当前位置:网站首页>Detailed explanation of VIT transformer
Detailed explanation of VIT transformer
2022-08-09 20:44:00 【The romance of cherry blossoms】
1.VIT overall structure

Build a patch sequence for image data
For an image, divide the image into 9 windows. To pull these windows into a vector, such as a 10*10*3-dimensional image, we first need to pull the image into a 300-dimensional vector.
Location code:
There are two ways of position coding. The first coding is one-dimensional coding. These windows are coded into 1, 2, 3, 4, 5, 6, 7, 8, 9 in order.The second way is two-dimensional encoding, which returns the coordinates of each image window.
Finally, connect a layer of fully-connected layers to map the image encoding and positional encoding to a more easily recognizable encoding for computation.
So, what does the 0 code in the architecture diagram do?
We generally add 0 codes to image classification. Image segmentation and target detection generally do not need to be added. 0patch is mainly used for feature integration to integrate the feature vectors of each window. Therefore, 0 patch can be added in any position.
2. Detailed explanation of the formula
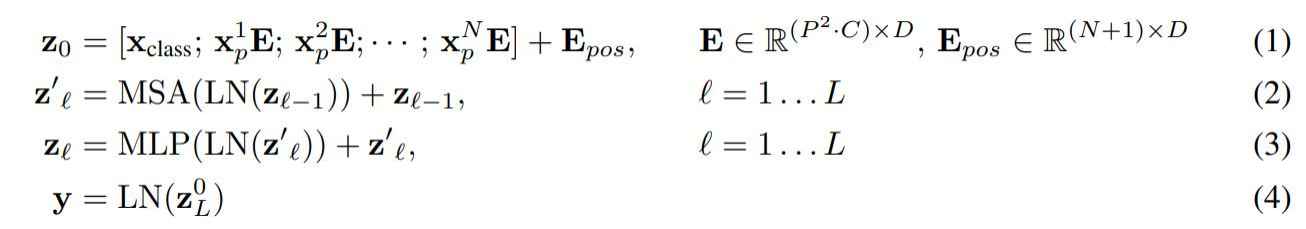
3. The receptive field of multi-head attention
As shown in the figure, the vertical axis represents the distance of attention, which is also equivalent to the receptive field of convolution. When there is only one head, the receptive field is relatively small, and the receptive field is also large. With the number of headsThe increase of , the receptive field is generally relatively large, which shows that Transformer extracts global features.

4.Position coding
Conclusion: The encoding is useful, but the encoding has little effect. Simply use the simple one. The effect of 2D (calculating the encoding of rows and columns separately, and then summing) is stillIt is not as good as 1D, and it is not very useful to add a shared position code to each layer

Of course, this is a classification task, and positional encoding may not have much effect
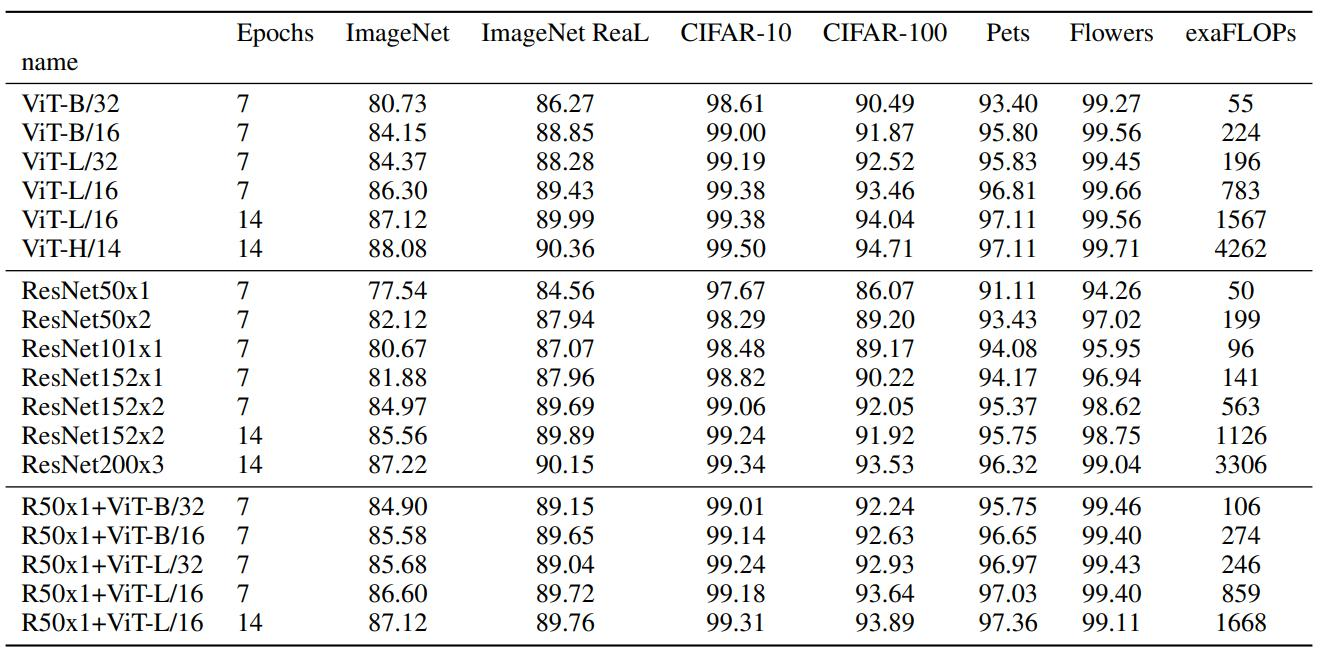
5. Experimental effect(/14 indicates the side length of the patch)
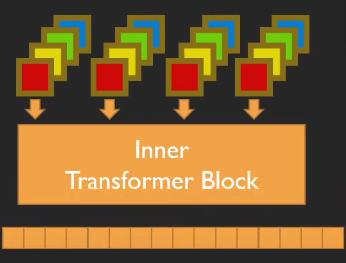
6.TNT: Transformer in Transformer
VIT only models the pathch, ignoring the smaller details

The external transformer divides the original image into windows, and generates a feature vector through image encoding and position encoding.
The internal transformer will further reorganize the window of the external transformer into multiple superpixels and reorganize them into new vectors. For example, the external transformer will split the image into 16*16*3 windows, and the internal transformer will split it again.It is divided into 4*4 superpixels, and the size of the small window is 4*4*48, so that each patch integrates the information of multiple channels.The new vector changes the output feature size through full connection. At this time, the internal combined vector is the same as the patch code size, and the internal vector and the external vector are added.


Visualization of TNT's PatchEmbedding
For the blue dots represent the features extracted by TNT, it can be seen from the visual image that the features of the blue dots are more discrete, have larger variance, and are more conducive to separation, More distinctive features and more diverse distribution

Experimental Results
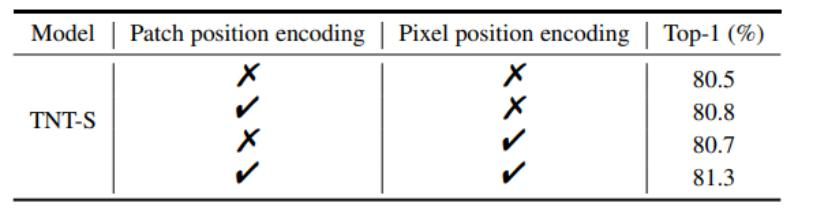
For both internal and external training, the best effect is to add coding
边栏推荐
猜你喜欢
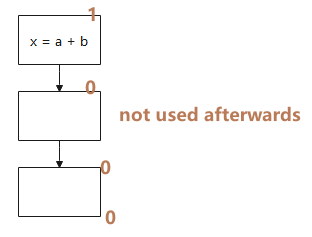





![URLError: <urlopen error [Errno 11004] getaddrinfo failed>调用seaborn-data无法使用](/img/a5/48b480f4ceee37d2d753322f7491eb.png)

随机推荐
CPU状态信息us,sy,ni,id,wa,hi,si,st含义
集合框架Collection与Map的区别和基本使用
商业智能BI行业分析思维框架:铅酸蓄电池行业(一)
进行知识管理的好处有哪些?
为什么修补应用程序漏洞并不容易
ARM 汇编基础
win10 uwp 模拟网页输入
没有 accept,TCP 连接可以建立成功吗?
Sublime Text如何安装Package Control
API接口是什么?API接口常见的安全问题与安全措施有哪些?
qq机器人账号不能发送群消息,被风控
.NET现代应用的产品设计 - DDD实践
混动产品助力,自主SUV市场格局迎来新篇章
uniapp中使用网页录音并上传声音文件(发语音)——js-audio-recorder的使用【伸手党福利】
Detailed explanation of JVM memory model and structure (five model diagrams)
What are some good open source automation testing frameworks to recommend?
艺术与科技的狂欢,云端XR支撑阿那亚2022砂之盒沉浸艺术季
LeetCode笔记:Weekly Contest 305
PHP 变量注释/**@var*/
win10 uwp 无法附加到CoreCLR