当前位置:网站首页>Making Pre-trained Language Models Better Few-Shot Learners
Making Pre-trained Language Models Better Few-Shot Learners
2022-08-10 17:23:00 【hithithithithit】
目录
Abstract
使用自然语言prompt和task demonstrations作为额外信息插入到输入文本中很好的利用了GPT-3模型中的知识。于是,本文提出少样本在小模型下的应用。我们的方法包括了基于prompt的微调,同时使用了自动生成的prompt;针对任务demonstration,我们还重新定义了一种动态和有选择地方法将其融入到上下文中。
Introduction
虽然GPT-3只使用提示和任务示例就可以在无需更新权重地情况下表现得很好,但是GPT-3模型很大,无法应用于现实中的场景进行微调。所以本文提出了在BERT等小模型上,仅使用少量的样本去对模型进行微调。作者从GPT-3中得到灵感,使用prompt和in-context同时对输入和输出进行优化,他们使用了暴力搜索去获得一些性能较好的回答词,并且使用T5去生成了提示模板,他们说这种方法很cheap?使用T5单独生成一个模板还cheap?由于输入长度的限制,他们对每个类找出一个好的demonstration。感觉没什么新意啊?GPT-3真就被抄 麻了!!!
Methods

label words
Gao et al. (2021)使用了未进行微调的预训练模型,得到最优的K个候选词,将其作为剪枝后的回答词空间。然后他们在此空间上进一步对模型在训练集上进行微调进行搜索得到n个较好的回答词。最后再根据验证集的结果得到一个最优的回答词。
Prompt template
Gao et al. (2021)把prompt模板生成的问题视为一个文本生成的任务,使用T5(Raffel et al, 2020)作为生成器模型。他们将原始输入和输出拼接起来作为T5(Raffel et al, 2020)模型的输入,然后他们使用了束搜索生成多个提示模板,经过在开发集上进行微调得到一个最好性能的提示模板,此外他们还使用了束搜索得到的提示模板用于集成模型的学习。

Demonstrations
不想看了,没意思,就是通过对每个类采样一个示例插入到输入中,参考GPT-3。
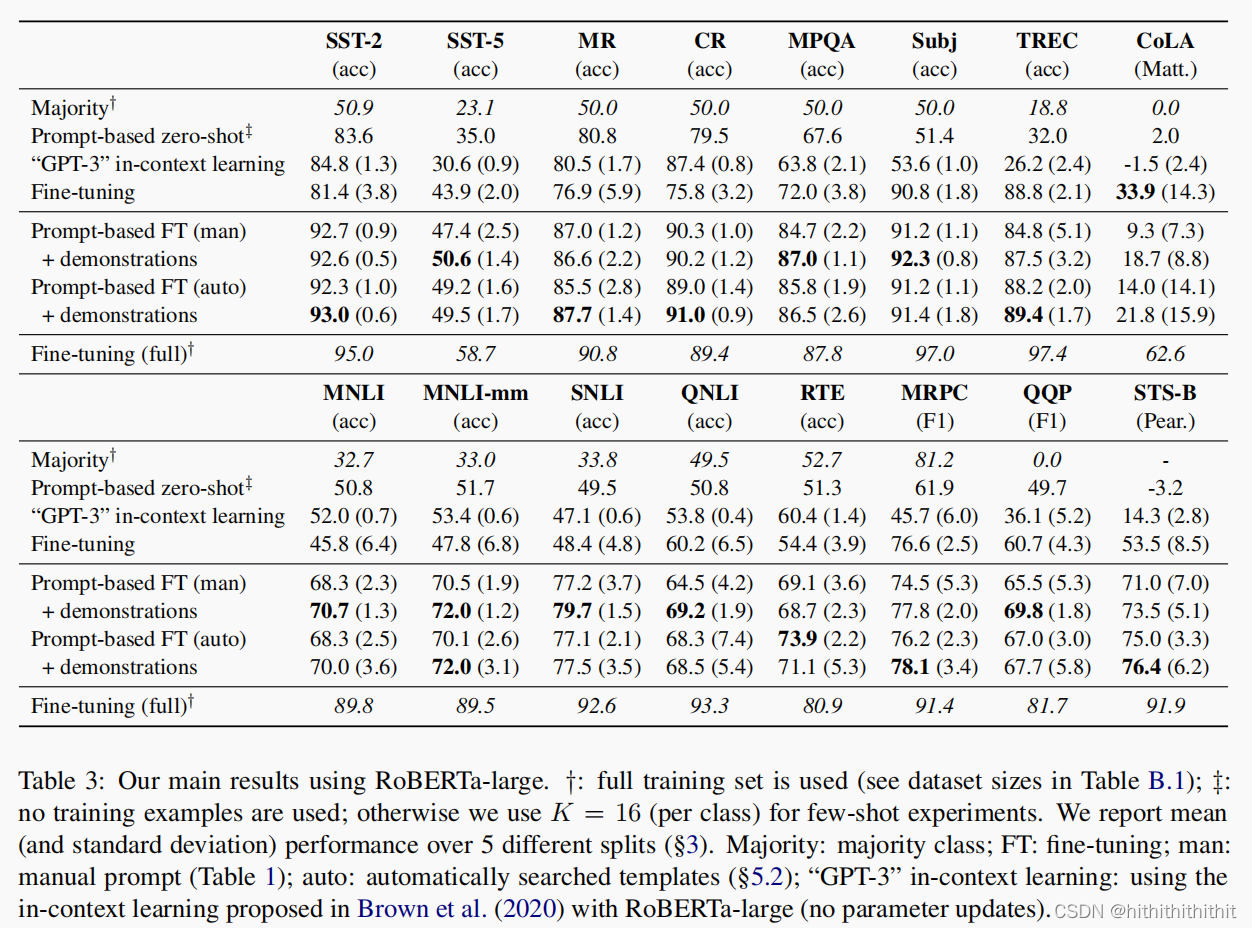
Experiments
倒是做了不少的实验,也算是还行吧,对这些数据集不太了解,自己看吧

边栏推荐
- node环境变量配置,npm环境变量配置
- HDLBits: 在线学习 SystemVerilog(零)-在线“巡礼” HDLBits
- 神经网络全连接层的作用,各种神经网络的优缺点
- PS2手柄通讯协议解析—附资料和源码「建议收藏」
- shell获取前n天的日期
- 《安富莱嵌入式周报》第277期:业界首款Cortex-M55+Ethos-U55 NPU套件发布,20个墨水屏菊花链玩法,氙气灯镇流器设计
- 建筑施工员证怎么考?报名条件及报考时间是什么?
- C:枚举的优缺
- R语言ggplot2可视化:使用ggpubr包的ggscatter函数可视化分组散点图、stat_mean函数在分组数据点外侧绘制凸包并突出显示分组均值点、自定会均值点的大小以及透明度
- aliexpress API 接入说明
猜你喜欢






随机推荐
leetcode:337. 打家劫舍 III
640. 求解方程
【接入指南 之 直接接入】手把手教你快速上手接入HONOR Connect平台(中)
router.afterEach()
如何学习性能测试?
DeamNet代码学习||网络框架核心代码 逐句查找学习
skywalking vulnerability learning
docker中安装mysql
轮询以及webSocket与socket.io原理
同一块中出现两个 * 就不能正常显示
excel-方方格子插件-正则表达式,快速清洗数据的方法
神经网络有哪些激活函数,卷积神经网络有哪些
MogDB学习笔记-从2开始(MogHA)
node环境变量配置,npm环境变量配置
重庆新壹汽与一汽集团达成新能源项目战略合作,赋能“碳中和”创造“碳财富”
leetcode:1013. 将数组分成和相等的三个部分
redis分布式锁
win11安装deepin20.6双系统(双硬盘)
烟雾、空气质量、温湿度…自己徒手做个环境检测设备
Error creating bean with name ‘sqlSessionFactory‘ defined in class path reso「建议收藏」