当前位置:网站首页>Li Mu hands-on learning deep learning V2-BERT fine-tuning and code implementation
Li Mu hands-on learning deep learning V2-BERT fine-tuning and code implementation
2022-08-03 20:11:00 【cv_lhp】
一.BERT微调
1.介绍
Natural language level of inference is a sequence of text categorization problem,而微调BERTOnly need one additional based on multilayer perceptron architecture for pre trainedBERTWeighting parameters fine-tuning,如下图所示.Below will download a small version of the pre trainedBERT,然后对其进行微调,以便在SNLIData set on natural language infer.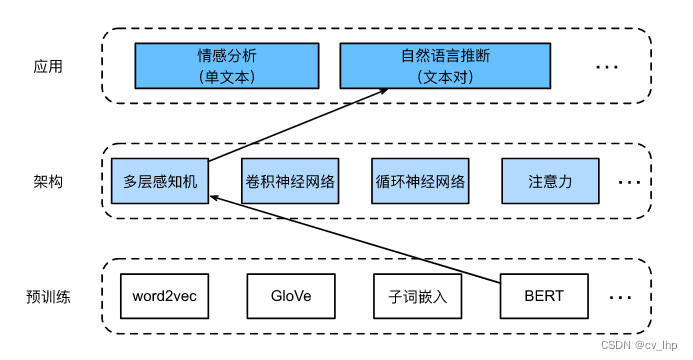
2.加载预训练的BERT
在前面博客BERT预训练第二篇:李沐动手学深度学习V2-bert预训练数据集和代码实现和 BERT预训练第三篇:李沐动手学深度学习V2-BERT预训练和代码实现This paper introduces the preliminary training ofBERT(注意原始的BERT模型是在更大的语料库上预训练的,原始的BERTModels have hundreds of millions of parameter).In the following offers two versions of pre trainingBERT:“bert.base”与原始的BERT基础模型一样大,需要大量的计算资源才能进行微调,而“bert.small”是一个小版本,以便于演示.
import os
import torch
from torch import nn
import d2l.torch
import json
import multiprocessing
d2l.torch.DATA_HUB['bert.base'] = (d2l.torch.DATA_URL + 'bert.base.torch.zip',
'225d66f04cae318b841a13d32af3acc165f253ac')
d2l.torch.DATA_HUB['bert.small'] = (d2l.torch.DATA_URL + 'bert.small.torch.zip',
'c72329e68a732bef0452e4b96a1c341c8910f81f')
两个预训练好的BERT模型都包含一个定义词表的“vocab.json”File and a preliminary trainingBERT参数的“pretrained.params”文件,load_pretrained_modelFunction is used to load previously trainedBERT参数.
def load_pretrained_model(pretrained_model,num_hiddens,ffn_num_hiddens,num_heads,num_layers,dropout,max_len,devices):
data_dir = d2l.torch.download_extract(pretrained_model)
# 定义空词表以加载预定义词表
vocab = d2l.torch.Vocab()
vocab.idx_to_token = json.load(open(os.path.join(data_dir,'vocab.json')))
vocab.token_to_idx = {
token:idx for idx,token in enumerate(vocab.idx_to_token)}
bert = d2l.torch.BERTModel(len(vocab),num_hiddens=num_hiddens,norm_shape=[256],ffn_num_input=256,ffn_num_hiddens=ffn_num_hiddens,num_heads=num_heads,num_layers=num_layers,dropout=dropout,max_len=max_len,key_size=256,query_size=256,value_size=256,hid_in_features=256,mlm_in_features=256,nsp_in_features=256)
# bert = nn.DataParallel(bert,device_ids=devices).to(devices[0])
# bert.module.load_state_dict(torch.load(os.path.join(data_dir,'pretrained.params')),strict=False)
# 加载预训练BERT参数
bert.load_state_dict(torch.load(os.path.join(data_dir,'pretrained.params')))
return bert,vocab
In order to facilitate in most machine demo,The following loading and fine-tuning after preliminary trainingBERT的小版本(“bert.mall”).
devices = d2l.torch.try_all_gpus()[2:4]
bert,vocab = load_pretrained_model('bert.small',num_hiddens=256,ffn_num_hiddens=512,num_heads=4,num_layers=2,dropout=0.1,max_len=512,devices=devices)
3. 微调BERT的数据集
对于SNLI数据集的下游任务自然语言推断,定义一个定制的数据集类SNLIBERTDataset.在每个样本中,前提和假设形成一对文本序列,并被打包成一个BERT输入序列,片段索引用于区分BERT输入序列中的前提和假设.利用预定义的BERT输入序列的最大长度(max_len),持续移除输入文本对中较长文本的最后一个标记,直到满足max_len.为了加速生成用于微调BERT的SNLI数据集,使用4个工作进程并行生成训练或测试样本.
class SNLIBERTDataset(torch.utils.data.Dataset):
def __init__(self,dataset,max_len,vocab=None):
all_premises_hypotheses_tokens = [[p_tokens,h_tokens] for p_tokens,h_tokens in zip(*[d2l.torch.tokenize([s.lower() for s in sentences]) for sentences in dataset[:2]])]
self.vocab = vocab
self.max_len = max_len
self.labels = torch.tensor(dataset[2])
self.all_tokens_id,self.all_segments,self.all_valid_lens = self._preprocess(all_premises_hypotheses_tokens)
print(f'read {len(self.all_tokens_id)} examples')
def _preprocess(self,all_premises_hypotheses_tokens):
pool = multiprocessing.Pool(4)# 使用4个进程
out = pool.map(self._mp_worker,all_premises_hypotheses_tokens)
all_tokens_id = [tokens_id for tokens_id,segments,valid_len in out]
all_segments = [segments for tokens_id,segments,valid_len in out]
all_valid_lens = [valid_len for tokens_id,segments,valid_len in out]
return torch.tensor(all_tokens_id,dtype=torch.long),torch.tensor(all_segments,dtype=torch.long),torch.tensor(all_valid_lens)
def _mp_worker(self,premises_hypotheses_tokens):
p_tokens,h_tokens = premises_hypotheses_tokens
self._truncate_pair_of_tokens(p_tokens,h_tokens)
tokens,segments = d2l.torch.get_tokens_and_segments(p_tokens,h_tokens)
valid_len = len(tokens)
tokens_id = self.vocab[tokens]+[self.vocab['<pad>']]*(self.max_len-valid_len)
segments = segments+[0]*(self.max_len-valid_len)
return (tokens_id,segments,valid_len)
def _truncate_pair_of_tokens(self,p_tokens,h_tokens):
# 为BERT输入中的'<CLS>'、'<SEP>'和'<SEP>'词元保留位置
while (len(p_tokens)+len(h_tokens))>self.max_len-3:
if len(p_tokens)>len(h_tokens):
p_tokens.pop()
else:
h_tokens.pop()
def __getitem__(self, idx):
return (self.all_tokens_id[idx],self.all_segments[idx],self.all_valid_lens[idx]),self.labels[idx]
def __len__(self):
return len(self.all_tokens_id)
下载完SNLI数据集后,通过实例化SNLIBERTDataset类来生成训练和测试样本,这些样本将在自然语言推断的训练和测试期间进行小批量读取.
#在原始的BERT模型中,max_len=512
batch_size,max_len,num_workers = 512,128,d2l.torch.get_dataloader_workers()
data_dir = d2l.torch.download_extract('SNLI')
train_set = SNLIBERTDataset(d2l.torch.read_snli(data_dir,is_train=True),max_len,vocab)
test_set = SNLIBERTDataset(d2l.torch.read_snli(data_dir,is_train=False),max_len,vocab)
train_iter = torch.utils.data.DataLoader(train_set,batch_size,num_workers=num_workers,shuffle=True)
test_iter = torch.utils.data.DataLoader(test_set,batch_size,num_workers=num_workers,shuffle=False)
4. BERT微调
**用于自然语言推断的微调BERT只需要一个额外的多层感知机,该多层感知机由两个全连接层组成,**与前面BERT实现的博客BERT预训练第一篇:李沐动手学深度学习V2-bert和代码实现中BERTClassifier类中进行nsp预测的self.hidden和self.outputThe multi-layer perceptron structure a.这个多层感知机将特殊的“”词元的BERT表示进行了转换,该词元同时编码前提和假设的信息,After a multilayer perceptron from natural language infer that the output of the classification feature d:蕴涵、矛盾和中性.
class BERTClassifier(nn.Module):
def __init__(self,bert):
super(BERTClassifier,self).__init__()
self.encoder = bert.encoder
self.hidden = bert.hidden
self.output = nn.Linear(256,3)
def forward(self,inputs):
tokens_X,segments_X,valid_lens_X = inputs
encoded_X = self.encoder(tokens_X,segments_X,valid_lens_X)
return self.output(self.hidden(encoded_X[:,0,:]))
The following will advance trainingBERT模型bertWas sent to used in the downstream applicationBERTClassifier实例net中.在BERTIn the common implementation of fine-tuning,Only additional multilayer perceptron(net.output)The parameters of the output layer will start from scratch to learn.预训练BERT编码器(net.encoder)和额外的多层感知机的隐藏层(net.hidden)All the parameters will be fine-tuning.
net = BERTClassifier(bert)
在BERT预训练中MaskLM类和NextSentencePred类在其使用的多层感知机中都有一些参数,这些参数是预训练BERT模型bertPart of the parameters in the,However, these parameters are used to calculate preliminary training under shading language model in the process of loss and forecast a loss.这两个损失函数与微调下游应用无关,因此当BERT微调时,MaskLM和NextSentencePred中采用的多层感知机的参数不会更新(陈旧的,staled).
通过d2l.train_batch_ch13()函数使用SNLI的训练集(train_iter)和测试集(test_iter)对net模型进行训练和评估,结果如下图所示.
lr,num_epochs = 1e-4,5
optim = torch.optim.Adam(params=net.parameters(),lr=lr)
loss = nn.CrossEntropyLoss(reduction='none')
d2l.torch.train_ch13(net,train_iter,test_iter,loss,optim,num_epochs,devices)

5. 小结
- In view of the downstream application for pre trainingBERT模型进行微调,例如在SNLIData set on natural language infer.
- 在微调过程中,BERTModel become a part of the downstream application model,Combined with multilayer perceptron to downstream application model training and assessment of the task.
6. 使用原始BERT的预训练模型进行微调
Fine-tuning a greater advance trainingBERT模型,该模型与原始的BERT基础模型一样大.修改load_pretrained_model函数中的参数设置:将“bert.mall”替换为“bert.base”,将num_hiddens=256、ffn_num_hiddens=512、num_heads=4和num_layers=2的值分别增加到768、3072、12和12,At the same time, modify the multilayer perceptron output layerLinear层为(nn.Linear(768,3),Because now, afterBERTModel output characteristic dimension into768),Increase the fine-tuning iterative round number,代码如下所示.
import os
import torch
from torch import nn
import d2l.torch
import json
import multiprocessing
d2l.torch.DATA_HUB['bert.base'] = (d2l.torch.DATA_URL + 'bert.base.torch.zip',
'225d66f04cae318b841a13d32af3acc165f253ac')
d2l.torch.DATA_HUB['bert.small'] = (d2l.torch.DATA_URL + 'bert.small.torch.zip',
'c72329e68a732bef0452e4b96a1c341c8910f81f')
devices = d2l.torch.try_all_gpus()
def load_pretrained_model1(pretrained_model,num_hiddens,ffn_num_hiddens,num_heads,num_layers,dropout,max_len,devices):
data_dir = d2l.torch.download_extract(pretrained_model)
vocab = d2l.torch.Vocab()
vocab.idx_to_token = json.load(open(os.path.join(data_dir,'vocab.json')))
vocab.token_to_idx = {
token:idx for idx,token in enumerate(vocab.idx_to_token)}
bert = d2l.torch.BERTModel(len(vocab),num_hiddens=num_hiddens,norm_shape=[768],ffn_num_input=768,ffn_num_hiddens=ffn_num_hiddens,num_heads=num_heads,num_layers=num_layers,dropout=dropout,max_len=max_len,key_size=768,query_size=768,value_size=768,hid_in_features=768,mlm_in_features=768,nsp_in_features=768)
# bert = nn.DataParallel(bert,device_ids=devices).to(devices[0])
# bert.module.load_state_dict(torch.load(os.path.join(data_dir,'pretrained.params')),strict=False)
bert.load_state_dict(torch.load(os.path.join(data_dir,'pretrained.params')))
return bert,vocab
bert,vocab = load_pretrained_model1('bert.base',num_hiddens=768,ffn_num_hiddens=3072,num_heads=12,num_layers=12,dropout=0.1,max_len=512,devices=devices)
class SNLIBERTDataset(torch.utils.data.Dataset):
def __init__(self, dataset, max_len, vocab=None):
all_premises_hypotheses_tokens = [[p_tokens, h_tokens] for p_tokens, h_tokens in
zip(*[d2l.torch.tokenize([s.lower() for s in sentences]) for sentences in
dataset[:2]])]
self.vocab = vocab
self.max_len = max_len
self.labels = torch.tensor(dataset[2])
self.all_tokens_id, self.all_segments, self.all_valid_lens = self._preprocess(all_premises_hypotheses_tokens)
print(f'read {len(self.all_tokens_id)} examples')
def _preprocess(self, all_premises_hypotheses_tokens):
pool = multiprocessing.Pool(4) # 使用4个进程
out = pool.map(self._mp_worker, all_premises_hypotheses_tokens)
all_tokens_id = [tokens_id for tokens_id, segments, valid_len in out]
all_segments = [segments for tokens_id, segments, valid_len in out]
all_valid_lens = [valid_len for tokens_id, segments, valid_len in out]
return torch.tensor(all_tokens_id, dtype=torch.long), torch.tensor(all_segments,
dtype=torch.long), torch.tensor(
all_valid_lens)
def _mp_worker(self, premises_hypotheses_tokens):
p_tokens, h_tokens = premises_hypotheses_tokens
self._truncate_pair_of_tokens(p_tokens, h_tokens)
tokens, segments = d2l.torch.get_tokens_and_segments(p_tokens, h_tokens)
valid_len = len(tokens)
tokens_id = self.vocab[tokens] + [self.vocab['<pad>']] * (self.max_len - valid_len)
segments = segments + [0] * (self.max_len - valid_len)
return (tokens_id, segments, valid_len)
def _truncate_pair_of_tokens(self, p_tokens, h_tokens):
# 为BERT输入中的'<CLS>'、'<SEP>'和'<SEP>'词元保留位置
while (len(p_tokens) + len(h_tokens)) > self.max_len - 3:
if len(p_tokens) > len(h_tokens):
p_tokens.pop()
else:
h_tokens.pop()
def __getitem__(self, idx):
return (self.all_tokens_id[idx], self.all_segments[idx], self.all_valid_lens[idx]), self.labels[idx]
def __len__(self):
return len(self.all_tokens_id)
#在原始的BERT模型中,max_len=512
batch_size, max_len, num_workers = 512, 128, d2l.torch.get_dataloader_workers()
data_dir = d2l.torch.download_extract('SNLI')
train_set = SNLIBERTDataset(d2l.torch.read_snli(data_dir, is_train=True), max_len, vocab)
test_set = SNLIBERTDataset(d2l.torch.read_snli(data_dir, is_train=False), max_len, vocab)
train_iter = torch.utils.data.DataLoader(train_set, batch_size, num_workers=num_workers, shuffle=True)
test_iter = torch.utils.data.DataLoader(test_set, batch_size, num_workers=num_workers, shuffle=False)
class BERTClassifier(nn.Module):
def __init__(self, bert):
super(BERTClassifier, self).__init__()
self.encoder = bert.encoder
self.hidden = bert.hidden
self.output = nn.Linear(768, 3)
def forward(self, inputs):
tokens_X, segments_X, valid_lens_X = inputs
encoded_X = self.encoder(tokens_X, segments_X, valid_lens_X)
return self.output(self.hidden(encoded_X[:, 0, :]))
net = BERTClassifier(bert)
lr, num_epochs = 1e-4, 20
optim = torch.optim.Adam(params=net.parameters(), lr=lr)
loss = nn.CrossEntropyLoss(reduction='none')
d2l.torch.train_ch13(net, train_iter, test_iter, loss, optim, num_epochs, devices)
7. 全部代码
import os
import torch
from torch import nn
import d2l.torch
import json
import multiprocessing
d2l.torch.DATA_HUB['bert.base'] = (d2l.torch.DATA_URL + 'bert.base.torch.zip',
'225d66f04cae318b841a13d32af3acc165f253ac')
d2l.torch.DATA_HUB['bert.small'] = (d2l.torch.DATA_URL + 'bert.small.torch.zip',
'c72329e68a732bef0452e4b96a1c341c8910f81f')
def load_pretrained_model(pretrained_model, num_hiddens, ffn_num_hiddens, num_heads, num_layers, dropout, max_len,
devices):
data_dir = d2l.torch.download_extract(pretrained_model)
# 定义空词表以加载预定义词表
vocab = d2l.torch.Vocab()
vocab.idx_to_token = json.load(open(os.path.join(data_dir, 'vocab.json')))
vocab.token_to_idx = {
token: idx for idx, token in enumerate(vocab.idx_to_token)}
bert = d2l.torch.BERTModel(len(vocab), num_hiddens=num_hiddens, norm_shape=[256], ffn_num_input=256,
ffn_num_hiddens=ffn_num_hiddens, num_heads=num_heads, num_layers=num_layers,
dropout=dropout, max_len=max_len, key_size=256, query_size=256, value_size=256,
hid_in_features=256, mlm_in_features=256, nsp_in_features=256)
# bert = nn.DataParallel(bert,device_ids=devices).to(devices[0])
# bert.module.load_state_dict(torch.load(os.path.join(data_dir,'pretrained.params')),strict=False)
# 加载预训练BERT参数
bert.load_state_dict(torch.load(os.path.join(data_dir, 'pretrained.params')))
return bert, vocab
devices = d2l.torch.try_all_gpus()[2:4]
bert, vocab = load_pretrained_model('bert.small', num_hiddens=256, ffn_num_hiddens=512, num_heads=4, num_layers=2,
dropout=0.1, max_len=512, devices=devices)
class SNLIBERTDataset(torch.utils.data.Dataset):
def __init__(self, dataset, max_len, vocab=None):
all_premises_hypotheses_tokens = [[p_tokens, h_tokens] for p_tokens, h_tokens in
zip(*[d2l.torch.tokenize([s.lower() for s in sentences]) for sentences in
dataset[:2]])]
self.vocab = vocab
self.max_len = max_len
self.labels = torch.tensor(dataset[2])
self.all_tokens_id, self.all_segments, self.all_valid_lens = self._preprocess(all_premises_hypotheses_tokens)
print(f'read {len(self.all_tokens_id)} examples')
def _preprocess(self, all_premises_hypotheses_tokens):
pool = multiprocessing.Pool(4) # 使用4个进程
out = pool.map(self._mp_worker, all_premises_hypotheses_tokens)
all_tokens_id = [tokens_id for tokens_id, segments, valid_len in out]
all_segments = [segments for tokens_id, segments, valid_len in out]
all_valid_lens = [valid_len for tokens_id, segments, valid_len in out]
return torch.tensor(all_tokens_id, dtype=torch.long), torch.tensor(all_segments,
dtype=torch.long), torch.tensor(
all_valid_lens)
def _mp_worker(self, premises_hypotheses_tokens):
p_tokens, h_tokens = premises_hypotheses_tokens
self._truncate_pair_of_tokens(p_tokens, h_tokens)
tokens, segments = d2l.torch.get_tokens_and_segments(p_tokens, h_tokens)
valid_len = len(tokens)
tokens_id = self.vocab[tokens] + [self.vocab['<pad>']] * (self.max_len - valid_len)
segments = segments + [0] * (self.max_len - valid_len)
return (tokens_id, segments, valid_len)
def _truncate_pair_of_tokens(self, p_tokens, h_tokens):
# 为BERT输入中的'<CLS>'、'<SEP>'和'<SEP>'词元保留位置
while (len(p_tokens) + len(h_tokens)) > self.max_len - 3:
if len(p_tokens) > len(h_tokens):
p_tokens.pop()
else:
h_tokens.pop()
def __getitem__(self, idx):
return (self.all_tokens_id[idx], self.all_segments[idx], self.all_valid_lens[idx]), self.labels[idx]
def __len__(self):
return len(self.all_tokens_id)
#在原始的BERT模型中,max_len=512
batch_size, max_len, num_workers = 512, 128, d2l.torch.get_dataloader_workers()
data_dir = d2l.torch.download_extract('SNLI')
train_set = SNLIBERTDataset(d2l.torch.read_snli(data_dir, is_train=True), max_len, vocab)
test_set = SNLIBERTDataset(d2l.torch.read_snli(data_dir, is_train=False), max_len, vocab)
train_iter = torch.utils.data.DataLoader(train_set, batch_size, num_workers=num_workers, shuffle=True)
test_iter = torch.utils.data.DataLoader(test_set, batch_size, num_workers=num_workers, shuffle=False)
class BERTClassifier(nn.Module):
def __init__(self, bert):
super(BERTClassifier, self).__init__()
self.encoder = bert.encoder
self.hidden = bert.hidden
self.output = nn.Linear(256, 3)
def forward(self, inputs):
tokens_X, segments_X, valid_lens_X = inputs
encoded_X = self.encoder(tokens_X, segments_X, valid_lens_X)
return self.output(self.hidden(encoded_X[:, 0, :]))
net = BERTClassifier(bert)
lr, num_epochs = 1e-4, 5
optim = torch.optim.Adam(params=net.parameters(), lr=lr)
loss = nn.CrossEntropyLoss(reduction='none')
d2l.torch.train_ch13(net, train_iter, test_iter, loss, optim, num_epochs, devices)
8. 相关链接
BERT预训练第一篇:李沐动手学深度学习V2-bert和代码实现
BERT预训练第二篇:李沐动手学深度学习V2-bert预训练数据集和代码实现
BERT预训练第三篇:李沐动手学深度学习V2-BERT预训练和代码实现
BERTFine-tune the first:李沐动手学深度学习V2-自然语言推断与数据集SNLI和代码实现
BERTThe second fine-tuning:李沐动手学深度学习V2-BERTFine-tuning and code implementation
边栏推荐
- ECCV2022 | 用于视频问题回答的视频图Transformer
- Line the last time the JVM FullGC make didn't sleep all night, collapse
- 机器学习中专业术语的个人理解与总结(纯小白)
- Node version switching tool NVM and npm source manager nrm
- 从文本匹配到语义相关——新闻相似度计算的一般思路
- Network protocol-TCP, UDP difference and TCP three-way handshake, four wave
- Go语言类型与接口的关系
- 按需视觉识别:愿景和初步方案
- The sword refers to Offer II 044. The maximum value of each level of the binary tree-dfs method
- RNA-ATTO 390|RNA-ATTO 425|RNA-ATTO 465|RNA-ATTO 488|RNA-ATTO 495|RNA-ATTO 520近红外荧光染料标记核糖核酸RNA
猜你喜欢

EMQX Newsletter 2022-07|EMQX 5.0 正式发布、EMQX Cloud 新增 2 个数据库集成

Internet Download Manager简介及下载安装包,IDM序列号注册问题解决方法

Alexa染料标记RNA核糖核酸|RNA-Alexa 514|RNA-Alexa 488|RNA-Alexa 430

微导纳米IPO过会:年营收4.28亿 君联与高瓴是股东

【STM32】标准库-自定义BootLoader

花 30 美金请 AI 画家弄了个 logo,网友:画得非常好,下次别画了!

开源生态研究与实践| ChinaOSC

149. 直线上最多的点数-并查集做法

简易电子琴设计(c语言)

头条服务端一面经典10道面试题解析
随机推荐
leetcode 125. 验证回文串
EMQX Newsletter 2022-07|EMQX 5.0 正式发布、EMQX Cloud 新增 2 个数据库集成
【飞控开发高级教程3】疯壳·开源编队无人机-定高、定点、悬停
tRNA-m5C转运RNA(tRNA)修饰5-甲基胞嘧啶(m5C)|tRNA修饰m1Am2A (2-methyladenosine)
leetcode 16.01. 交换数字(不使用临时变量交换2个数的值)
leetcode 899. 有序队列
阿洛的反思
xss.haozi练习通关详解
边缘盒子+时序数据库,美的数字化平台 iBuilding 背后的技术选型
charles配置客户端请求全部不走缓存
JMeter笔记5 |Badboy使用和录制
leetcode 461. 汉明距离
倒计时2天,“文化数字化战略新型基础设施暨文化艺术链生态建设发布会”启幕在即
Detailed AST abstract syntax tree
Line the last time the JVM FullGC make didn't sleep all night, collapse
JS 内置构造函数 扩展 prototype 继承 借用构造函数 组合式 原型式creat 寄生式 寄生组合式 call apply instanceof
花 30 美金请 AI 画家弄了个 logo,网友:画得非常好,下次别画了!
百利药业IPO过会:扣非后年亏1.5亿 奥博资本是股东
leetcode 2119. 反转两次的数字
多模态 参考资料汇总