当前位置:网站首页>Mobile/Embedded-CV Model-2017: MobelNets-v1
Mobile/Embedded-CV Model-2017: MobelNets-v1
2022-08-08 09:32:00 【u013250861】
The MobileNet model is a lightweight deep neural network proposed by Google for embedded devices such as mobile phones. The core idea of its use is depthwise separable convolution (depth separable convolution).
I. What is depthwise separable convolution (proposed by Mobilenet-v1)
Assume a network convolutional layer with a convolution kernel size of 3×3, 16 input channels and 32 output channels;
The conventional convolution operation is to apply 32 3×3×16 convolution kernels to the 16-channel input image, then according to the convolution layer parameter calculation formula, convolution calculation + convolution parameter amount + convolution measurementQuantity
The required parameters are 32*(3316+1)=4640.
If 16 convolution kernels (331) with a size of 3×3 are applied to the input image of 16 channels first, 16 feature maps are obtained, and the fusion operation is performed.Before, then use 32 convolution kernels (1116) with a size of 1×1 to traverse the 16 feature maps obtained above. According to the calculation formula of the parameters of the convolution layer, the required parameters are (33116+16) + (111632+32) = 706.
The above is the role of the depthwise separable convolution. In layman's terms, the feature extraction and feature combination of the ordinary convolutional layer are completed and output at one time, while the depthwise separable convolution first uses 33 with a thickness of 1.The convolution kernel (depthwise layered convolution) is used, and the number of channels is adjusted with a 11 convolution kernel (pointwise convolution), and feature extraction and feature combination are performed separately.
It can be seen that the depthwise separable convolution can greatly reduce the parameters of the model, and its specific structure is as follows (the left is the ordinary convolutional layer structure, the right is the depthwise separable convolution structure):
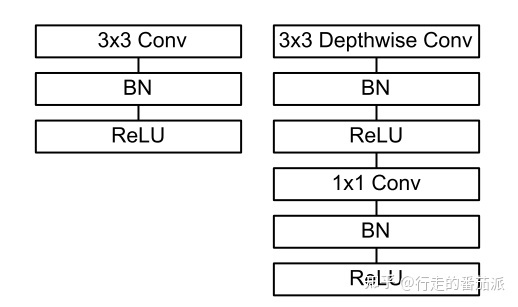
- Only one convolution kernel with dimension in_channels is used for feature extraction (no feature combination) when performing deepthwise (DW) convolution;
- When performing pointwise (PW) convolution, only output_channels convolution kernels with dimension in_channels 1*1 are used for feature combination.
References:
Lightweight Network - MobileNet
The application of deep learning in image processing (tensorflow2.4 and pytorch1.10 implementation)
Lightweight Network-Mobilenet Series(v1,v2,v3)
边栏推荐
- PCL calculates the intersection of two straight lines in space
- PCBA电路板为什么需要使用三防漆,有何作用?
- LabVIEW前面板和程序框图的最大尺寸
- jupyter lab内终端从sh变为bin/bash(切换conda操作)
- hdu4635 Strongly connected(tarjan计算强连通通分量+缩点+思想)
- STL underlying implementation principle
- 2022 - image classification 】 【 MaxViT ECCV
- 各种attention的代码实现
- DBeaver 22.1.4 released, a visual database management platform
- Raspberry pie 】 【 without WIFI even under the condition of the computer screen
猜你喜欢

小散量化炒股记|打包Py可执行文件,双击就能选出全市场稳步上扬的股票

Multi-scalar multiplication: state of the art & new ideas

「控制反转」和「依赖倒置」,傻傻分不清楚?
Bytes and Characters and Common Encodings

入职半个月的一些思考

LeetCode:第305场周赛【总结】

Data Governance (3): Data Quality Management

Excel method is commonly used in text function 5

1252_FreeRTOS_堆栈溢出检查方法与测试
你一定要看的安装及卸载测试用例的步骤及方法总结
随机推荐
AI引领一场新的科学革命
Android Studio关于MainActivity中的“import kotlinx.android.synthetic.main.activity_main.*”出现错误提示
数据库调优:Mysql索引对group by 排序的影响
小白求助,关于Go编译的顺序
一个用来装逼的利器
英文token预处理,用于将英文句子处理成单词
Offensive and defensive world - leaking
Go 匿名字段与实现重写方法
Offensive and defensive world - ics-05
Elasticseach实践1
【图像分类】2022-MaxViT ECCV
Data Governance (3): Data Quality Management
hdu4635 Strongly connected (tarjan calculates strongly connected components + shrink points + ideas)
各种attention的代码实现
STL underlying implementation principle
Excel中text函数5中常用方法
[Raspberry Pi] vim editor
Pinia(一)初体验快速安装与上手
Techwiz OLED:偏振片的发射特性
Feign application and source code analysis