当前位置:网站首页>Groupby use of spark operator
Groupby use of spark operator
2022-04-23 15:48:00 【Uncle flying against the wind】
Preface
groupBy, seeing the name of a thing one thinks of its function , That is the meaning of grouping , stay mysql in groupBy Often used , I believe many students are not strangers , As Spark One of the more commonly used operators in , It is necessary to deeply understand and learn ;
Function signature
def groupBy[K](f: T => K )(implicit kt: ClassTag[K]): RDD[(K, Iterable[T])]
Function description
Group data according to specified rules , By default, the partition remains unchanged , But the data will be Break up, regroup , We willThe operation of is called shuffle . In extreme cases , The data may be divided into the same partition
Additional explanation :
-
The data of a group is in a partition , But it's not that there is only one group in a partition
Case presentation I
Customize a collection , There are multiple strings in it , Group according to the first letter of each element
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.rdd.RDD
object Group_Test {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("Operator")
val sc = new SparkContext(sparkConf)
val rdd : RDD[String] = sc.makeRDD(List("Hello","spark","scala","Hadoop"))
val result = rdd.groupBy(_.charAt(0))
result.collect().foreach(println)
}
}

Case display II
As shown below , For a log file , Now you need to group by time , Count the quantity in each time period
import java.text.SimpleDateFormat
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.rdd.RDD
object Group_Test {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("Operator")
val sc = new SparkContext(sparkConf)
val rdd: RDD[String] = sc.textFile("E:\\code-self\\spi\\datas\\apache.log")
val result = rdd.map(
line => {
val datas = line.split(" ")
val time = datas(3)
val sdf = new SimpleDateFormat("dd/MM/yyyy:HH:mm")
val date = sdf.parse(time)
val sdf1 = new SimpleDateFormat("yyyy:HH")
val hour = sdf1.format(date)
(hour, 1)
}
).groupBy(_._1)
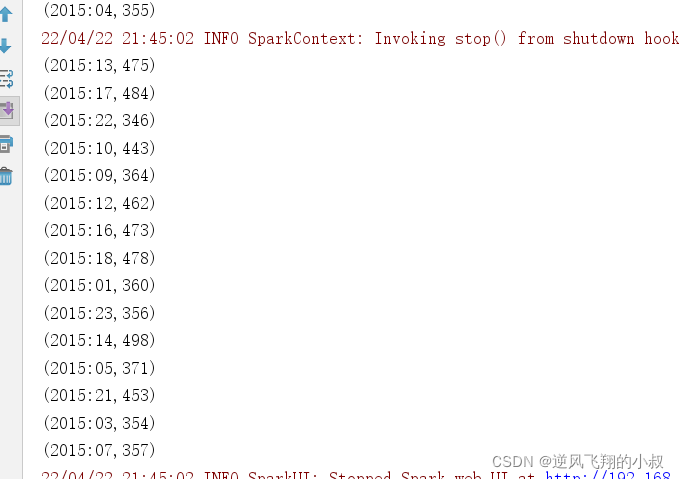
result.map {
case (hour, iter) => {
(hour, iter.size)
}
}.collect().foreach(println)
}
}
版权声明
本文为[Uncle flying against the wind]所创,转载请带上原文链接,感谢
https://yzsam.com/2022/04/202204231544587523.html
边栏推荐
猜你喜欢






随机推荐
One brush 312 - simple repetition set - Sword finger offer 03 Duplicate number in array (E)
Pytorch中named_parameters、named_children、named_modules函数
Best practices of Apache APIs IX high availability configuration center based on tidb
Codejock Suite Pro v20.3.0
贫困的无网地区怎么有钱建设网络?
ICE -- 源码分析
c语言---指针进阶
PHP classes and objects
s16. One click installation of containerd script based on image warehouse
腾讯Offer已拿,这99道算法高频面试题别漏了,80%都败在算法上
负载均衡器
[section 5 if and for]
Go语言数组,指针,结构体
携号转网最大赢家是中国电信,为何人们嫌弃中国移动和中国联通?
For examination
基础贪心总结
KNN, kmeans and GMM
pgpool-II 4.3 中文手册 - 入门教程
Demonstration meeting on startup and implementation scheme of swarm intelligence autonomous operation smart farm project
utils.DeprecatedIn35 因升级可能取消,该如何办