当前位置:网站首页>ELK日志分析系统(二)之ELK搭建部署
ELK日志分析系统(二)之ELK搭建部署
2022-08-06 05:24:00 【2354838711】
目录
一、Elasticsearch 集群部署(在Node1上操作)
二、Elasticsearch 集群部署(在Node2上操作)
三、安装 Elasticsearch-head 插件(node1和node2节点操作一样)
3、安装 Elasticsearch-head 数据可视化工具
8、通过 Elasticsearch-head查看Elasticsearch 信息
4.3 使用 rubydebug 输出详细格式显示,codec 为一种编解码器
4.4 使用 Logstash 将信息写入 Elasticsearch 中
5、将 Apache 服务器的日志(访问的、错误的)添加到 Elasticsearch 并通过 Kibana 显示
引言
随着业务量的增长,每天业务服务器将会产生上亿条的日志,单个日志文件达几个GB,这时我们发现用Linux自带工具,cat grep awk 分析越来越力不从心了,而且除了服务器日志,还有程序报错日志,分布在不同的服务器,查阅繁琐。
一、Elasticsearch 集群部署(在Node1上操作)
Node1节点:192.168.10.13
Node2节点:192.168.10.16
Apache节点:192.168.10.19
Elasticsearch包下载地址
https://www.elastic.co/cn/downloads/past-releases/elasticsearch-5-5-0
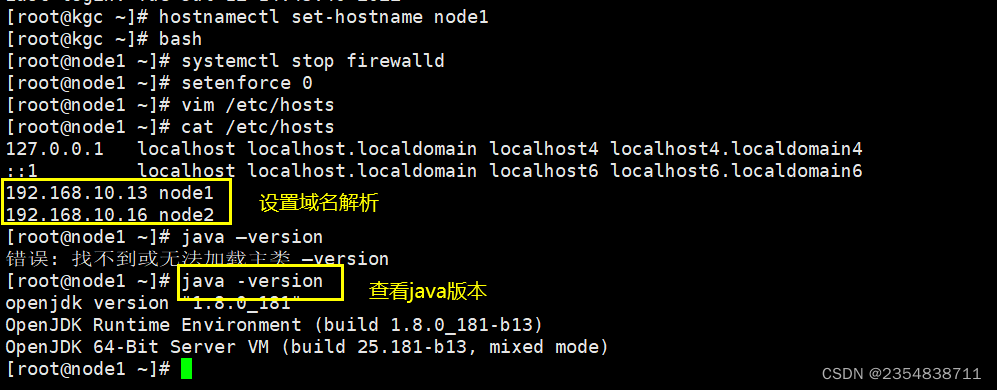
1、准备环境
更改主机名,配置域名解析,查看java环境
hostnamectl set-hostname node1
bash
systemctl stop firewalld
setenforce 0
vim /etc/hosts
java –version
2、部署安装Elasticsearch软件
rpm -ivh elasticsearch-5.5.0.rpm
cd /etc/elasticsearch/
cp elasticsearch.yml elasticsearch.yml.bak

3、配置Elasticsearch主配置文件
vim /etc/elasticsearch/elasticsearch.yml
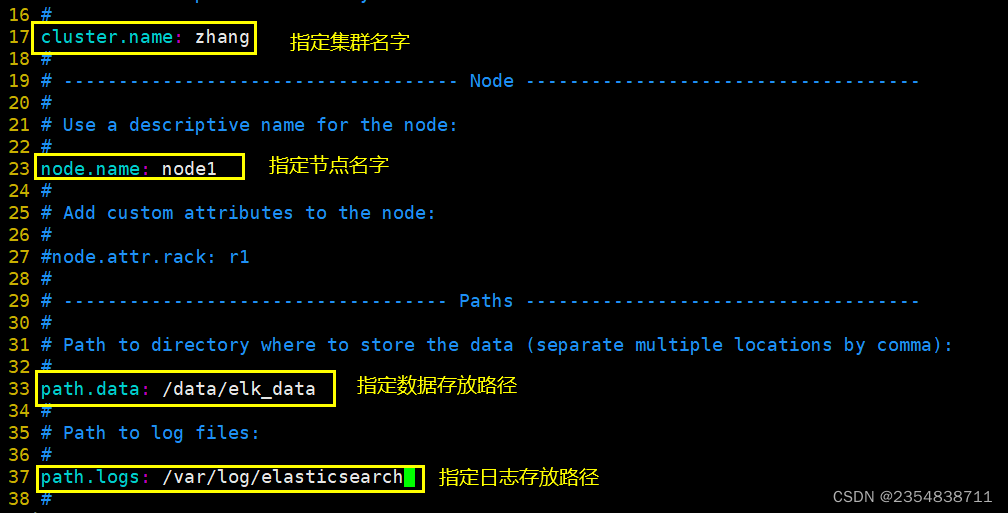
--17--取消注释,指定集群名字
cluster.name: zhang
--23--取消注释,指定节点名字:Node1节点为node1,Node2节点为node2
node.name: node1
--33--取消注释,指定数据存放路径
path.data: /data/elk_data
--37--取消注释,指定日志存放路径
path.logs: /var/log/elasticsearch/
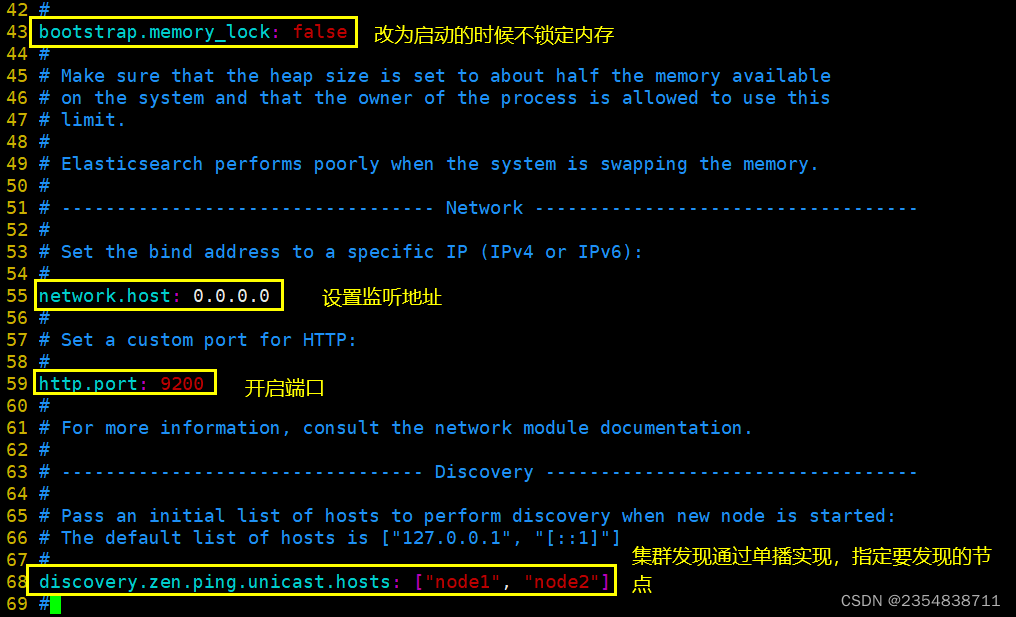
--43--取消注释,改为在启动的时候不锁定内存
bootstrap.memory_lock: false
--55--取消注释,设置监听地址,0.0.0.0代表所有地址
network.host: 0.0.0.0
--59--取消注释,ES 服务的默认监听端口为9200
http.port: 9200
--68--取消注释,集群发现通过单播实现,指定要发现的节点 node1、node2
discovery.zen.ping.unicast.hosts: ["node1", "node2"]
grep -v "^#" /etc/elasticsearch/elasticsearch.yml

4、创建数据存放路径并授权
mkdir -p /data/elk_data
chown elasticsearch:elasticsearch /data/elk_data/
systemctl start elasticsearch
netstat -antp | grep 9200
systemctl enable --now elasticsearch.service
netstat -antp | grep 9200

5、查看node1节点信息


二、Elasticsearch 集群部署(在Node2上操作)
1、前面步骤与node1节点一致

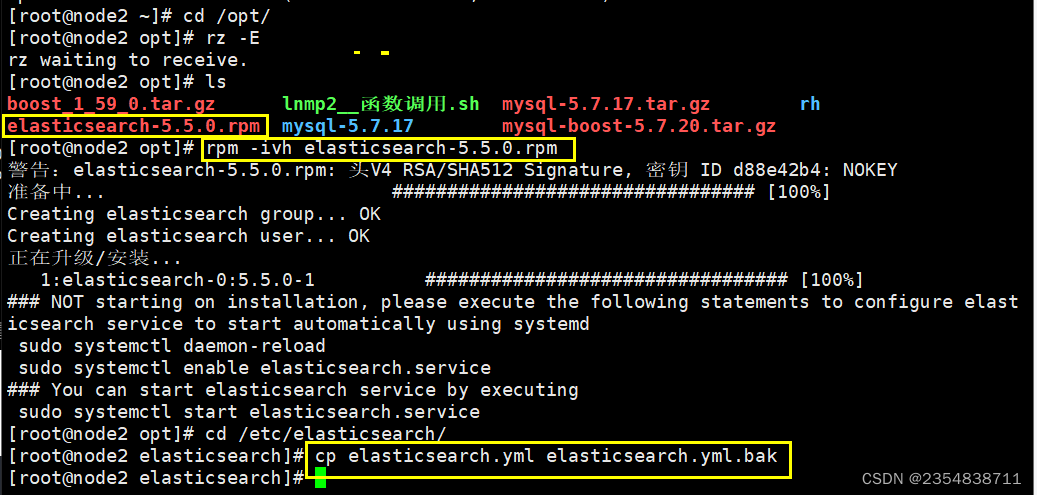
2、在node1节点上把配置文件上传到node2节点

3、修改配置文件
vim /etc/elasticsearch/elasticsearch.yml
grep -v "^#" /etc/elasticsearch/elasticsearch.yml

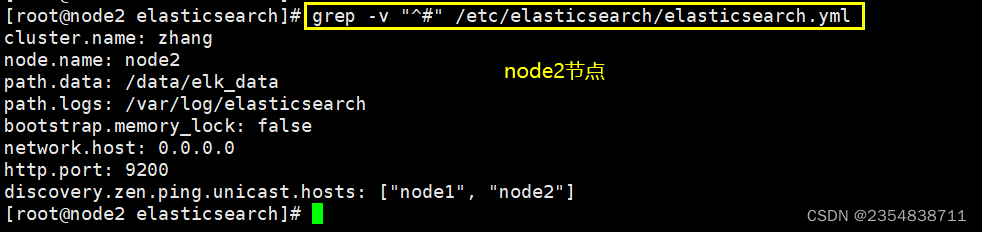
4、创建数据存放路径并授权
mkdir -p /data/elk_data
chown elasticsearch:elasticsearch /data/elk_data/
systemctl daemon-reload
systemctl enable --now elasticsearch.service
systemctl start elasticsearch
netstat -antp | grep 9200
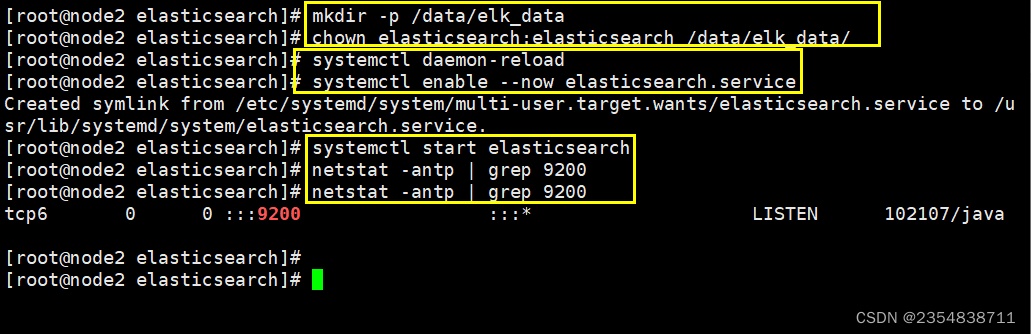
5、查看node2节点信息


由于es服务启动之后,访问界面比较丑陋,为了更好的查看索引库当中的信息,我们可以通过安装elasticsearch-head这个插件来实现,这个插件可以更方便快捷的看到es的管理界面。
三、安装 Elasticsearch-head 插件(node1和node2节点操作一样)
Elasticsearch 在 5.0 版本后,Elasticsearch-head 插件需要作为独立服务进行安装,需要使用npm工具(NodeJS的包管理工具)安装。
安装 Elasticsearch-head 需要提前安装好依赖软件 node 和 phantomjs。
node:是一个基于 Chrome V8 引擎的 JavaScript 运行环境。
phantomjs:是一个基于 webkit 的JavaScriptAPI,可以理解为一个隐形的浏览器,任何基于 webkit 浏览器做的事情,它都可以做到。
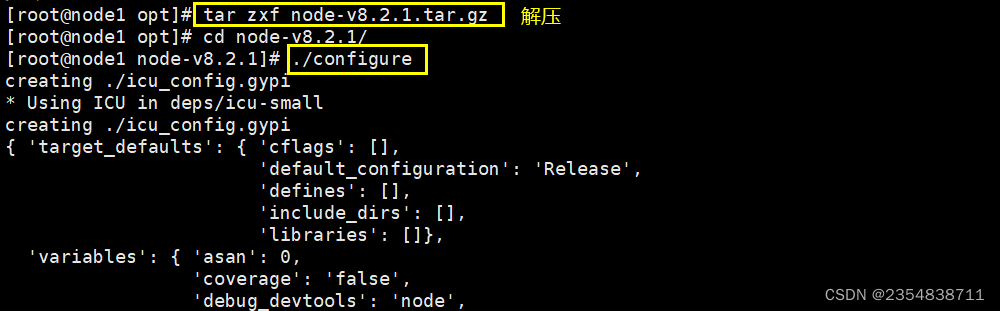
1、编译安装 node
上传软件包 node-v8.2.1.tar.gz 到/opt
yum install gcc gcc-c++ make -ycd /opt
tar zxvf node-v8.2.1.tar.gzcd node-v8.2.1/
./configure
make && make install


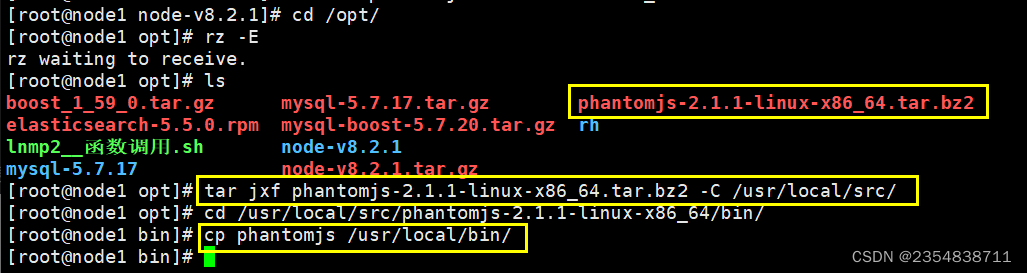
2、安装 phantomjs
上传软件包 phantomjs-2.1.1-linux-x86_64.tar.bz2到opt
cd /opt
tar jxvf phantomjs-2.1.1-linux-x86_64.tar.bz2 -C /usr/local/src/
cd /usr/local/src/phantomjs-2.1.1-linux-x86_64/bin
cp phantomjs /usr/local/bin
3、安装 Elasticsearch-head 数据可视化工具
上传软件包 elasticsearch-head.tar.gz 到/opt
cd /opt
tar zxvf elasticsearch-head.tar.gz -C /usr/local/src/
cd /usr/local/src/elasticsearch-head/
npm install

4、修改 Elasticsearch 主配置文件
vim /etc/elasticsearch/elasticsearch.yml
--末尾添加以下内容--
http.cors.enabled: true
http.cors.allow-origin: "*"


5、修改Gruntfile.js配置文件


6、修改app.js配置文件


7、启动 elasticsearch-head 服务
/usr/local/src/elasticsearch-head/node_modules/grunt/bin
./grunt server


8、通过 Elasticsearch-head查看Elasticsearch 信息
浏览器访问 http://192.168.10.13:9100/ 地址并连接群集。如果看到群集健康值为 green 绿色,代表群集很健康。

9、插入索引,进行测试
curl -X PUT 'localhost:9200/index-demo/test/1?pretty&pretty' -H 'content-Type: application/json' -d '{"user":"zhangsan","mesg":"zhangsan daociyiyou"}'

浏览器访问 http://192.168.10.13:9100/ 查看索引信息,可以看见索引默认被分片5个,并且有一个副本。
点击“数据浏览”,会发现在node1上创建的索引为 index-demo,类型为 test 的相关信息。

四、Logstash 部署(192.168.10.19)
下载地址:https://www.elastic.co/cn/downloads/past-releases/logstash-5-5-1
Logstash 一般部署在需要监控其日志的服务器。在本案例中,Logstash 部署在 Apache 服务器上,用于收集 Apache 服务器的日志信息并发送到 Elasticsearch。
1、安装httpd服务
yum -y install httpd
systemctl start httpd

2、安装java环境
yum -y install java
java –version

3、安装logstash
cd /opt
rpm -ivh logstash-5.5.1.rpm
systemctl start logstash.service
systemctl enable logstash.service
ln -s /usr/share/logstash/bin/logstash /usr/local/bin/

4、测试 Logstash
4.1 Logstash 命令常用选项
-f:通过这个选项可以指定 Logstash 的配置文件,根据配置文件配置 Logstash 的输入和输出流。
-e:从命令行中获取,输入、输出后面跟着字符串,该字符串可以被当作 Logstash 的配置(如果是空,则默认使用 stdin 作为输入,stdout 作为输出)。
-t:测试配置文件是否正确,然后退出。
4.2 定义输入输出流
输入采用标准输入,输出采用标准输出(类似管道)
指定数据输入端口,默认为9600~9700
logstash -e 'input { stdin{} } output { stdout{} }'

4.3 使用 rubydebug 输出详细格式显示,codec 为一种编解码器
logstash -e 'input { stdin{} } output { stdout{ codec=>rubydebug } }'

4.4 使用 Logstash 将信息写入 Elasticsearch 中
logstash -e 'input { stdin{} } output { elasticsearch { hosts=>["192.168.10.13:9200"] } }'


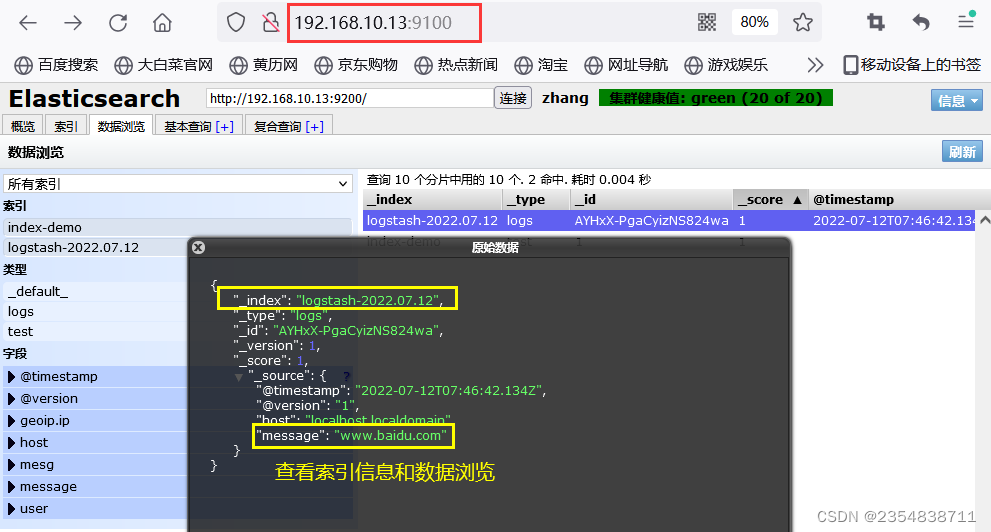
结果不在标准输出显示,而是发送至 Elasticsearch 中,可浏览器访问 http://192.168.10.13:9100/ 查看索引信息和数据浏览。
5、定义logstash配置文件
Logstash 配置文件基本由三部分组成(根据需要选择使用)
- input:表示从数据源采集数据,常见的数据源如Kafka、日志文件等
- filter:表示数据处理层,包括对数据进行格式化处理、数据类型转换、数据过滤等,支持正则表达式
- output:表示将Logstash收集的数据经由过滤器处理之后输出到Elasticsearch。
修改 Logstash 配置文件,让其收集系统日志/var/log/messages,并将其输出到 elasticsearch 中

input {
file{
path =>"/var/log/messages"
type =>"system"
start_position =>"beginning"
}}
output {
elasticsearch {
hosts => ["192.168.109.11:9200"]
index =>"system-%{+YYYY.MM.dd}"
}
}


6、浏览器验证,查看索引信息


可以看到有很多的信息,但不好过滤信息,所以我们接下来安装kiabana
五、Kibana部署(Node1节点)
下载地址:https://www.elastic.co/cn/downloads/past-releases/kibana-5-5-1
1、安装 Kibana
cd /opt
rpm -ivh kibana-5.5.1-x86_64.rpm

2、设置kibana的主配置文件
vim /etc/kibana/kibana.yml
--2--取消注释,Kiabana 服务的默认监听端口为5601
server.port: 5601
--7--取消注释,设置 Kiabana 的监听地址,0.0.0.0代表所有地址
server.host: "0.0.0.0"
--21--取消注释,设置和 Elasticsearch 建立连接的地址和端口
elasticsearch.url: "http://192.168.80.10:9200"
--30--取消注释,设置在 elasticsearch 中添加.kibana索引
kibana.index: ".kibana"


3、启动kibana服务
systemctl daemon-reload
systemctl start kibana.service
systemctl enable kibana.service
netstat -antp | grep 5601

4、验证Kibana
浏览器访问http://192.168.10.13:5601





5、将 Apache 服务器的日志(访问的、错误的)添加到 Elasticsearch 并通过 Kibana 显示
vim /etc/logstash/conf.d/apache_log.conf
input {
file{
path => "/etc/httpd/logs/access_log"
type => "access"
start_position => "beginning"
}
file{
path => "/etc/httpd/logs/error_log"
type => "error"
start_position => "beginning"
}
}
output {
if [type] == "access" {
elasticsearch {
hosts => ["192.168.10.13:9200"]
index => "apache_access-%{+YYYY.MM.dd}"
}
}
if [type] == "error" {
elasticsearch {
hosts => ["192.168.10.13:9200"]
index => "apache_error-%{+YYYY.MM.dd}"
}
}
}

cd /etc/logstash/conf.d/
/usr/share/logstash/bin/logstash -f apache_log.conf


打开宿主机(192.168.10.16)访问apache页面

浏览器访问 http://192.168.10.13:9100 查看索引是否创建





然后在宿主机上刷新访问,会刷新日志,可以在kibana查看时间
总结
ELK 是由 ElasticSearch、 Logstash和Kiabana 三个开源工具组成的
分别的功能如下:
① ES(nosql非关数据库):存储功能和索引
② Logstash(收集日志):到应用服务器上拿取log,并进行格式转换后输出到es中,通过input功能来收集/采集log
③ filter过滤器:格式化数据,output输出日志到 es 数据库内
④ Kibana(展示工具):将es内的数据在浏览器展示出来,通过UI界面展示(可以根据自己的需求对日志进行处理,方便查阅读取)EFK 系统下的各个组件都非常吃内存,后期根据业务需要,EFK 的架构可进行扩展,当 FileBeat 收集的日志越来越多时,为防止数据丢失,可引入 Redis,而 ElasticSearch 也可扩展为集群,并使用 Head 插件进行管理, 所以要保证服务器有充足的运行内存和磁盘空间。
边栏推荐
猜你喜欢

antdesign 动态引入icon

office运行时错误,部分系统文件可能丢失或已损坏(错误代码:0x80040154)

首站圆满落幕!Fortinet Accelerate 2022中国区全国路演盛大起航

揭示OT安全四大挑战!Fortinet 发布《2022年全球运营技术和网络安全态势报告》

Build your own V Rising self-built server, and solutions to common V Rising server problems

Fortinet :《2021 年OT与网络安全现状报告》之「OT安全洞察」

External Interrupts and Timers

Docker quickly installs & builds Mysql environment

类和对象随手记

FortiGate NGFW打造安全、高效、智能的边界安全枢纽
随机推荐
Fortinet发布2022年安全趋势预测,威胁将蔓延整个攻击面
Responsive layout
Docker 快速安装&搭建 Redis 环境
线程同步方法
SSH服务详解
LVS虚拟服务器中负载均衡玩法
全网最全面的SSM整合(没有之一)
你懂函数递归吗!五分钟教你玩转shell函数和数组
shell之if条件语句case语句
mysql服务器参数设置总结
字符流Reader和Writer
pip管理软件命令
Getting to know the network layer
动态规划之数字n二进制位中1的个数
斐波那契序列,数组排序,在数组中查找对应元素Objects类的equals方法的作用,将26个英文字母用逗号分隔,组成字符串打印出来,矩阵的转置,找出1~1000之间的全部同构数,用随机数生成语句
office运行时错误,部分系统文件可能丢失或已损坏(错误代码:0x80040154)
ZTNA方案守住随时随地办公的安全防线
Red hat修改静态路由
科普:String hashCode 方法为什么选择数字 31 作为乘子
arcgis js 4.18新体验:阴影滤镜图层