当前位置:网站首页>Kaggle - real battle of house price prediction
Kaggle - real battle of house price prediction
2022-04-23 10:38:00 【When can I be as powerful as a big man】
This time kaggle The actual combat is still in progress
Define the log root mean square error used to evaluate the model . Given predicted value y ^ 1 , … , y ^ n \hat y_1, \ldots, \hat y_n y^1,…,y^n And the corresponding real label y 1 , … , y n y_1,\ldots, y_n y1,…,yn, It's defined as
1 n ∑ i = 1 n ( log ( y i ) − log ( y ^ i ) ) 2 . \sqrt{\frac{1}{n}\sum_{i=1}^n\left(\log(y_i)-\log(\hat y_i)\right)^2}. n1i=1∑n(log(yi)−log(y^i))2.
The implementation of log root mean square error is as follows log_rmse(net, features, labels) function .
# This Python 3 environment comes with many helpful analytics libraries installed
# It is defined by the kaggle/python docker image: https://github.com/kaggle/docker-python
# For example, here's several helpful packages to load in
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
import torch
from torch import nn
# Input data files are available in the "../input/" directory.
# For example, running this (by clicking run or pressing Shift+Enter) will list all files under the input directory
import os
# for dirname, _, filenames in os.walk('/kaggle/input'):
# for filename in filenames:
# print(os.path.join(dirname, filename))
# Any results you write to the current directory are saved as output.
train_data = pd.read_csv("../input/house-prices-advanced-regression-techniques/train.csv")
test_data = pd.read_csv("../input/house-prices-advanced-regression-techniques/test.csv")
print(test_data.iloc[0:4, [0, 1, 2, 3, -3, -2, -1]])
print("\n")
print(train_data.iloc[0:4, [0, 1, 2, 3, -3, -2, -1]])
# print(train_data.iloc[0])
print(train_data.shape, test_data.shape)
all_features = pd.concat((train_data.iloc[:, 1:-1], test_data.iloc[:, 1:]))
numeric_features = all_features.dtypes[all_features.dtypes != 'object'].index
all_features[numeric_features] = all_features[numeric_features].apply(lambda x: (x - x.mean()) / (x.std()))
all_features[numeric_features] = all_features[numeric_features].fillna(0)
all_features = pd.get_dummies(all_features, dummy_na=True)
# print(all_features.shape)
n_train = train_data.shape[0]
# get data tensor
train_features = torch.tensor(all_features[:n_train].values, dtype=torch.float)
test_features = torch.tensor(all_features[n_train:].values, dtype=torch.float)
train_lables = torch.tensor(train_data.SalePrice.values, dtype=torch.float)
# test_lables = torch.tensor(test_data.SalePrice.values, dtype=torch.float)
# print(train_features.shape)
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.fc1 = nn.Linear(331, 1)
self.relu = nn.ReLU(True)
def forward(self,input):
output = self.fc1(input)
output = self.relu(output)
return output
net = Net()
for param in net.parameters():
nn.init.normal_(param, mean=0, std=0.01)
loss_fn = nn.MSELoss()
def log_rmse(net, features, labels):
with torch.no_grad():
# Will be less than 1 The value of is set to 1, Make the value more stable when taking logarithm
clipped_preds = torch.max(net(features), torch.tensor(1.0))
rmse = torch.sqrt(2 * loss_fn(clipped_preds.log(), labels.log()).mean())
return rmse.item()
def train(net, train_data, train_lables, num_epochs, learning_rate, weight_decay, batch_size):
dataset = torch.utils.data.TensorDataset(train_features, train_lables)
train_iter = torch.utils.data.DataLoader(dataset, batch_size, shuffle=True)
optimizer = torch.optim.Adam(params=net.parameters(), lr=learning_rate, weight_decay=weight_decay)
net = net.float()
for epoch in range(num_epochs):
for X, y in dataset:
net.train()
X = net(X.float())
l = loss_fn(X, y.float())
optimizer.zero_grad()
l.backward()
optimizer.step()
train_ls.append(log_rmse(net, train_features, train_lables))
# if test_labels is not None:
# test_ls.append(log_rmse(net, test_features, test_labels))
return train_ls
num_epochs = 50
learning_rate = 0.01
weight_decay = 0
batch_size = 64
train_ls = []
train(net, train_data, train_lables, num_epochs, learning_rate, weight_decay, batch_size)
print(train_ls[40:])
K Crossover verification
We are choosing the model 、 Under fitting and over fitting are introduced K K K Crossover verification . It will be used to select model design and adjust superparameters . The following implements a function , It goes back to i Training and validation data required for fold cross validation .
def get_k_fold_data(k, i, X, y):
# Back to page i Training and validation data required for fold cross validation
assert k > 1
fold_size = X.shape[0] // k
X_train, y_train = None, None
for j in range(k):
idx = slice(j * fold_size, (j + 1) * fold_size)
X_part, y_part = X[idx, :], y[idx]
if j == i:
X_valid, y_valid = X_part, y_part
elif X_train is None:
X_train, y_train = X_part, y_part
else:
X_train = torch.cat((X_train, X_part), dim=0)
y_train = torch.cat((y_train, y_part), dim=0)
return X_train, y_train, X_valid, y_valid
stay K K K In fold cross validation, we train K K K And return the average error of training and verification
def k_fold(k, X_train, y_train, num_epochs,
learning_rate, weight_decay, batch_size):
train_l_sum, valid_l_sum = 0, 0
for i in range(k):
data = get_k_fold_data(k, i, X_train, y_train)
net = get_net(X_train.shape[1])
train_ls, valid_ls = train(net, *data, num_epochs, learning_rate,
weight_decay, batch_size)
train_l_sum += train_ls[-1]
valid_l_sum += valid_ls[-1]
if i == 0:
d2l.semilogy(range(1, num_epochs + 1), train_ls, 'epochs', 'rmse',
range(1, num_epochs + 1), valid_ls,
['train', 'valid'])
print('fold %d, train rmse %f, valid rmse %f' % (i, train_ls[-1], valid_ls[-1]))
return train_l_sum / k, valid_l_sum / k
Model selection
We use a set of non tuned hyperparameters and calculate the cross validation error . These super parameters can be changed to minimize the average test error .
Sometimes you will find that the training error of a set of parameters can be very low , But in K K K The error in fold cross validation may be higher . This phenomenon is probably caused by over fitting . therefore , When the training error decreases , We have to observe K K K Is the error in fold cross validation reduced accordingly .
k, num_epochs, lr, weight_decay, batch_size = 5, 100, 5, 0, 64
train_l, valid_l = k_fold(k, train_features, train_labels, num_epochs, lr, weight_decay, batch_size)
print('%d-fold validation: avg train rmse %f, avg valid rmse %f' % (k, train_l, valid_l))
Forecast and in Kaggle Submit results in
The prediction function is defined below . Before forecasting , We will use the complete training data set to retrain the model , And save the prediction results in the format required for submission .
def train_and_pred(train_features, test_features, train_labels, test_data,
num_epochs, lr, weight_decay, batch_size):
net = get_net(train_features.shape[1])
train_ls, _ = train(net, train_features, train_labels, None, None,
num_epochs, lr, weight_decay, batch_size)
d2l.semilogy(range(1, num_epochs + 1), train_ls, 'epochs', 'rmse')
print('train rmse %f' % train_ls[-1])
preds = net(test_features).detach().numpy()
test_data['SalePrice'] = pd.Series(preds.reshape(1, -1)[0])
submission = pd.concat([test_data['Id'], test_data['SalePrice']], axis=1)
submission.to_csv('./submission.csv', index=False)
# sample_submission_data = pd.read_csv("../input/house-prices-advanced-regression-techniques/sample_submission.csv")
版权声明
本文为[When can I be as powerful as a big man]所创,转载请带上原文链接,感谢
https://yzsam.com/2022/04/202204230619103950.html
边栏推荐
- Contact between domain name and IP address
- How can swagger2 custom parameter annotations not be displayed
- Define linked list (linked list)
- 1、两数之和(哈希表)
- 242、有效字母异位词(哈希表)
- 19. Delete the penultimate node of the linked list (linked list)
- What if Jerry's function to locate the corresponding address is not accurate sometimes? [chapter]
- 997、有序数组的平方(数组)
- Cve-2019-0708 vulnerability exploitation of secondary vocational network security 2022 national competition
- SQL Server 游标循环表数据
猜你喜欢



![[provincial election joint examination 2022 d2t1] card (state compression DP, FWT convolution)](/img/e4/3c47edbc3241ba86f10a1ac8a963fd.png)




随机推荐
JUC concurrent programming 09 -- source code analysis of condition implementation
Chapter 2 Oracle database in memory architecture (I) (im-2.1)
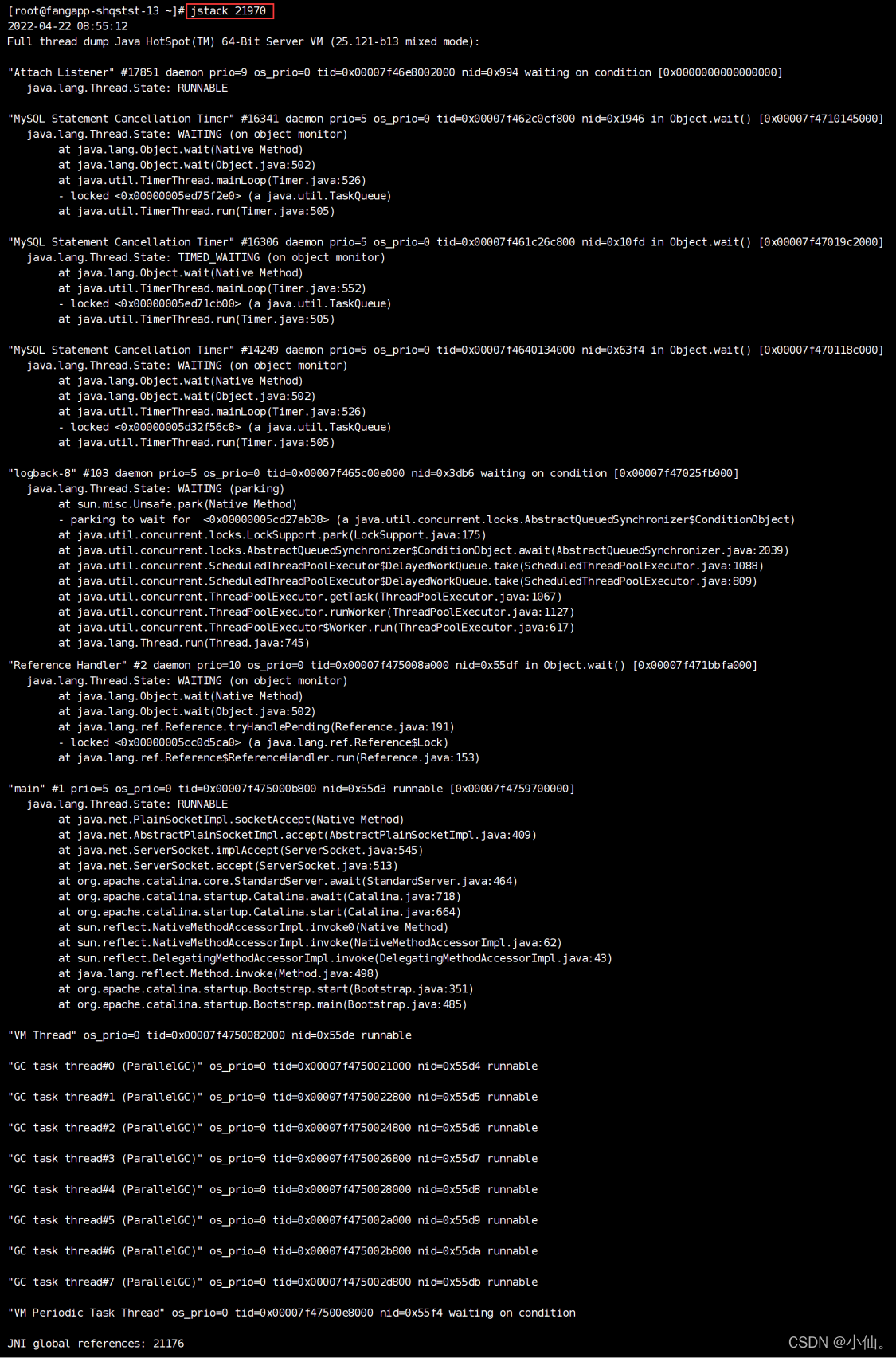
JVM——》常用命令
Yarn resource scheduler
203. Remove linked list elements (linked list)
Can Jerry's AES 256bit [chapter]
Using multithreading to output abc10 times in sequence
Detailed explanation of MapReduce calculation process
Net start MySQL MySQL service is starting MySQL service failed to start. The service did not report any errors.
59、螺旋矩阵(数组)
349、两个数组的交集
部署jar包
精彩回顾 | DEEPNOVA x Iceberg Meetup Online《基于Iceberg打造实时数据湖》
1、两数之和(哈希表)
Deploy jar package
Jerry's users how to handle events in the simplest way [chapter]
图像处理——噪声小记
997、有序数组的平方(数组)
Read integrity monitoring techniques for vision navigation systems - 4 multiple faults in vision system
Chapter 1 Oracle database in memory related concepts (im-1.1)