当前位置:网站首页>卷积神经网络基础知识
卷积神经网络基础知识
2022-04-22 06:04:00 【亦岚君】
1 卷积神经网络是什么?
卷积神经网络(Convolution Neural Network)可以简单理解为包含卷积操作且具有深度结构的网络,通过权值共享和局部连接的方式对数据进行特征提取并进行预测的过程。在实际应用中往往采用多层网络结构,因此又被称为深度卷积神经网络。卷积神经网络通过反馈修正卷积核和偏置参数使输出与预测偏差减小。所以,构建卷积神经网络进行深度学习开发其实并不复杂。可以从四个方面展开:输入输出、网络结构、损失函数、评价指标。
2 卷积神经网络的输入输出
卷积神经网络的输入分为两部分,一是数据,二是标签。针对计算机视觉任务来说,通常数据指的是图像数据。标签是针对图像的真实值,针对不同任务有着不同的标签,例如图像分类任务的标签是图像的类别,目标检测任务的标签是图像中的目标的类别和坐标信息等。这类标签信息一般通过人工标定方式(或者自动标定工具)生成。例如VIA标注工具。
3、卷积神经网络的网络结构
卷积神经网络的基本结构由以下几个部分组成:输入层(input layer),卷积层(convolution layer),池化层(pooling layer),激活函数层和全连接层(full-connection layer)。下面以图像分类任务简单介绍一下卷积神经网络结构,具体结构如下图所示。

3.1 输入层
图像分类任务是输入层是 H ∗ W ∗ C H*W*C H∗W∗C的图像,其中H是指图像的长度,W是图像的宽度,C指的是图像的channel数,一般灰度图的channel数为1,彩色图的channel数为3。
3.2 卷积层
卷积神经网络的核心是卷积层,卷积层的核心部分是卷积操作。
卷积层有四个重要的超参数:卷积核的大小F、卷积核的个数K、卷积的步长S和零填充数量P。
假设输入的参数为: H × W × D H×W×D H×W×D的一个Tensor,则经过一个大小为、个数为K,步长为S和零填充数量为P的卷积操作后输出的参数为:
H ′ = ( H − F + 2 P ) / S + 1 W ′ = ( W − F + 2 P ) / S + 1 D ′ = K \begin{matrix}H' = (H-F+2P)/S+1 \\W' = (W-F+2P)/S+1 \\ D'=K \end{matrix} H′=(H−F+2P)/S+1W′=(W−F+2P)/S+1D′=K
关于卷积计算可以参考这篇文章,我的下面图片就引自该问文,链接: 原来卷积是这么计算的_月来客栈。
channel数为1的图像的单一卷积核的计算过程如下图所示:

具体计算过程如下图:

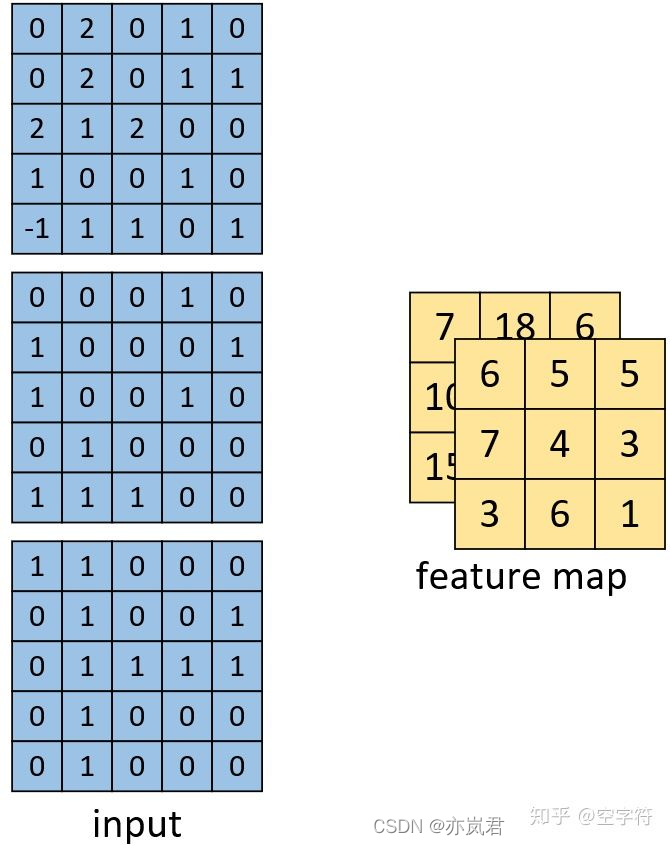
channel数为3的图像的单一卷积核的计算过程如下图所示:

具体计算过程如下图:

channel数为3的图像的多卷积核的计算过程如下图所示:
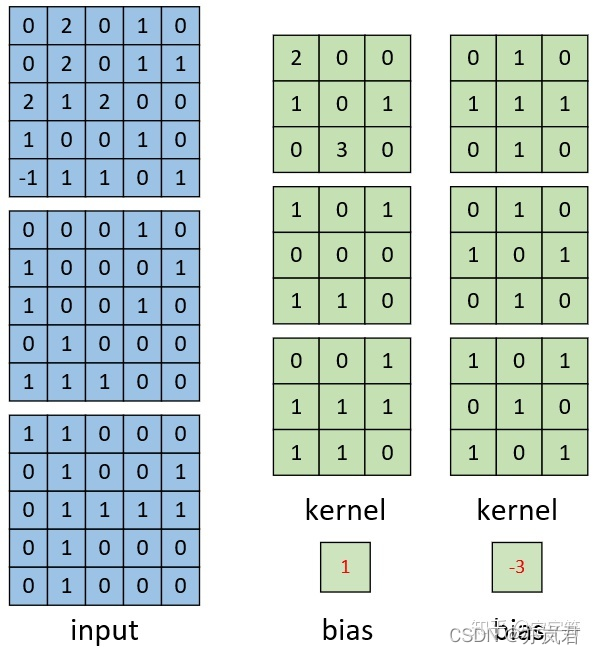
计算得到的结果如下图:
3.3 池化层
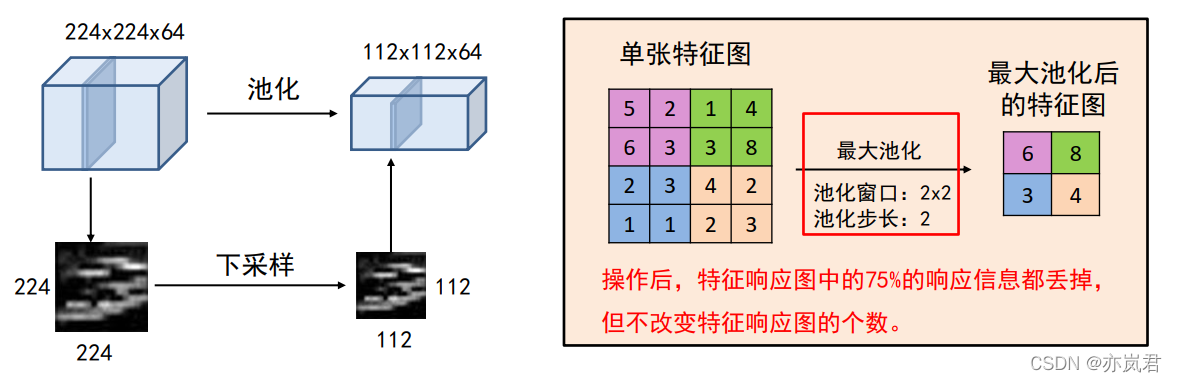
池化操作将输入矩阵某一位置相邻区域的总体统计特征作为该位置的输出,主要有平均池化(Average Pooling)、最大池化(Max Pooling)等。卷积的作用为:对每一个特征响应图独立进行, 降低特征响应图组中每个特征响应图的宽度和高度,减少后续卷积层的参数的数量, 降低计算资源耗费,进而控制过拟合,简单来说池化就是在该区域上指定一个值来代表整个区域。
池化层的超参数:池化窗口和池化步长。
池化操作也可以看做是一种卷积操作,下面我们以最大池化来解释池化操作,具体操作如下图所示:
3.4 激活函数层
激活函数一般用在卷积之后,使用激活函数可以得到输出值。常见的激活函数有Sigmoid、Softmax、Relu等。一般我们使用Relu作为卷积神经网络的激活函数。Relu激活函数公式定义为:
f ( u ) = m a x ( 0 , u ) f(u)= max(0,u) f(u)=max(0,u)
函数图像如下所示:

Relu激活函数相比Sigmoid、Softmax等有的优点为:
1、速度快,和sigmoid函数需要计算指数和倒数相比,relu函数其实就是一个 m a x ( 0 , u ) max(0,u) max(0,u),计算代价小。
2、稀疏性,通过对大脑的研究发现,大脑在工作的时候只有大约5%的神经元是激活的,而采用sigmoid激活函数的人工神经网络,其激活率大约是50%。有论文声称人工神经网络在15%-30%的激活率时是比较理想的。因为Relu函数在输入小于0时是完全不激活的,因此可以获得一个更低的激活率。
3.5 全连接层
全连接层在卷积神经网络中起到分类器的作用,如果说卷积层、池化层和激活函数层等操作是将原始数据映射到隐层特征空间的话,全连接层则起到将学到的“分布式特征表示”映射到样本标记空间的作用。
3 卷积神经网络的损失函数
在卷积神经网络中,我们会使用如梯度下降法(Gradient Descent) 等方法去最小化目标函数。但怎样来衡量优化目标函数的好坏呢,这就用到了损失函数。卷积神经网络中损失函数是用于衡量模型所作出的预测值和真实值(Ground Truth)之间的偏离程度,大致可分为两种:分类损失(针对离散型量)和回归损失(针对连续型变量)。
3.1分类损失
3.1.1 熵(Entropy)
即“熵”,熵的概念最早起源于物理学,用于度量一个热力学系统的无序程度。在信息论里面, 熵是用于描述对事件不确定性的度量,它的计算公式如下:
E n t r o p y , H ( p ) = − Σ p ( x i ) ∗ l o g 2 ( p ( x i ) ) Entropy,H(p) = -\varSigma p(x_i)*log_2(p(x_i)) Entropy,H(p)=−Σp(xi)∗log2(p(xi))
其中 p ( i ) p(i) p(i)为事件的概率分布,下面以一个例子来解释一下该公式。
假设气象台告知我们明天晴天的概率为25%,下雨的概率为75%,则气象站传输给我们的信息熵为:
− ( 0.25 ∗ l o g 2 ( 0.25 ) + 0.75 ∗ l o g 2 ( 0.75 ) ) = 0.81 -(0.25*log2(0.25) + 0.75*log2(0.75)) =0.81 −(0.25∗log2(0.25)+0.75∗log2(0.75))=0.81
如下图所示:

在卷积神经网络中,比如分类任务中,其实也是在做一个判断一个物体到底是不是属于某个类别,其中不确定性就越大,其信息量越大,它的熵值就越高。
3.1.2 相对熵
相对熵又称KL散度,用于衡量对于同一个随机变量x的两个分布p(x)和q(x)之间的差异。在机器学习中,p(x)常用于描述样本的真实分布,例如[1,0,0,0]表示样本属于第一类,而q(x)则常常用于表示预测的分布,例如[0.7,0.1,0.1,0.1]。显然使用q(x)来描述样本不如p(x)准确,q(x)需要不断地学习来拟合准确的分布p(x)。
KL散度的计算公式为:
D K L ( p ∣ ∣ q ) = ∑ i = 1 n p ( x i ) l o g 2 ( p ( x i ) q ( x i ) ) D_{KL}(p||q) = \displaystyle\sum_{i=1}^n p(x_i) log_2(\frac {p(x_i)} {q(x_i)}) DKL(p∣∣q)=i=1∑np(xi)log2(q(xi)p(xi))
KL散度的值越小表示两个分布越接近。
3.1.3 交叉熵(Cross Entropy)
我们将KL散度的公式进行变形,得到:
D K L ( p ∣ ∣ q ) = ∑ i = 1 n p ( x i ) l o g 2 ( p ( x i ) ) − ∑ i = 1 n p ( x i ) l o g 2 ( q ( x i ) ) = − H ( p ( x ) ) + [ − ∑ i = 1 n p ( x i ) l o g 2 ( q ( x i ) ) ] D_{KL}(p||q) = \displaystyle\sum_{i=1}^n p(x_i) log_2(p(x_i))- \displaystyle\sum_{i=1}^n p(x_i) log_2(q(x_i)) =-H(p(x))+[-\displaystyle\sum_{i=1}^n p(x_i) log_2(q(x_i))] DKL(p∣∣q)=i=1∑np(xi)log2(p(xi))−i=1∑np(xi)log2(q(xi))=−H(p(x))+[−i=1∑np(xi)log2(q(xi))]
前半部分就是p(x)的熵,它是一个定值,后半部分就是我们的交叉熵:
C r o s s E n t r o p y , H ( p , q ) = − ∑ i = 1 n p ( x i ) l o g 2 ( q ( x i ) ) Cross Entropy,H(p,q) = -\displaystyle\sum_{i=1}^n p(x_i) log_2(q(x_i)) CrossEntropy,H(p,q)=−i=1∑np(xi)log2(q(xi))
我们常常使用KL散度来评估predict和label之间的差别,但是由于KL散度的前半部分是一个常量,所以我们常常将后半部分的交叉熵作为损失函数。假设我们当前做一个3个类别的图像分类任务,如猫、狗、猪。给定一张输入图片其真实类别是猫,模型通过训练用Softmax分类后的输出结果为:{“cat”: 0.3, “dog”: 0.45, “pig”: 0.25},那么此时交叉熵为:-1 * log(0.3) = 1.203。当输出结果为:{“cat”: 0.5, “dog”: 0.3, “pig”: 0.2}时,交叉熵为:-1 * log(0.5) = 0.301。可以发现,当预测值接近真实值时,损失将接近0。
3.2 回归损失(Regression Loss)
3.2.1 L1损失
也称为Mean Absolute Error,即平均绝对误差(MAE),它衡量的是预测值与真实值之间距离的平均误差幅度,作用范围为0到正无穷。其公式如下:
l o s s = ∑ i = 1 n ∣ y i − y ^ i ∣ loss = \displaystyle\sum_{i=1}^n|y_i - \hat y_i| loss=i=1∑n∣yi−y^i∣
3.2.2 L2损失
也称为Mean Squred Error,即均方差(MSE),它衡量的是预测值与真实值之间距离的平方和,作用范围同为0到正无穷。其公式如下:
l o s s = ∑ i = 1 n ( y i − y ^ i ) 2 loss = \displaystyle\sum_{i=1}^n(y_i - \hat y_i)^2 loss=i=1∑n(yi−y^i)2
3.2.3 L1与L2损失函数对比
L1损失函数相比于L2损失函数的鲁棒性更好,因为L2将误差平方化(如果误差大于1,则误差会放大很多),模型的误差会比L1范数大的多,因此模型会对这种类型的样本更加敏感,这就需要调整模型来最小化误差。
但L2收敛速度快,能够对梯度给予合适的惩罚权重,而不是“一视同仁”,使梯度更新的方向可以更加精确。
3.2.4 Smooth L1损失
即平滑的L1损失(SLL),出自Fast RCNN。SLL通过综合L1和L2损失的优点,在0点处附近采用了L2损失中的平方函数,解决了L1损失在0点处梯度不可导的问题,使其更加平滑易于收敛。此外,在|x|>1的区间上,它又采用了L1损失中的线性函数,使得梯度能够快速下降。
s m o o t h L ( x ) = x = { 0.5 x 2 if ∣ x ∣ < 1 ∣ x ∣ − 0.5 otherwise smooth_L(x) = x = \begin{cases} 0.5x^2 &\text{if } |x|<1 \\ |x|-0.5 &\text{otherwise} \end{cases} smoothL(x)=x={
0.5x2∣x∣−0.5if ∣x∣<1otherwise
4 卷积神经网络的评价指标
评价指标是用来定量衡量模型的性能的,是作为各种模型比较的一个标准。卷积神经网络评价指标分为分类任务评价指标和回归任务评价指标。
4.1 分类任务评价指标
4.1.1 准确率/召回率/精确度/F1-score
混淆矩阵是最基础的概念,也是最重要的概念。混淆矩阵如下表所示:
| 正例(预测值) | 反例(预测值) | |
|---|---|---|
| 正例(真实值) | TP(True Positive) | FN(False Negative) |
| 反例(真实值) | FP(False Positive) | TN(True Negative) |
准确率(Accuracy):
A c c u r a c y = ( T P + T N ) ( T P + F N + F P + T N ) = 预 测 正 确 样 本 数 总 的 样 本 数 Accuracy = \frac {(TP+TN)} {(TP+FN+FP+TN)} = \frac {预测正确样本数}{总的样本数} Accuracy=(TP+FN+FP+TN)(TP+TN)=总的样本数预测正确样本数
精确度:
P r e c i s i o n = T P T P + F P = 预 测 正 确 的 正 样 本 数 预 测 为 正 的 样 本 数 Precision = \frac {TP}{TP+FP} =\frac {预测正确的正样本数}{预测为正的样本数} Precision=TP+FPTP=预测为正的样本数预测正确的正样本数
或
P r e c i s i o n = T N T N + F N = 预 测 正 确 的 正 样 本 数 预 测 为 负 的 样 本 数 Precision = \frac{TN}{TN+FN} =\frac {预测正确的正样本数}{预测为负的样本数} Precision=TN+FNTN=预测为负的样本数预测正确的正样本数
召回率:
R e c a l l = T P T P + F N = 预 测 正 确 的 正 样 本 数 真 实 标 签 为 正 确 的 样 本 数 Recall = \frac {TP}{TP+FN} = \frac {预测正确的正样本数}{真实标签为正确的样本数} Recall=TP+FNTP=真实标签为正确的样本数预测正确的正样本数
F1-score:
F 1 s c o r e = 2 ∗ P r e c i s i o n ∗ R e c a l l P r e c i s i o n + R e c a l l F1score = \frac {2*Precision*Recall }{Precision+Recall } F1score=Precision+Recall2∗Precision∗Recall
4.1.2 Precision/Recall(P-R)曲线
Precision/Recall曲线也叫做P-R曲线,其代表的是精准率(查准率)与召回率(查全率)的关系,Precision与Recall是一对矛盾的变量。如下图所示:
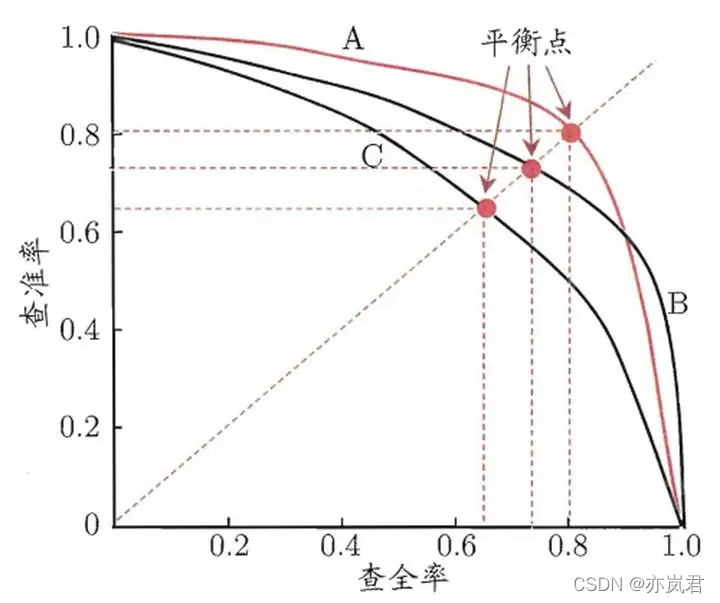
其中,曲线与坐标值面积越大,性能越好(能更大的提升精确度和召回率);但是有时面积不好计算,那么就选择 y = x y = x y=x与P-R曲线的交点也叫作平衡点(BEP)比较BEP,越大的学习器越优。
但PR曲线对正负样本不均衡问题较敏感。
4.1.3 ROC曲线
ROC曲线的横坐标是false positive rate(FPR):
F P R = F P F P + T N = 将 反 例 预 测 为 正 例 的 样 本 数 标 签 为 反 的 样 本 数 FPR = \frac {FP}{FP+TN} = \frac {将反例预测为正例的样本数}{标签为反的样本数} FPR=FP+TNFP=标签为反的样本数将反例预测为正例的样本数
纵坐标为true positive rate(TPR):
T P R = T P T P + F N = 将 正 例 预 测 为 正 例 的 样 本 数 标 签 为 正 的 样 本 数 TPR = \frac {TP}{TP+FN} = \frac {将正例预测为正例的样本数}{标签为正的样本数} TPR=TP+FNTP=标签为正的样本数将正例预测为正例的样本数
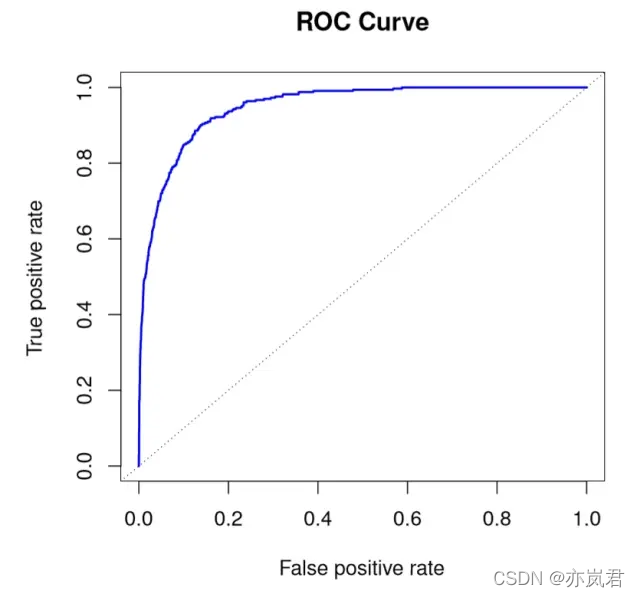
其中ROC曲线对正负样本不均衡问题不敏感。
4.2回归任务评价指标
4.2.1 IOU(Intersection-over-Union)交并比
IOU多用于检测、分割任务中,它的计算公式如下所示:
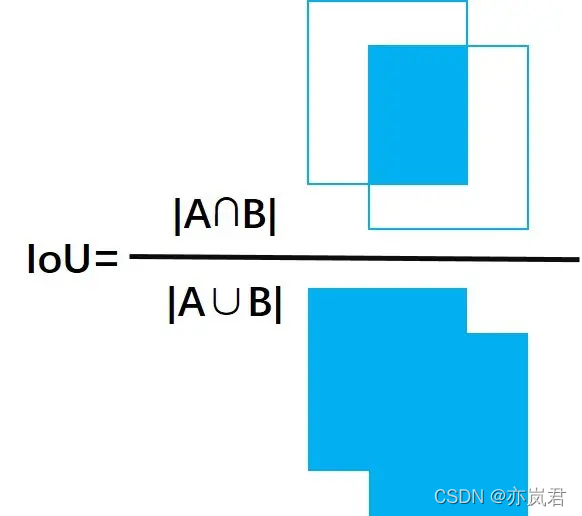
I O U = A ⋂ B A ⋃ B IOU = \frac {A \bigcap B}{A \bigcup B} IOU=A⋃BA⋂B
4.2.2 AP
PR曲线下的面积就定义为AP,由于计算积分相对困难,因此引入插值法,计算AP公式如下:
A P = ∑ k = 1 N max k ′ ≥ k P ( k ′ ) Δ r ( k ) AP= \displaystyle\sum_{k=1}^N \max _{ k' \geq k}P(k') \varDelta{ r(k)} AP=k=1∑Nk′≥kmaxP(k′)Δr(k)

计算面积:

计算公式:

5 总结
在这篇文章中,亦岚君首先引入了卷积的四个主要知识:输入输出、网络结构、损失函数和评价指标。然后围绕着这五个问题依次做了简单介绍。本次内容就到此结束,感谢您的阅读!如果你觉得上述内容对你有所帮助,欢迎关注并传播本文!

版权声明
本文为[亦岚君]所创,转载请带上原文链接,感谢
https://blog.csdn.net/weixin_44498476/article/details/124077446
边栏推荐
猜你喜欢

【AI视野·今日Robot 机器人论文速览 第三十期】Thu, 14 Apr 2022

The app enters for the first time and pops up the service agreement and privacy policy

数字图像处理第三版冈萨雷斯笔记第二章

Use of Excel IFS function

指定环境中安装matplotlib及bug解决

美团设置渠道包 walle 方式

多标签分类问题中的评价指标:准确率,交叉熵代价函数

隐藏在发表的宏基因组文章背后故事,如何发掘和学习

(4种)实现垂直居中的方法总结

【AI视野·今日Sound 声学论文速览 第一期】Thu, 14 Apr 2022
随机推荐
Win10下AI CC 2019安装教程(超级详细-小白版)
【AI视野·今日Robot 机器人论文速览 第三十期】Thu, 14 Apr 2022
PolarMask is not in the models registry
隐藏在发表的宏基因组文章背后故事,如何发掘和学习
druid--JDBC工具类案例
《深度学习》花书学习第一周
手把手教你一小时设计基于matlab的信号发生器GUI界面(2)
【AI视野·今日NLP 自然语言处理论文速览 第二十九期】Mon, 14 Feb 2022
短视频内容理解与生成技术在美团的创新实践
解决:AttributeError: module ‘yaml‘ has no attribute ‘CSafeLoader‘
How is the diversity of flora formed, the relationship with health, and how to improve it?
解决seq2seq+attention机器翻译中的技术小难题
比properties更好用的读配置文件的方式
2021年的最后一天,收获的一年。
Difference between canvas and SVG
Use of Excel vlookup function
com.alibaba.fastjson 常用方法
Nature Medicine 揭示冠状动脉疾病的个体危险因素
手把手教你腾讯云搭建RUOYI系统
知识图谱综述(二)