当前位置:网站首页>神经网络样本太少怎么办,神经网络训练样本太少
神经网络样本太少怎么办,神经网络训练样本太少
2022-08-10 06:50:00 【aifans_bert】

以下那些分类算法可以较好地避免样本不平衡问题A KNN BSVM C Bayes D神经网络 答案选A,求解释
。
KNN只是取了最近的几个样本点做平均而已,离预测数据较远的训练数据对预测结果不会造成影响,但是svm、Bayes和NN每一个训练样本果都会对预测结果产生影响,于是如果样本不平衡的话KNN的效果最好,举个极端一点例子:答案只有A与B,但是训练样本中A的个数占99%,而B只有1%,svm、Bayes和NN训练出来的结果,恐怕预测任何数据给出的答案都是A,但是KNN不会。
神经网络,训练样本500条,为什么比训练样本6000条,训练完,500条预测比6000条样本好!
并非训练样本越多越好,因课题而异rbsci。1、样本最关键在于正确性和准确性。你所选择的样本首先要能正确反映该系统过程的内在规律。
我们从生产现场采得的样本数据中有不少可能是坏样本,这样的样本会干扰你的神经网络训练。通常我们认为坏样本只是个别现象,所以我们希望通过尽可能大的样本规模来抵抗坏样本造成的负面影响。
2、其次是样本数据分布的均衡性。你所选择的样本最好能涉及到该系统过程可能发生的各种情况,这样可以极大可能的照顾到系统在各个情况下的规律特征。
通常我们对系统的内在规律不是很了解,所以我们希望通过尽可能大的样本规模来“地毯式”覆盖对象系统的方方面面。3、再次就是样本数据的规模,也就是你要问的问题。
在确保样本数据质量和分布均衡的情况下,样本数据的规模决定你神经网络训练结果的精度。样本数据量越大,精度越高。
由于样本规模直接影响计算机的运算时间,所以在精度符合要求的情况下,我们不需要过多的样本数据,否则我们要等待很久的训练时间。
补充说明一下,不论是径向基(rbf)神经网络还是经典的bp神经网络,都只是具体的训练方法,对于足够多次的迭代,训练结果的准确度是趋于一致的,方法只影响计算的收敛速度(运算时间),和样本规模没有直接关系。
如何确定何时训练集的大小是“足够大”的?
神经网络的泛化能力主要取决于3个因素:1.训练集的大小2.网络的架构3.问题的复杂程度一旦网络的架构确定了以后,泛化能力取决于是否有充足的训练集。
合适的训练样本数量可以使用Widrow的拇指规则来估计。
拇指规则指出,为了得到一个较好的泛化能力,我们需要满足以下条件(WidrowandStearns,1985;Haykin,2008):N=nw/e其中,N为训练样本数量,nw是网络中突触权重的数量,e是测试允许的网络误差。
因此,假如我们允许10%的误差,我们需要的训练样本的数量大约是网络中权重数量的10倍。
神经网络学习样本比如我有1000条数据,每条数据都是随机的,打乱顺序,有啥影响!
利用神经网络进行模式识别,训练时是不是必须要有对立的样本,才能实现分类?
支持向量机有单分类(oneclass)的模式,对应的一些神经网络也有类似的。单分类的作用其实是预处理,用于剔除离群点。
以您的这个例子来说,训练样本为你清晰并且确切的指纹特征,而实际工作的样本为你提取到的各种你自己的指纹特征,神经网络(SVM)所做的工作是区分哪些是你输入特征中有比较多有效信息的,而剔除掉不具有代表性或者受到干扰比较大的样本。
如果能够保证你的输入样本特征选取恰当并且噪声很小的时候,单分类模型的确可以用于分类。但是只能识别出哪些是你的指纹而哪些是其他人的指纹。
神经网络学习样本过多!会怎么样!
bp神经网络,如果学习样本数据过多,会不会变成统计学预测?
用bp神经网络预测样本数据,有很少部分出现了负值,如何避免啊,结果肯定大于0,不可能为负值的。求高手
边栏推荐
- 第12章 数据库其它调优策略【2.索引及调优篇】【MySQL高级】
- 941 · 滑动拼图
- 2022 Henan Mengxin League Game (5): University of Information Engineering K - Matrix Generation
- PLSQL学习第三天
- ES13 - ES2022 - 第 123 届 ECMA 大会批准了 ECMAScript 2022 语言规范
- Text-to-Image最新论文、代码汇总
- 2022河南萌新联赛第(五)场:信息工程大学 J - AC自动机
- 自动化测试框架Pytest(三)——自定义allure测试报告
- 手把手教你进行Mysql查询操作
- 浅谈C语言整型数据的存储
猜你喜欢

SCS【2】单细胞转录组 之 cellranger
![[Network Security] Practice AWVS Range to reproduce CSRF vulnerability](/img/7f/f08e429e3d8ede03a1c1754e256f99.png)
[Network Security] Practice AWVS Range to reproduce CSRF vulnerability
BUUCTF Notes (web)
[网络安全]实操AWVS靶场复现CSRF漏洞

阿里巴巴(中国)网络技术有限公司、测试开发笔试二面试题(附答案)

一文2600字手把手教你编写性能测试用例

语法基础(判断语句)
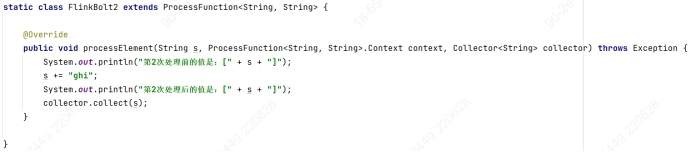
高级测试:如何使用Flink对Strom任务的逻辑功能进行复现测试?

【强化学习】《Easy RL》- Q-learning - CliffWalking(悬崖行走)代码解读

MySQL's InnoDB engine (6)
随机推荐
MySQL database monthly growth problem
About MongoDb query Decimal128 to BigDecimal problem
高质量WordPress下载站模板5play主题
All articles summary directory
Bigder:42/100 showCase多少bug可以打回去
.NET-8. My Thought Notes
CuteOneP is a PHP-based OneDrive multi-network disk mount program with member synchronization and other functions
阿里巴巴(中国)网络技术有限公司、测试开发笔试二面试题(附答案)
腾讯云宋翔:Kubernetes集群利用率提升实践
简单业务类
941 · 滑动拼图
C语言文件操作
Deep understanding of the array
PLSQL学习第三天
MySQL设置初始密码—注意版本mysql-8.0.30
调试ZYNQ的u-boot 2017.3 不能正常启动,记录调试过程
u-boot ERROR: Failed to allocate 0x5c6f bytes below 0x17ffffff.Failed using fdt_high value
Regular backup of mysql database (retain backups for nearly 7 days)
3.事务篇【mysql高级】
什么是MQTT网关?与传统DTU有哪些区别?