当前位置:网站首页>(路透社数据集)新闻分类:多分类问题实战
(路透社数据集)新闻分类:多分类问题实战
2022-08-07 14:46:00 【ㄣ知冷煖*】
目录
前言
对于路透社数据集的评论分类实战一、电影评论分类实战
1-1、数据集介绍&数据集导入&分割数据集
from keras.datasets import reuters
# 加载路透社数据集,包含许多短新闻及其对应的主题,它包含46个不同的主题。
# 加载数据:训练数据、训练标签;测试数据、测试标签。
# 将数据限定为前10000个最常出现的单词。
(train_data, train_labels), (test_data, test_labels) = reuters.load_data(num_words=10000)
# 查看训练数据
train_data[0:2]
输出:可以看到单词序列已经被转化为了整数序列,否则的话我们还需要手动搭建词典并且将其转化为整数序列。
1-2、字典的键值对颠倒&数字评论解码
# 将单词映射为整数索引的字典。
word_index = reuters.get_word_index()
# 键值颠倒,将整数索引映射为单词。
# 颠倒之后,前边是整数索引,后边是对应的单词。
reverse_word_index = dict(
[(value, key) for (key, value) in word_index.items()])
# 将评论解码,注意,索引减去了3,是因为0、1、2是特殊含义的字符。
decoded_review = ' '.join(
# 根据整数索引,查找对应的单词,然后使用空格来进行连接,如果没有找到相关的索引,那就用问号代替
[reverse_word_index.get(i - 3, '?') for i in train_data[0]])
# 看一下颠倒后的词典
print(reverse_word_index)
# 查看一下解码后的评论
print(decoded_review)
输出reverse_word_index:
输出decoded_review:

1-3、将整数序列转化为张量(训练数据和标签)
import numpy as np
def vectorize_sequences(sequences,dimension=10000):
"""
将整数序列转化为二进制矩阵的函数
"""
results = np.zeros((len(sequences), dimension))
for i, sequences in enumerate(sequences):
# 相应列上的元素置为1,其他位置上的元素都为0。
results[i, sequences] = 1
return results
# 这里只是预处理的一种方式,即单词序列编码为二进制向量,当然也可以采用其他方式,
# 比如说直接填充列表,然后使其具有相同的长度,然后将其转化为张量,并且网络第一层使用能够处理这种整数张量的层,即Embedding层。
# 训练数据向量化,即将其转化为二进制矩阵
x_train = vectorize_sequences(train_data)
x_test = vectorize_sequences(test_data)
# 将每个标签表示为全零向量,只有标签索引对应的元素为1
from keras.utils.np_utils import to_categorical
# keras内置这种转化方法,原理的话,与上边将整数序列转化为二进制矩阵的函数没有差别,唯一的不同是传入的维度是46,而不是10000。
one_hot_train_labels = to_categorical(train_labels)
one_hot_test_labels = to_categorical(test_labels)
# 查看一下训练集
print(one_hot_test_labels[0])
# 查看x_train
print(x_train)
输出one_hot_test_labels[0]:
输出x_train:
1-4、搭建神经网络&选择损失函数和优化器&划分出验证集
units = 64
from keras import models
from keras import layers
model = models.Sequential()
model.add(layers.Dense(units, activation='relu', input_shape=(10000,)))
model.add(layers.Dense(units, activation='relu'))
# 因为这里是46个类别,所以最后一层激活函数使用softmax,即对于每个输入样本,网络都会输出一个46维的向量,这个向量的每个元素代表不同的输出类别
model.add(layers.Dense(46, activation='softmax'))
# one-hot编码标签对应categorical_crossentropy(分类交叉熵损失函数)
# 标签直接转化为张量对应sparse_categorical_crossentropy(稀疏交叉熵损失)
model.compile(
optimizer='rmsprop',
# 这类问题的损失一般都会使用分类交叉熵损失函数。
loss = 'categorical_crossentropy',
metrics = ['accuracy']
)
x_val = x_train[:1000]
partial_x_train = x_train[1000:]
y_val = one_hot_train_labels[:1000]
partial_y_train = one_hot_train_labels[1000:]
1-5、开始训练&绘制训练损失和验证损失&绘制训练准确率和验证准确率
epochs = 10
history = model.fit(
partial_x_train,
partial_y_train,
epochs=epochs,
batch_size=512,
validation_data=(x_val, y_val)
)
训练过程:
绘制训练损失和验证损失:
import plotly.express as px
import plotly.graph_objects as go
history_dic = history.history
loss_val = history_dic['loss']
val_loss_values = history_dic['val_loss']
# epochs = range(1, len(loss_val)+1)
# np.linspace:作为序列生成器, numpy.linspace()函数用于在线性空间中以均匀步长生成数字序列
# 左闭右闭,所以是从整数1到20.
# 参数:起始、结束、生成的点
epochs = np.linspace(1, epochs, epochs)
fig = go.Figure()
# Add traces
fig.add_trace(go.Scatter(x=epochs, y=loss_val,
mode='markers',
name='Training loss'))
fig.add_trace(go.Scatter(x=epochs, y=val_loss_values,
mode='lines+markers',
name='Validation loss'))
fig.show()
输出: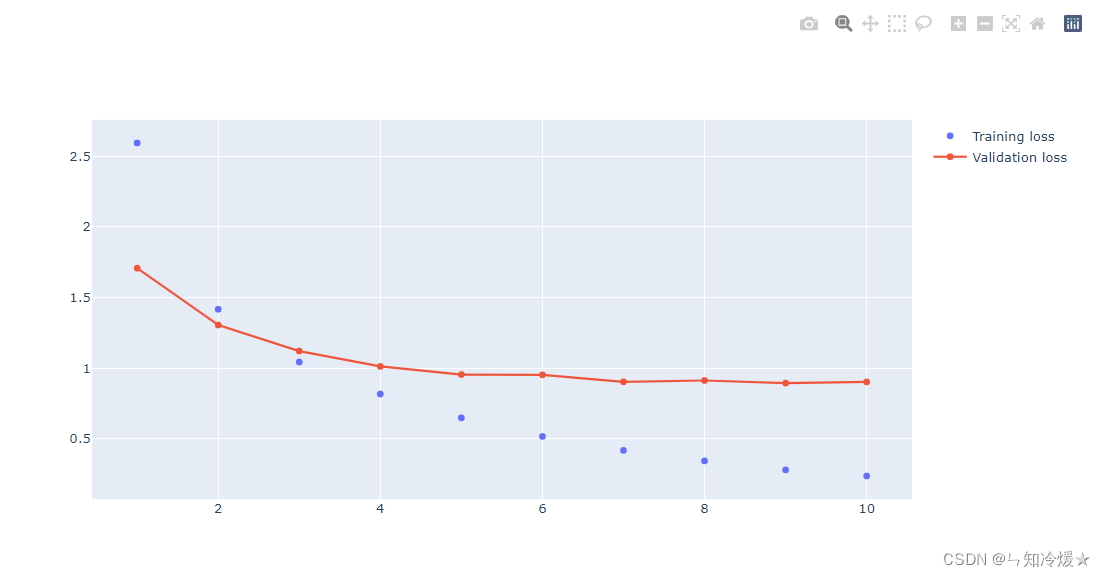
绘制训练准确率和验证准确率:
acc = history_dic['accuracy']
val_acc = history_dic['val_accuracy']
fig = go.Figure()
# Add traces
fig.add_trace(go.Scatter(x=epochs, y=acc,
mode='markers',
name='Training acc'))
fig.add_trace(go.Scatter(x=epochs, y=val_acc,
mode='lines+markers',
name='Validation acc'))
fig.show()
输出:
1-6、在测试集上验证准确率
# 两层、64个隐藏单元
# 训练轮次:20 损失:1.22 准确率:0.78
# 训练轮次:10 损失:0.96 准确率:0.79
# 训练轮次:9 损失:1.00 准确率:0.77
# 训练轮次:6 损失:1.01 准确率:0.77
# 两层、128个隐藏单元
# 训练轮次:20 损失:1.31 准确率:0.77
# 训练轮次:4 损失:0.97 准确率:0.78
# 注意:准确率会浮动,一般在0.2的范围内浮动。
model.evaluate(x_test, one_hot_test_labels)

二、调参总结
调参总结:
1、训练轮次:先选择较大的轮次,一般设置为20,观察数据在验证集上的表现,训练是为了拟合一般数据,所以当模型在验证集上准确率下降时,那就不要再继续训练了。
2、隐藏单元设置:二分类选择较小的单元数,如果是多分类的话,可以试着设置较大的单元数,比如说64、128等。
3、隐藏层数设置:同隐藏单元的设置规则,这里设置的层数较少,如果数据复杂,可以多加几层来观察数据的整体表现。
4、标签直接设置为one-hot编码时,则对应设置损失为categorical_crossentropy(分类交叉熵损失函数),若标签直接转化为张量,则对应设置损失为sparse_categorical_crossentropy(稀疏交叉熵损失)。
三、碎碎念(绘制3D爱心代码)
# 刚打开csdn看到一个绘制3D爱心的代码,于是我直接白嫖过来。
import numpy as np
import wxgl.glplot as glt
a = np.linspace(0, 2*np.pi, 500)
b = np.linspace(0.5*np.pi, -0.5*np.pi, 500)
lons, lats = np.meshgrid(a, b)
w = np.sqrt(np.abs(a - np.pi)) * 2
x = 2 * np.cos(lats) * np.sin(lons) * w
y = -2 * np.cos(lats) * np.cos(lons) * w
z = 2 * np.sin(lats)
glt.mesh(x, y, z, color='crimson') # crimson - 绯红
glt.show()
输出:
总结
七夕不快乐,呱呱呱。
边栏推荐
- [YOLOv7] Combined with GradCAM heat map visualization
- 深度之眼(二十一)——概率论
- up to date!A summary of all Kaggle competition open source solutions and Top ideas, a total of 477 competitions!
- 001_微服务框架学习分类总结
- Postgresql logical backup tool pg_dump and pg_resotre learning
- 处理乱码的问题oracle字符集WE8MSWIN1252和WE8ISO8859P1
- Acwing/3359. 更多奇怪的照片
- 联盛德W801系列1-flash保存数据例程:保存wifi配网信息
- 【数据库系统原理】第四章 高级数据库模型:E/R模型及其设计规则、约束
- 004_Eureka注册中心
猜你喜欢

Next Generation Wireless LAN - High Throughput

小程序基础——全局配置_pages
视觉SLAM十四讲(高翔版本),ch1-2章节部分笔记

C专家编程 第8章 为什么程序员无法分清万圣节和圣诞节 8.7 用C语言实现有限状态机

LeetCode hot topic HOT 100 (10. Delete the Nth node from the bottom of the linked list)

触摸屏如何利用无线PPI通信模块远程采集PLC数据?

哈希表 | 三数之和、四数之和 | 用`双指针法`最合适 | leecode刷题笔记

Threads of control and synchronization

MySQL: Calculate shortest distance between latitude and longitude using custom function

The ADC external RC circuit resistance and capacitance selection calculation method
随机推荐
Lianshengde W801 series 2-WIFI one-key distribution network, information preservation
LeetCode 热题 HOT 100(10.删除链表的倒数第 N 个结点)
Visual studio 创建项目失败vstemplate
003_服务拆分和远程调用【注册RestTemplate】
云信小课堂 | 基于 NERoom 快速实现在线会议
【Electrical Engineering (Part 2)】Organization of some basic concepts
Is it safe to use Tongdaxin software to buy stocks?
dotnet 通过 WMI 拿到显卡信息
【电工学(下)】部分基础概念整理
mysql查询表中最后一条数据
使用通达信炒股,资金能保证安全吗?
C语言文件输入输出(12)
自定义视频播放器
想交易场内基金去哪个证券公司开户更快更安全
牛客面试高频榜单(第二组)难度:简单&中等
【数据库系统原理】第四章 高级数据库模型:弱实体集、E/R 联系到关系的转化、子类结构到关系的转化
自动化测试、测试左移、精准测试,一次性说透
Summary of the open surface
联盛德W801系列4-MQTT使用
Hash table | 1. The sum of two numbers, 454. The addition of four numbers | The most suitable `dictionary key-value` | leecode brush the notes