当前位置:网站首页>[pytorch image classification] alexnet network structure
[pytorch image classification] alexnet network structure
2022-04-22 02:01:00 【Stephen-Chen】
Catalog
LRN:Local Response Normalization
1、 Preface
AlexNet yes 2012 year ISLVRC2012 (Image Large Scale Visual Recognition Challenge) Champion network of competition , The original paper is ImageNet Classification with Deep Convolutional Neural Networks.
At that time, the traditional algorithm had reached the performance bottleneck , However AlexNet The classification accuracy is changed from the traditional 70%+ Upgrade to 80%+. It is from Hinton And his students Alex Krizhevsky The design of the . That is, after that year , From year to year ImageNet LSVRC Challenges are dominated by deep learning models , Deep learning began to develop rapidly .
notes :ISLVRC2012 It includes the following three parts :
- Training set :1281167 Marked picture
- Verification set :50000 Marked picture
- Test set :100000 An unmarked picture
2、 Network innovation
Use... For the first time GPU Network acceleration training , Two pieces of GPU Parallel operation
Use ReLU Activation function , instead of sigmoid perhaps Tanh,
LRN Normalize the local features , As a result ReLU The input of activation function can effectively reduce the error rate
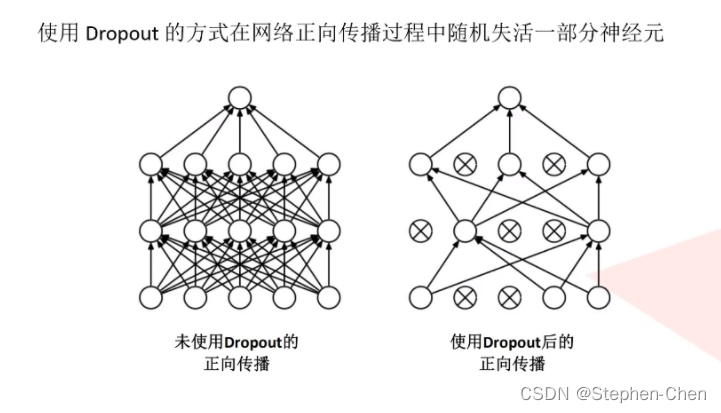
The front connecting layer of the whole connecting layer uses Dropout Randomly inactivated neurons operate , Prevent over fitting
Over fitting :

LRN:Local Response Normalization
yes AlexNet The normalization method first introduced in , But in BatchNorm Since then, this method has rarely been used , Here is a brief understanding of its concept


normalization
(1) For the convenience of later data processing , Normalization can indeed avoid some unnecessary numerical problems .
(2) In order to speed up the convergence of program runtime . The following diagram .
(3) The same dimension . The evaluation criteria of sample data are different , It needs to be dimensioned , Unified evaluation criteria . This is an application level requirement .
(4) Avoid neuronal saturation . What do you mean by that? ? When the activation of neurons is approaching 0 perhaps 1 It will be saturated , In these areas , The gradient is almost 0, this sample , In the process of back propagation , The local gradient will approach 0, This will effectively “ Kill ” gradient .
(5) Ensure that small values in the output data are not swallowed .
3、 Network structure chart :

Conv1:
input_Size : [224,224,3]
kernels:48*2=96
Kernel_size:11
stride:4
padding :[1,2] ( Up and down 1 Column 0, about 2 Column 0) By reasoning The reason for this is that there are decimals calculated by the following formula
output_size:[55,55,96]

Maxpool1:
Only change the height and width of the feature layer , Depth does not change
input_Size : [55,55,96] Kernel_size:3 padding =0 stride = 2 output_size: [27,27,96]

Conv2:
input_Size : [27,27,96] kernels:128*2=256 Kernel_size:5 padding = [2,2] stride = 1 output_size: [27,27,256]

Conv3:
input_Size : [13,13,256] kernels:128*2=192*2 Kernel_size:3 padding = [1,1] stride = 1 output_size: [13,13,384]

Conv4:
input_Size : [13,13,384] kernels:128*2=192*2 Kernel_size:3 padding = [1,1] stride = 1 output_size: [13,13,384]
Conv5:
input_Size : [13,13,384] kernels:128*2=128*2 =256 # Output channel Kernel_size:3 padding = [1,1] stride = 1 output_size: [13,13,256]
Maxpool3 :
input_Size : [13,13,256] kernels:128*2=256 Kernel_size:3 padding = 0 stride = 2 output_size: [6,6,256]

4. Code implementation
import torch
from torch import nn
from torch.nn import Flatten
class AlexNet(nn.Module):
def __init__(self,num_class=1000,init_weight=False):
super(AlexNet,self).__init__()
self.features = nn.Sequential(
nn.Conv2d(in_channels=3,out_channels=48,kernel_size=11,stride=4,padding=2), # input[3, 224, 224] output[48, 55, 55]
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3,stride=2) ,
nn.Conv2d(in_channels=48,out_channels=128,kernel_size=5,padding=2),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3,stride=2),
nn.Conv2d(in_channels=128,out_channels=192,kernel_size=3,padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(in_channels=192,out_channels=192,kernel_size=3,padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(in_channels=192,out_channels=128,kernel_size=3,padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3,stride=2),
)
self.classifier = nn.Sequential(
nn.Dropout(p=0.5),
nn.Linear(128*6*6 , 2048),
nn.ReLU(inplace=True),
nn.Dropout(p=0.5),
nn.Linear(2048,2048),
nn.ReLU(inplace=True),
nn.Linear(2048,num_class),
)
if init_weight:
self._initialize_weights()
def forward(self,x):
x = self.features(x)
# self.flatten = nn.Flatten(start_dim=1,end_dim=-1) #0 Weishi batch_size, So don't flatten , That is, flatten from the second dimension
# x = self.flatten(x)
# print(x.size())
x = torch.flatten(x, start_dim=1)
x = self.classifier(x)
return x
def _initialize_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
if m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
nn.init.normal_(m.weight, 0, 0.01)
nn.init.constant_(m.bias, 0)
5. summary
AlexNet Architecture and LeNet be similar , But more convolution layers and more parameters are used to fit large-scale ImageNet Data sets .
today ,AlexNet It has been surpassed by more effective Architecture , But it is a key step from shallow network to deep network .
Even though AlexNet Your code is only better than LeNet A few more lines , But it took many years for academia to accept the concept of deep learning , And apply its excellent experimental results . This is also due to the lack of effective calculation tools .
Dropout、ReLU And preprocessing are other key steps to improve the performance of computer vision tasks .
版权声明
本文为[Stephen-Chen]所创,转载请带上原文链接,感谢
https://yzsam.com/2022/04/202204220155555010.html
边栏推荐
- [DFS] [pruning] Sudoku (simple version)
- Leetcode1470. 重新排列数组
- Mysql-if-then-else statement
- What smart contract? Principle analysis of DAPP contract system customization technology
- Basic operation of MySQL database ------ (basic addition, deletion, query and modification)
- NLP模型小总结
- 【物联网开发笔记】机智云设备移植RT-Thread
- [编程题]有趣的数字
- Raspberry pie 4B 8g installation log (3) - Programming Environment
- SSLHandshakeException
猜你喜欢

Leetcode1470. 重新排列数组

Ultimate doll 2.0 | observable practice sharing of cloud native PAAS platform

Command line automatic error correction command: fuck

Raspberry pie 4B 8g installation log (3) - Programming Environment

【DFS】【剪枝】小猫爬山

Stack and queue

Mysql database fields move up and down

Bsides-vancouver-2018-workshop target penetration test

Vscode failed to use SSH Remote Connection

What is the role of proxy IP in the Internet?
随机推荐
From the test results of full memory, full local disk cache, half cache and half OSS, what are the conclusions?
Analyticdb PostgreSQL's new version of cloud native allows users to focus on business. What kind of experience upgrade does it achieve?
Xu Yuandong was invited to share "Ltd digital business methodology" at Shanghai Management Technology Forum
QT程序打包成一个exe可执行文件
Hj5 binary conversion
B树和B+树的区别
HJ5 进制转换
NLP模型小总结
Common evaluation indexes of medical image segmentation
Leetcode 386. Number of dictionary rows
最长公共子串
Profiteering method of blind box project
3D立体相册模板(大小可更改)
Thief, the latest Android interview collection
DEJA_ Vu3d - cesium feature set 012 - military plotting Series 6: Custom polygons
Redis cache database uses redis shake for data synchronization
Mysql-if-then-else statement
C# 从数据库读取数据, 导出到CSV
(counting line segment tree) lintcode medium 248 · count the number of numbers smaller than a given integer
Ultimate doll 2.0 | observable practice sharing of cloud native PAAS platform