./pd-recover -endpoints http://192.168.1.1:2379 -cluster-id 6747551640615446306 -alloc-id 4000
4.3 修改tidb/tikv(tidb-1集群)的scripts目录下的run.sh脚本
vim run_tikv.sh
# 修改--pd的地址为test-2集群的pd地址
vim run_tidb.sh
# 修改--path的地址为test-2集群的pd地址
4.4 修改原集群的(tidb-1)meta.yaml文件
vim .tiup/storage/cluster/clusters/tidb-1/meta.yaml
# 修改pd部分的信息为tidb-2部分的信息
4.5 关闭tidb-2集群
tiup cluster stop tidb-2
4.6 重启tidb-1集群
tiup cluster restart tidb-1
4.7 后续处理
后面可以扩容出三台新的pd,先后将test-2的pd缩容掉,避免两套pd集群产生不利的影响,但是这里扩容又会报pd端口冲突,因为pd在两套集群同时存在,所以端口冲突,所以比较好的解决方式还是拷贝tidb-2的pd集群文件到tidb-1,然后销毁tidb-2的集群,这种操作更好一些
边栏推荐
- [7] Advanced C language -- program compilation (preprocessing operation) + linking
- Opencv立体相机标定
- Arrangement of knowledge points in public relations
- 黑马2022最新redis课程笔记知识点(面试用)持续更新
- express学习30-多人管理22验证joi
- Public Relations Exam Questions and Reference Answers
- 网页版MC服务器搭建+汉化
- 软件测试面试题:手工测试与自动测试有哪些区别?
- 2022 P Gas Cylinder Filling Exam Questions and Answers
- Contrastive Learning Model Cheat Sheet (1)
猜你喜欢

ICCV何恺明团队又一神作:Transformer仍有继续改善的空间

leetcode 21. 合并两个有序链表(可进阶)

04 多线程与高并发 - ReentrantReadWriteLock 源码解析
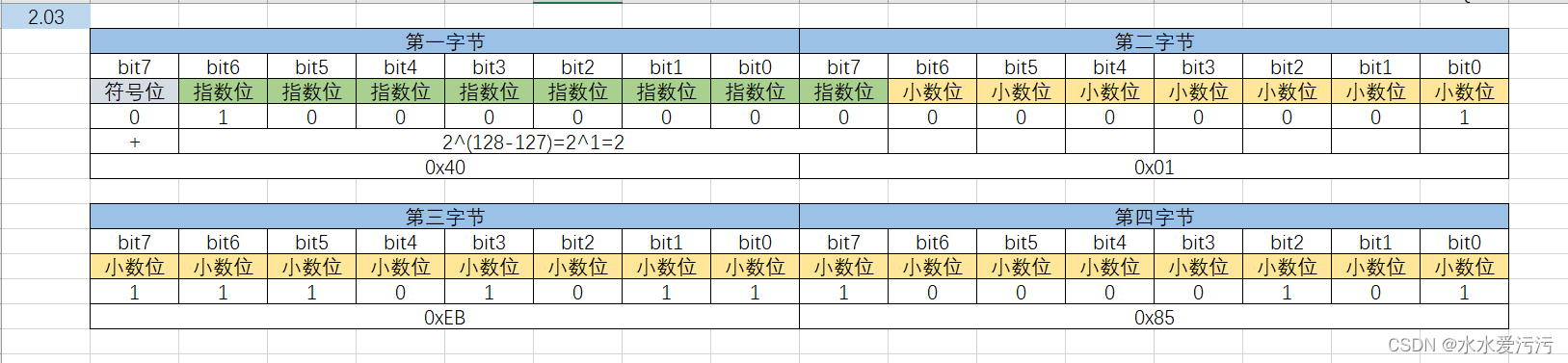
数据类型float存储结构的理解

Introduction to Ftrace function graph

Detailed explanation of C51 basic functions, interrupt functions and library functions
What is the best book to read for self-study software testing?

Hand torn Android Framework bottom-level interview questions collection

Web开发初探:网页布局盒子模型

【7】C语言进阶--程序的编译(预处理操作)+链接
随机推荐
位运算应用:保存多状态标识应用
又来到熟悉的地方
NAT穿越技术详细介绍
Public Relations and Interpersonal Skills
长安欧尚z6idd的智能性如何?采用了整套主被动安全保护措施
服务端没有 listen,客户端发起连接建立,会发生什么?
图注意力机制理解
测试工程师转开发希望大吗?
1408. A daily topic 】 【 string matching of the array
软件测试面试题:手工测试与自动测试有哪些区别?
04 多线程与高并发 - ReentrantReadWriteLock 源码解析
2022.8.4 Mock Competition
在线问题反馈模块实战(二十一):完结篇
time complexity and space complexity
azkaban
网络通信之NIO编程
多项式——多项式牛顿迭代
炒股用通达信交易靠谱吗?安全吗?
今日睡眠质量记录70分
MySQL操作之DQL