当前位置:网站首页>Flink 指标参数源码解读(读取数量、发送数量、发送字节数、接收字节数等)
Flink 指标参数源码解读(读取数量、发送数量、发送字节数、接收字节数等)
2022-04-22 06:34:00 【杨林伟】
文章目录
01 引言
附:Flink源码下载地址
在Flink的Web页面,细心的话可以看到监控页面里,有任务的详情,其中里面有详细的监控指标,如下图(发送记录数、接收记录数、发送字节数,接收字节数等):
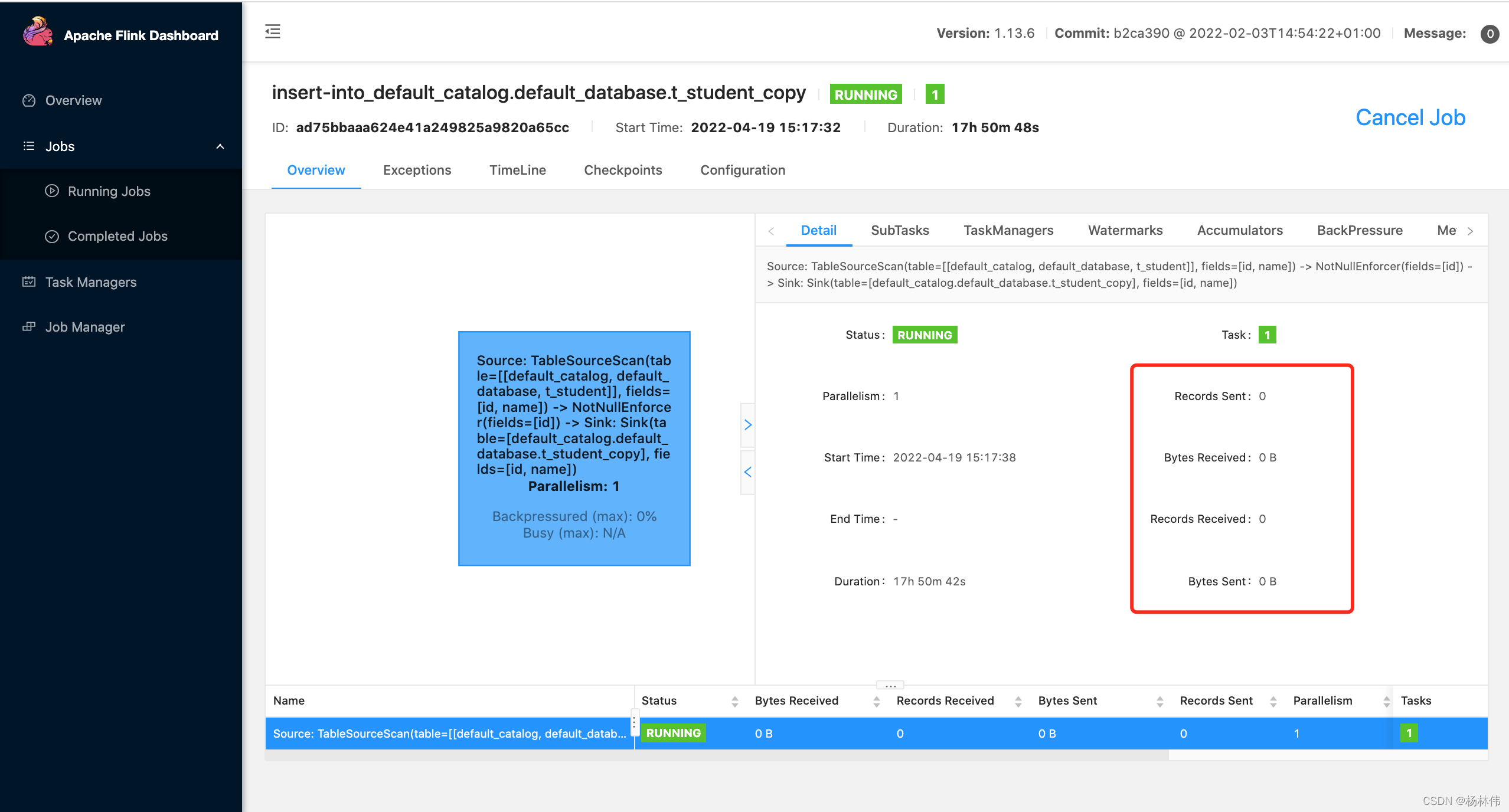
很多时候,我们都需要 “取出这些数据”,并用在我们的需求上,那么该如何取出这些数据呢?本文来分析下源码。
02 源码分析
2.1 源码入口
在Flink的web页面,按F12查看源码,可以看到:
{
"jid": "ad75bbaaa624e41a249825a9820a65cc",
"name": "insert-into_default_catalog.default_database.t_student_copy",
"isStoppable": false,
"state": "RUNNING",
"start-time": 1650352652357,
"end-time": -1,
"duration": 64629227,
"maxParallelism": -1,
"now": 1650417281584,
"timestamps": {
"INITIALIZING": 1650352652357,
"FAILED": 0,
"CREATED": 1650352652449,
"RESTARTING": 0,
"FAILING": 0,
"FINISHED": 0,
"SUSPENDED": 0,
"RECONCILING": 0,
"CANCELLING": 0,
"CANCELED": 0,
"RUNNING": 1650352653087
},
"vertices": [
{
"id": "cbc357ccb763df2852fee8c4fc7d55f2",
"name": "Source: TableSourceScan(table=[[default_catalog, default_database, t_student]], fields=[id, name]) -> NotNullEnforcer(fields=[id]) -> Sink: Sink(table=[default_catalog.default_database.t_student_copy], fields=[id, name])",
"maxParallelism": 128,
"parallelism": 1,
"status": "RUNNING",
"start-time": 1650352658363,
"end-time": -1,
"duration": 64623221,
"tasks": {
"CREATED": 0,
"CANCELING": 0,
"INITIALIZING": 0,
"RECONCILING": 0,
"CANCELED": 0,
"RUNNING": 1,
"DEPLOYING": 0,
"FINISHED": 0,
"FAILED": 0,
"SCHEDULED": 0
},
"metrics": {
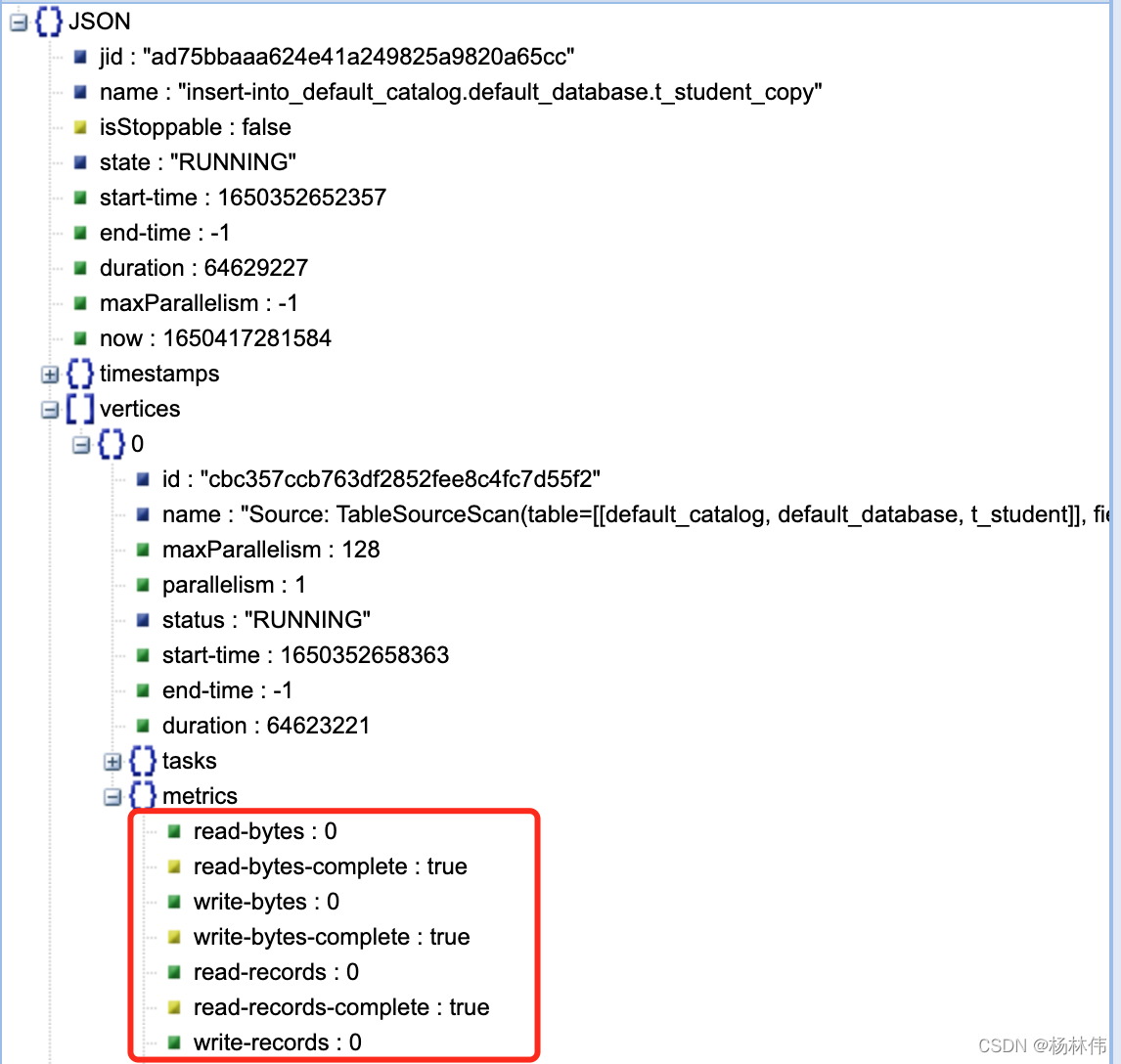
"read-bytes": 0,
"read-bytes-complete": true,
"write-bytes": 0,
"write-bytes-complete": true,
"read-records": 0,
"read-records-complete": true,
"write-records": 0,
"write-records-complete": true
}
}
],
"status-counts": {
"CREATED": 0,
"CANCELING": 0,
"INITIALIZING": 0,
"RECONCILING": 0,
"CANCELED": 0,
"RUNNING": 1,
"DEPLOYING": 0,
"FINISHED": 0,
"FAILED": 0,
"SCHEDULED": 0
},
"plan": {
"jid": "ad75bbaaa624e41a249825a9820a65cc",
"name": "insert-into_default_catalog.default_database.t_student_copy",
"nodes": [
{
"id": "cbc357ccb763df2852fee8c4fc7d55f2",
"parallelism": 1,
"operator": "",
"operator_strategy": "",
"description": "Source: TableSourceScan(table=[[default_catalog, default_database, t_student]], fields=[id, name]) -> NotNullEnforcer(fields=[id]) -> Sink: Sink(table=[default_catalog.default_database.t_student_copy], fields=[id, name])",
"optimizer_properties": {
}
}
]
}
}
可以看到,vertices.[0].metrics下的内容就是本文要读取的内容,如下图:
Ctrl+H全局搜索Flink源码,我们可能会想到先查看接口 “/jobs/{jobId}”,其实这样效率很低,最好的方法就是使用其 “特殊性”,比如,我们可以从返回的字段read-bytes入手,发现定义的地方在org.apache.flink.runtime.rest.messages.job.metrics.IOMetricsInfo 这个类:
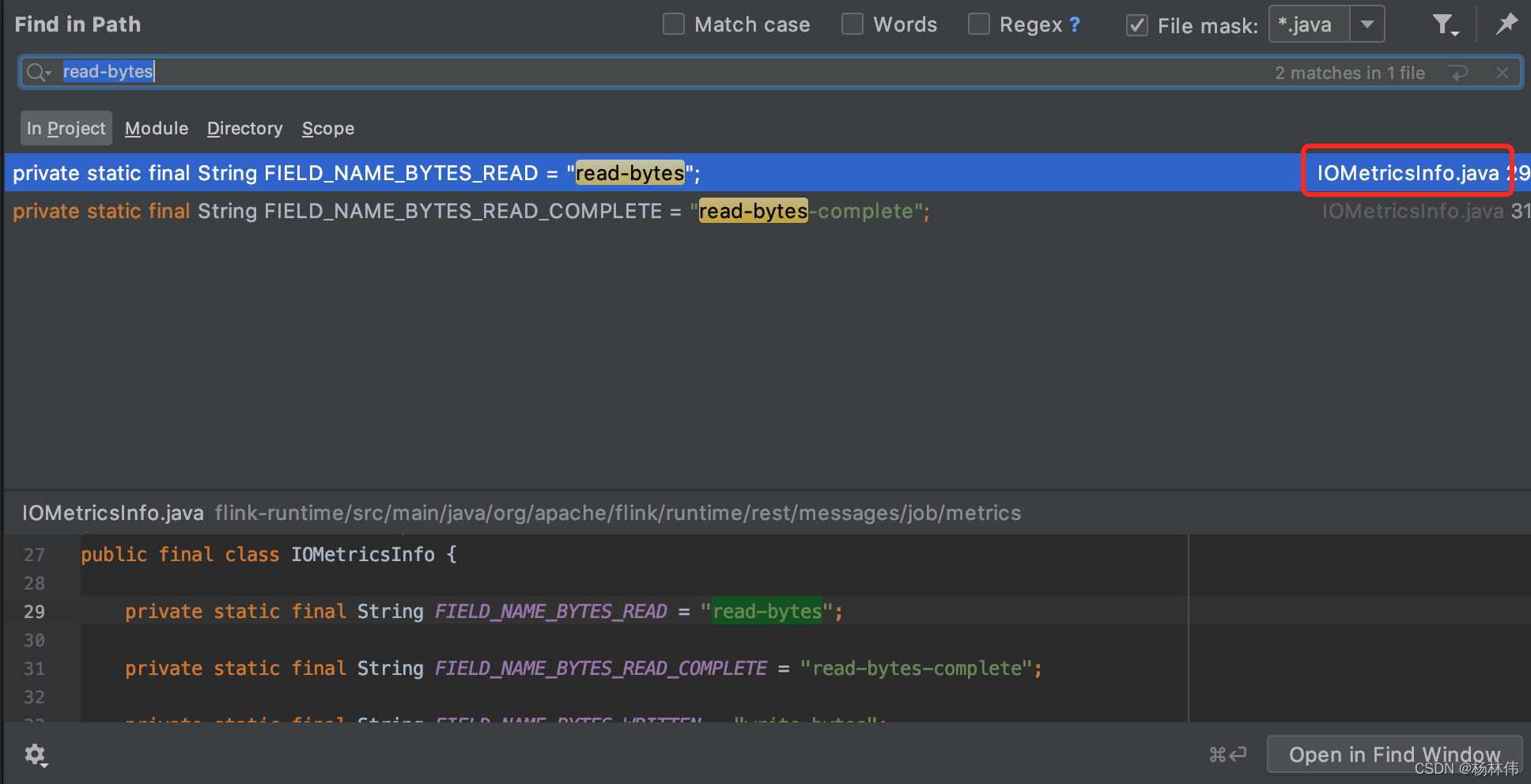
好了,我们可以把IOMetricsInfo这个类当做我们的源码分析入口。
2.2 IOMetricsInfo
在IOMetricsInfo,Ctrl+G查看,可以看到这个类有多个地方被调用,其实真正的是被JobDetailsHandler调用了,其它的类后缀都是Test测试类,所以不作为分析的下一步,下面看看JobDetailsHandler。
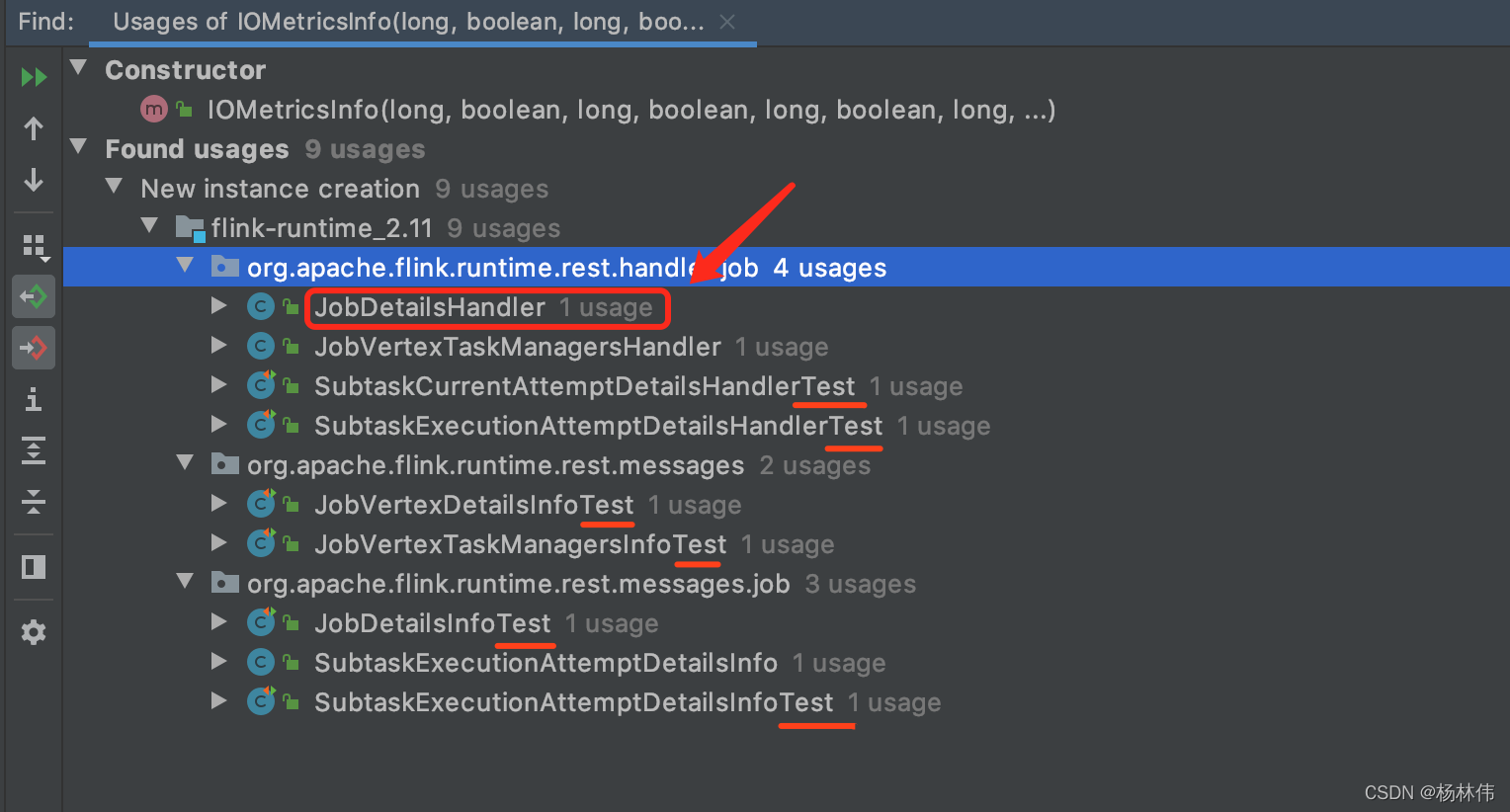
在JobDetailsHandler,可以看到指标值是总counts里获取的,继续看counts

counts在这里赋值了:
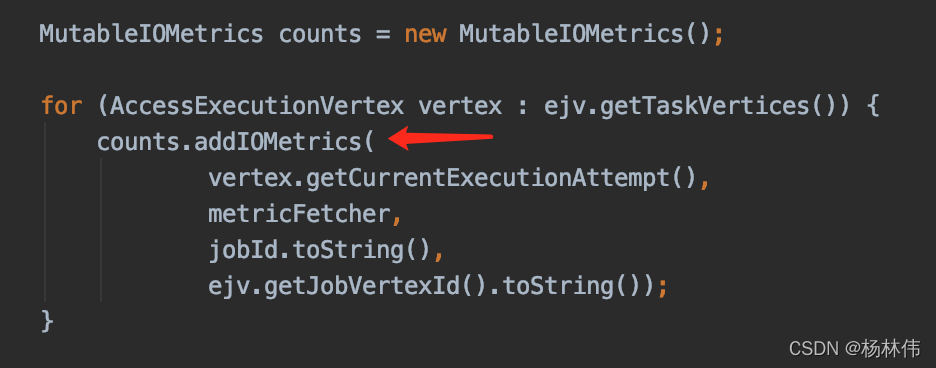
接下来,我们看看MutableIOMetrics这个类。
2.3 MutableIOMetrics
进入上一步指定的MutableIOMetrics里的addIOMetrics方法,可以看到代码根据程序的运行状态,从不同的地方获取指标值了:
- 终止状态:从
AccessExecution获取了指标值 - 运行状态:从
MetricFetcher获取了指标值

因为我们的程序是运行的,当然,我们需要研究MetricFetcher这个类里面的值是怎么拿到的。
2.3 MetricFetcher
fetcher:是抓取的意思,可以理解为取数据
我翻译了MetricFetcher这个类的注释,内容如下:
package org.apache.flink.runtime.rest.handler.legacy.metrics;
/** * MetricFetcher可用于从JobManager和所有注册的taskmanager中获取指标。 * <p> * 只有在调用{@link MetricFetcher#update()}时指标才会被获取,前提是自上次调用传递之后有足够的时间。 * * @author : YangLinWei * @createTime: 2022/4/20 10:30 上午 * @version: 1.0.0 */
public interface MetricFetcher {
/** * 获取{@link MetricStore},其中包含当前获取的所有指标。 * * @return {@link MetricStore} 包含的所有获取的指标 */
MetricStore getMetricStore();
/** * 触发获取指标 */
void update();
/** * @return 最近一次更新的时间戳。 */
long getLastUpdateTime();
}
继续Ctrl+T查看其实现:
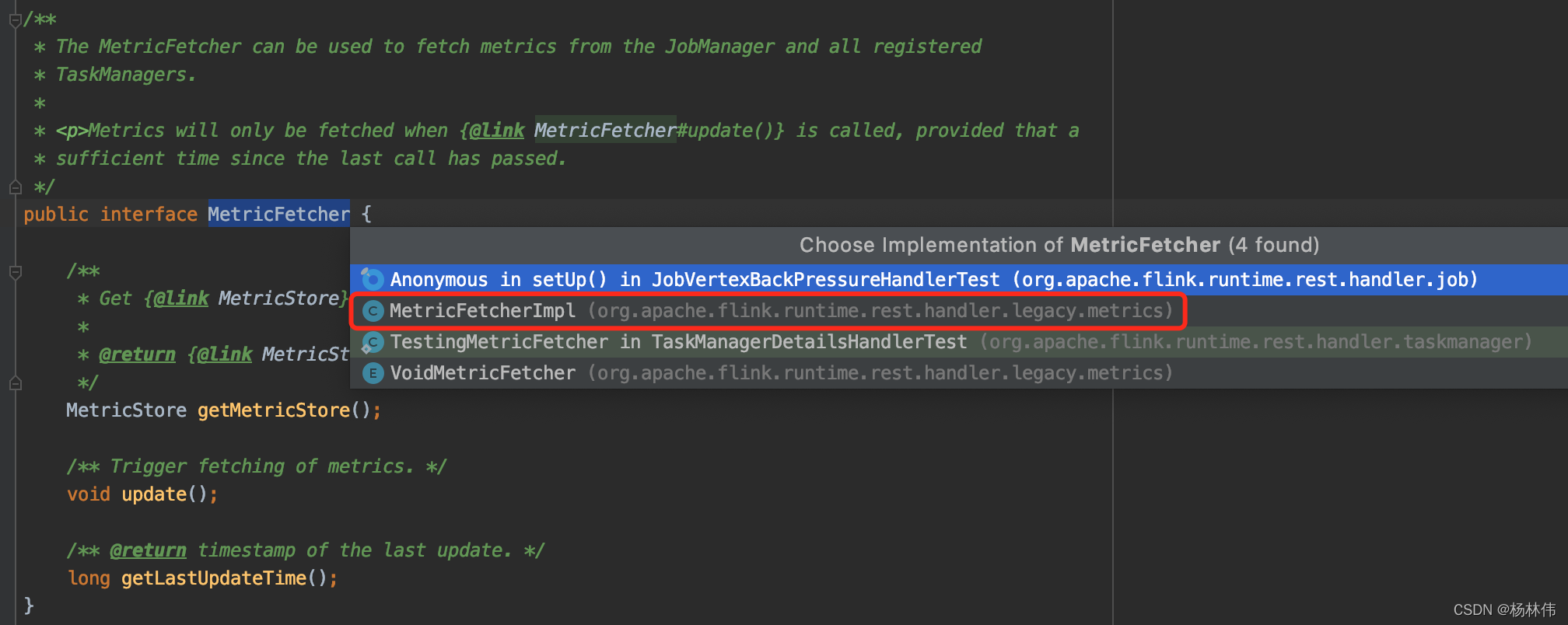
可以看到有几个实现类,毋庸置疑,MetricFetcherImpl是它真正的实现类,看看里面的代码。
2.3.1 MetricFetcherImpl
MetricFetcherImpl里面有几个方法,如下:
 我们需要知道这些指标从何而来?里面的代码不多,大部分都不是我们需要的,经一番阅读,可以知道,指标是从
我们需要知道这些指标从何而来?里面的代码不多,大部分都不是我们需要的,经一番阅读,可以知道,指标是从queryMetrics这个方法里获取。看看这个方法的代码:
/** * Query the metrics from the given QueryServiceGateway. * * @param queryServiceGateway to query for metrics */
private void queryMetrics(final MetricQueryServiceGateway queryServiceGateway) {
LOG.debug("Query metrics for {}.", queryServiceGateway.getAddress());
queryServiceGateway
.queryMetrics(timeout)
.whenCompleteAsync(
(MetricDumpSerialization.MetricSerializationResult result, Throwable t) -> {
if (t != null) {
LOG.debug("Fetching metrics failed.", t);
} else {
metrics.addAll(deserializer.deserialize(result));
}
},
executor);
}
所以,代码追踪了这么久,发现指标是从网关(MetricQueryServiceGateway)里调接口去获取的,所以我们需要看源码这个网关接口(queryMetrics)的代码实现。
2.4 MetricQueryServiceGateway
从上一步,可以知道调用了MetricQueryServiceGateway的queryMetrics接口,具体的实现MetricQueryService类的queryMetrics 方法,代码如下:
@Override
public CompletableFuture<MetricDumpSerialization.MetricSerializationResult> queryMetrics(
Time timeout) {
return callAsync(
() -> enforceSizeLimit(serializer.serialize(counters, gauges, histograms, meters)),
timeout);
}
再看看callAsync方法:
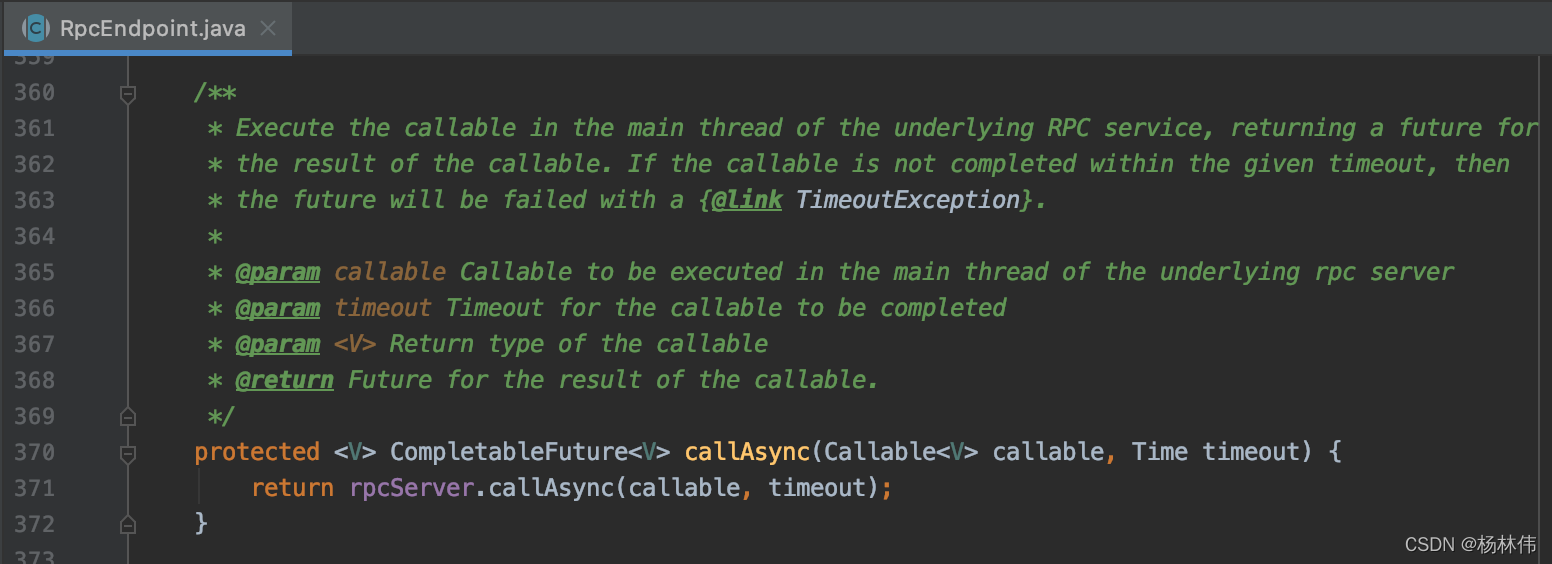
可以得知,本质就是使用了rpcServer去远程调用了接口获取指标了(具体调用了哪里呢?)。
我们看看RpcEndpoint这个类。
2.5 RpcEndpoint
我们看看RpcEndpoint这个类的方法结构:
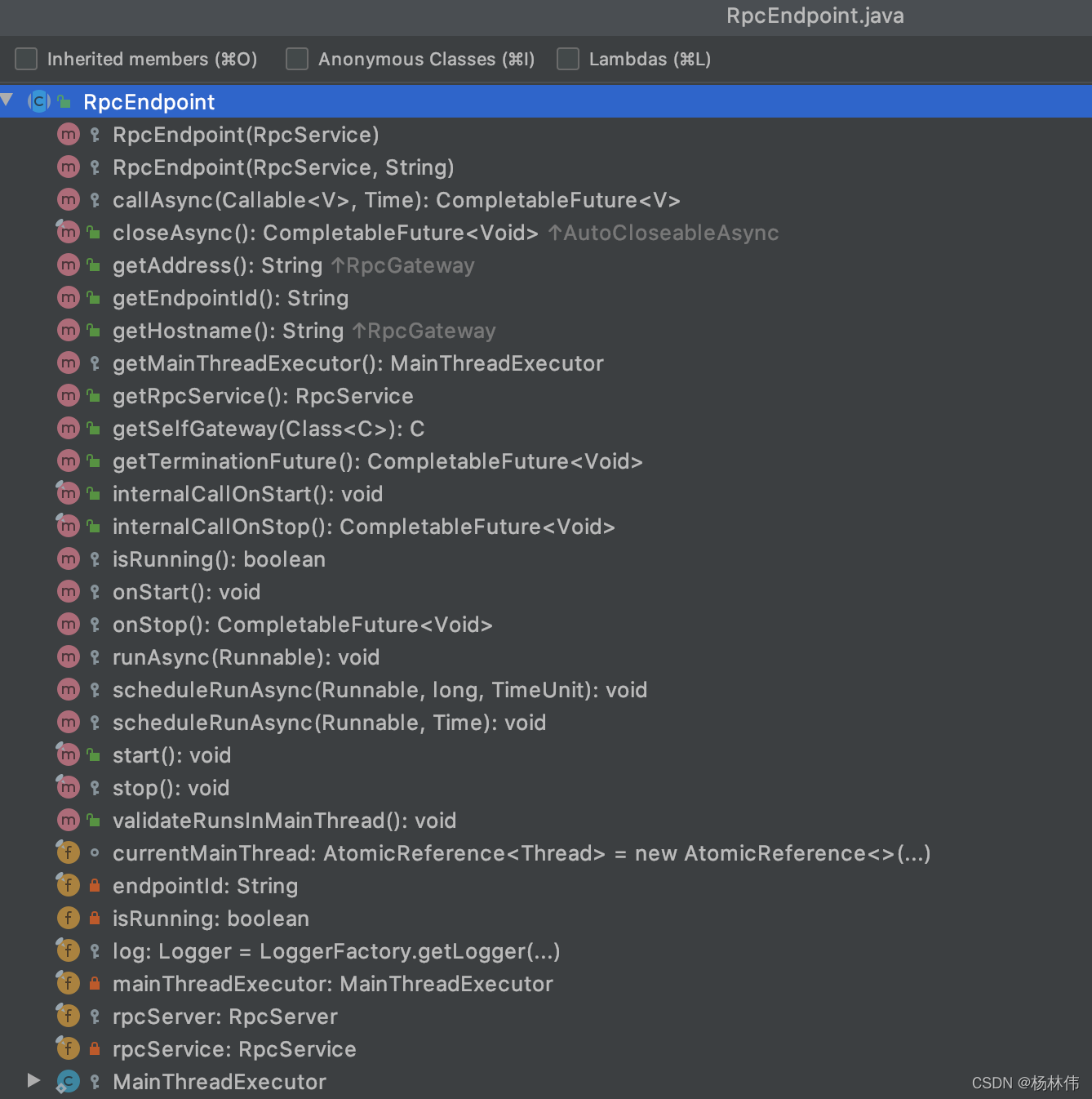
从这些方法名,我们可以知道,它类似于一个HTTP服务器,从而我们也可以知道,原来Flink的Web页面访问的服务器就是这个了。在看看其构造方法:

看看里面是怎么开启服务的:

可以知道,是调用了AkkaRpcService的startServer方法去开启了服务。
好了,这里暂时该停止了,因为偏离了本文的中心,我们需要知道的是这些指标具体从哪里来的?那该如何进行下一步呢?
我们再回到2.4里面的MetricQueryService类,看看这个类是如何构造的?(这里前后连贯性很强)。
2.6 MetricQueryService
可以看到MetricQueryService这个类里面有一个createMetricQueryService方法,这个方法指的就是创建指标查询服务:

看看在哪里调用了这个方法:
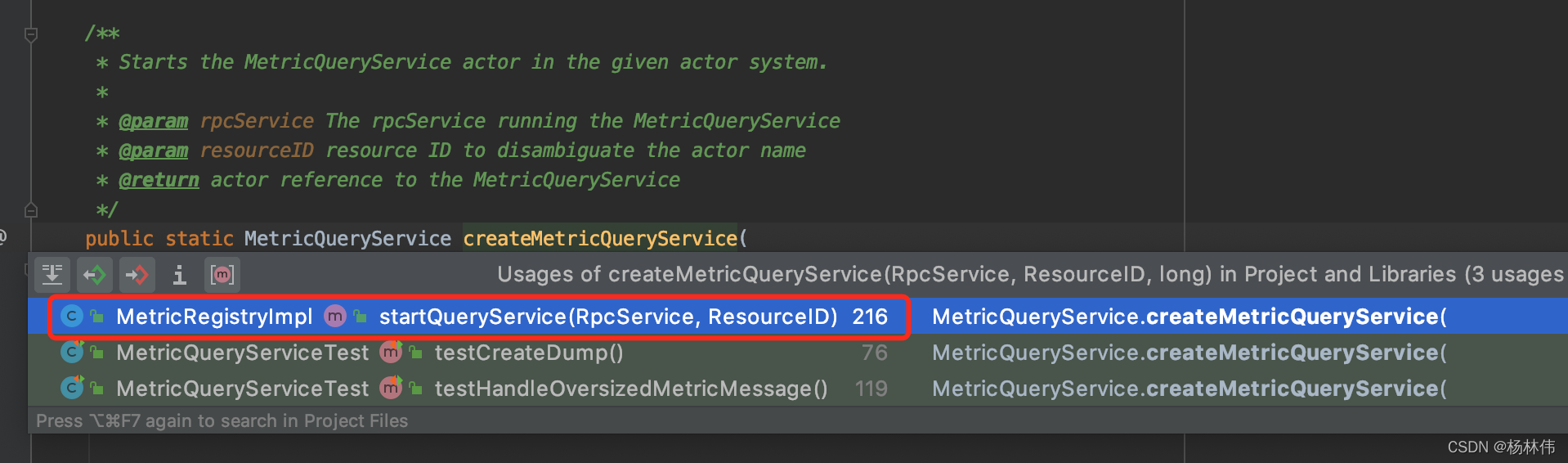
可以在指标服务注册中心(MetricRegistryImpl)里面的startQueryService方法调用了,再看看哪里调用了startQueryService这个方法:
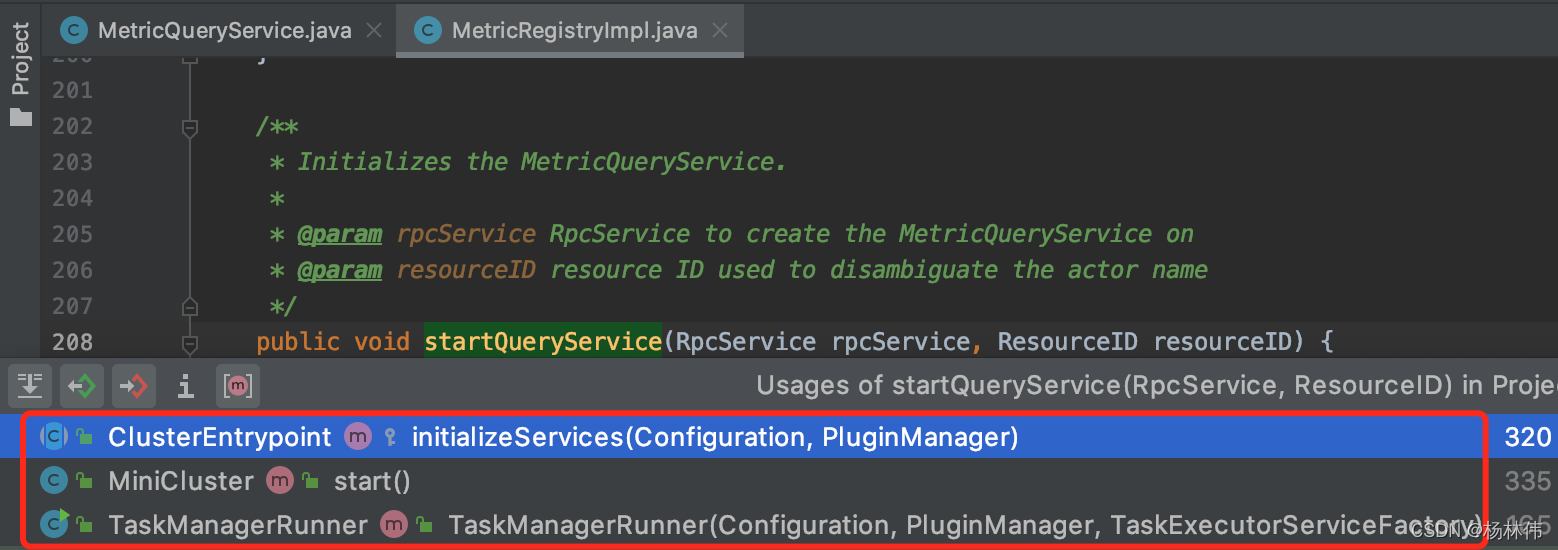
可以看到有3个地方开启了这个指标的服务,分别是:
- ClusterEntrypoint:
Flink集群入口点的基类 - MiniCluster:
MiniCluster在本地执行Flink任务 - TaskManagerRunner:在
yarn或standalone模式下,这个类是任务管理器的可执行入口点。它构建相关组件(网络、I/O管理器、内存管理器、RPC服务、HA服务)并启动。
为了方便理解,这里解读本地执行Flink任务的模式就好了,即继续研读MiniCluster。
2.7 MiniCluster
在MiniCluster的start()方法,可以看到了调用了startQueryService方法

继续看看里面的metricQueryServiceRpcService入参,可以知道,metricQueryServiceRpcService(指标查询服务)是从配置里初始化来的。
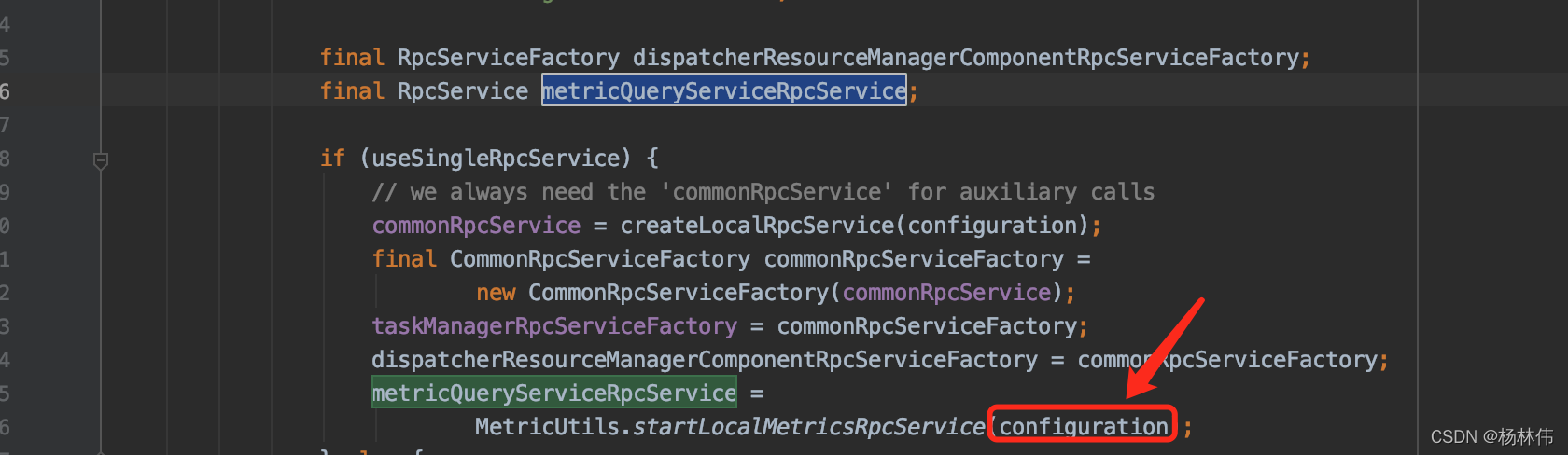
继续看看configuration配置:
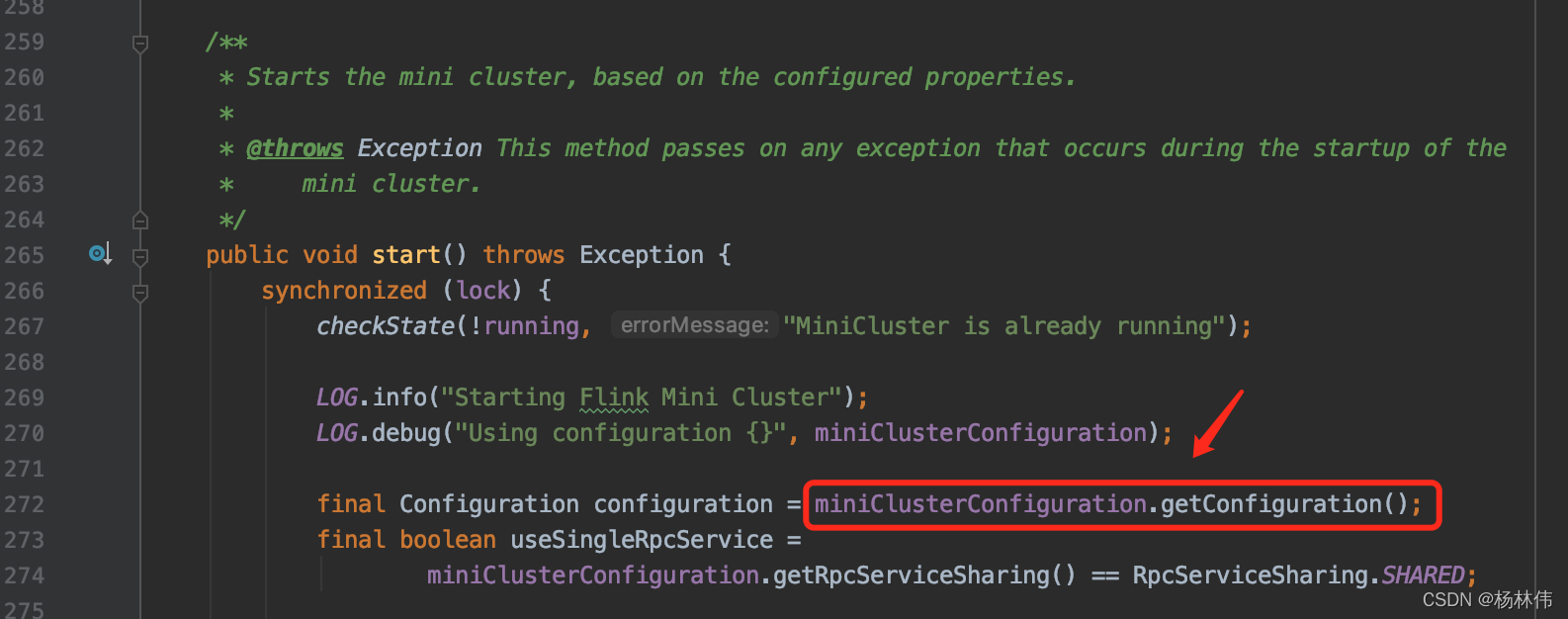
可以得知,配置是从miniClusterConfiguration里获取的,继续深入:
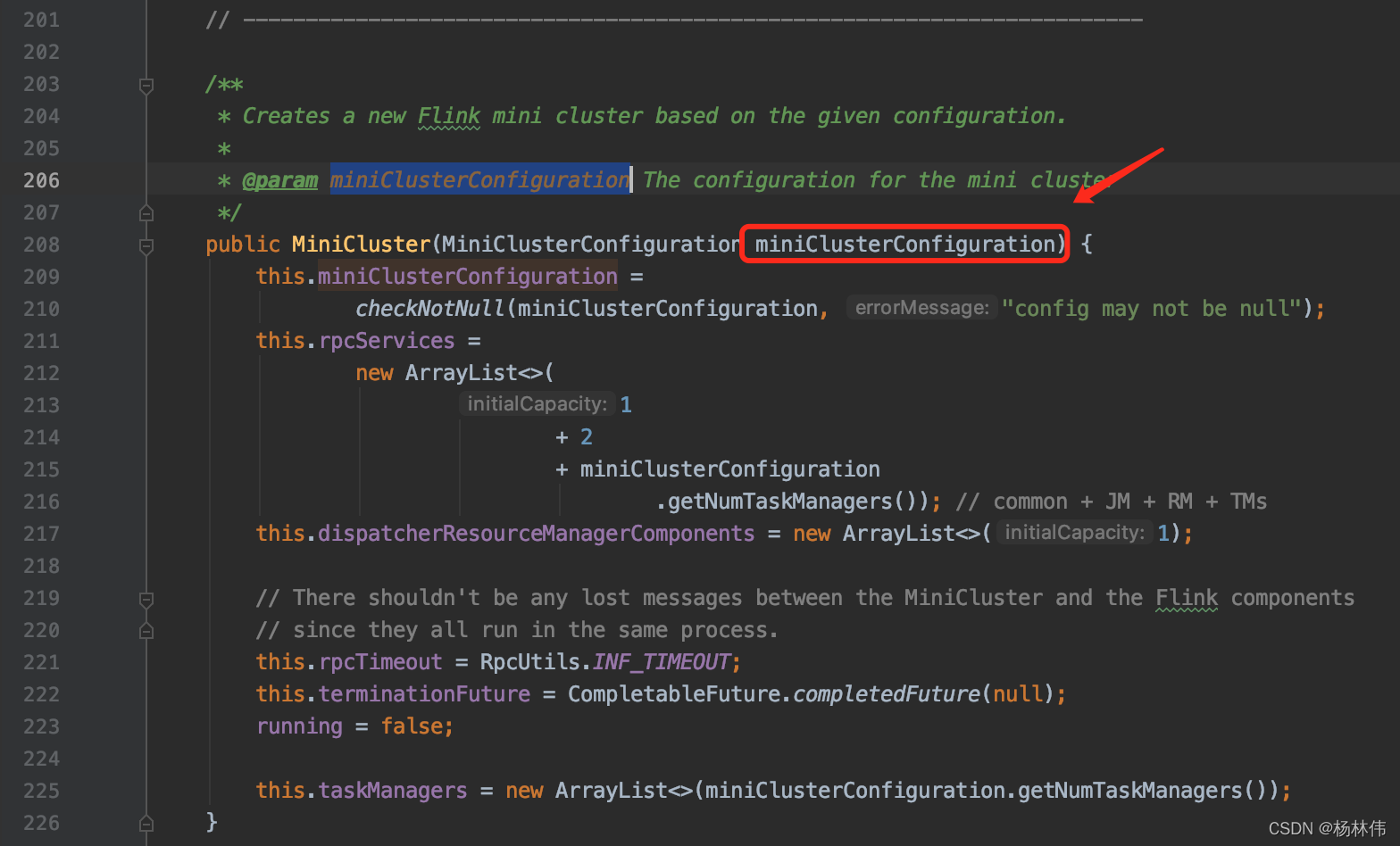
发现,配置是从构造函数里获取的,继续看看哪里调用了MiniCluster这个类的构造函数方法:
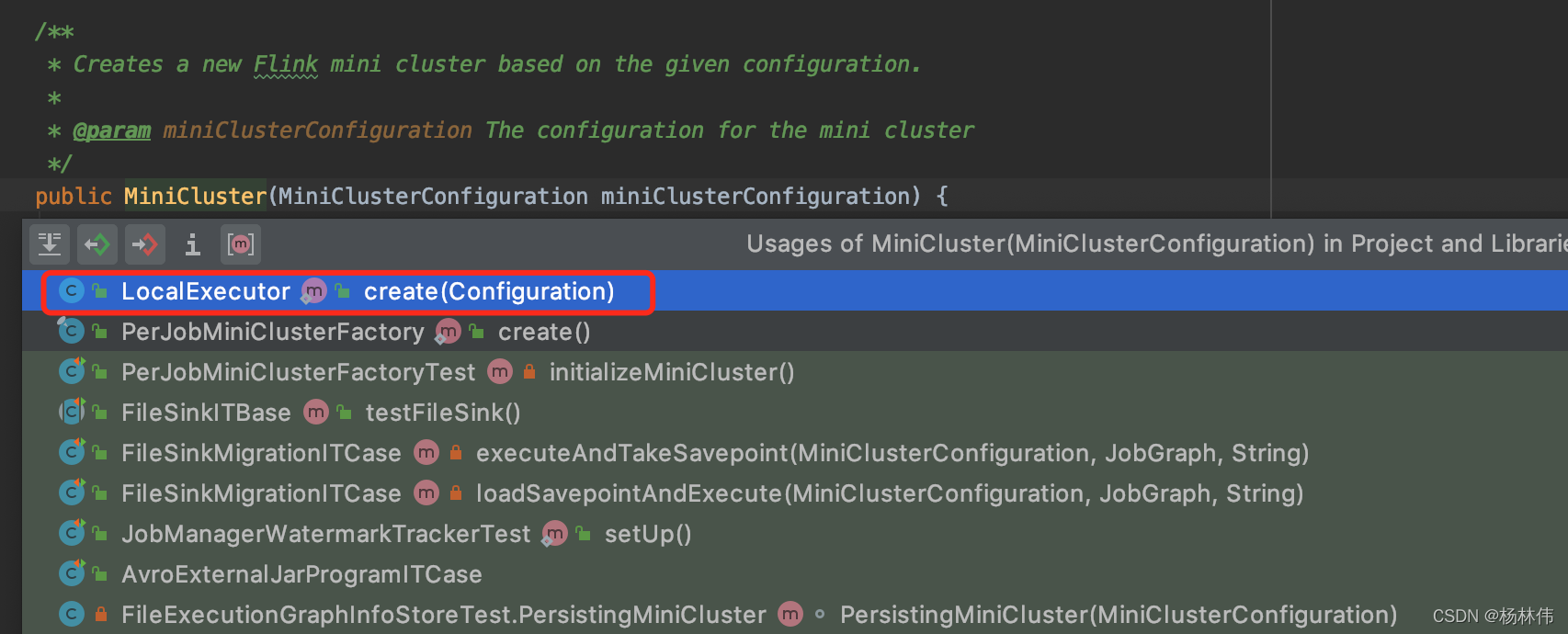
调用这个方法的类有很多,根据命名,可以得知较为合理的是LocalExecutor这个类。
2.8 LocalExecutor
我对LocalExecutor的理解:一个用于执行本地Pipelines(例如:多条FlinkSQL)的执行器。
看看哪里调用了MiniCluster的构造方法:

继续看看哪里调用了create方法,可以得知在LocalExecutorFactory里的getExecutor方法调用了:

Ctrl+T,可以看到在ExecutionEnviroment和StreamExecutionEnviroment里调用了:
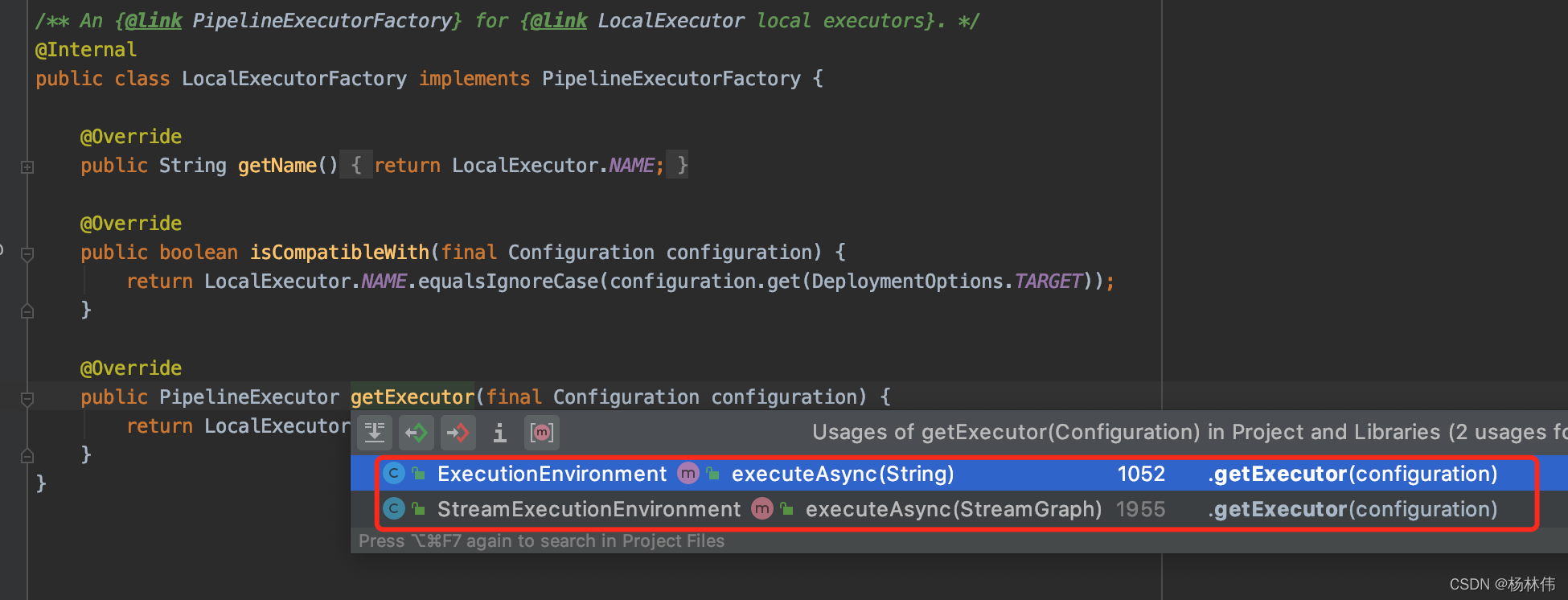
哦豁,这不是我们日常做Flink开发常用的两个类了么。随便打开StreamExecutionEnviroment这个类看看。
2.8 StreamExecutionEnviroment
可以看到,在里面的executeAsync方法代用了:

到这里,我们知道了配置是从用户初始化StreamExecutionEnviroment传入的。
03 小结
具体指标的参数从哪里获取,我们有了一个很好的分析思路了,我们可以自己编写一个Flink的程序,使用的是StreamExecutionEnviroment,然后断点本文的源码,就知道来龙去脉了。
本文由于篇幅原因,在下一篇博客继续讲解。
版权声明
本文为[杨林伟]所创,转载请带上原文链接,感谢
https://yanglinwei.blog.csdn.net/article/details/124289091
边栏推荐
- TCP三次握手和四次挥手
- Seven steps of PLC project commissioning
- CefSharp存储Cookie和读Cookie
- Navicat mistakenly deleted the connection. How to restore the database
- Charles使用之修改请求和响应的三种方式
- 为什么我那么看重文档命名?
- Shrio study notes (II)
- 实验6 输入输出流
- Web automation: 6 Operation of selenium drop-down selection box - Select
- Primary test: ordinary vs excellent
猜你喜欢

Shiping information participated in the enterprise roadshow of Hengyang "Chuanshan forum", talked about data security and helped collaborative innovation
MySql查询指定一行排序到第一行
.Net5中使用Swagger

Supersocket is Use in net5 - websocket server
web自动化:5.2selenium鼠标操作原理:ActionChains-延时调用

Shrio 学习笔记(一)

Shrio 学习笔记(二)

.Net5 Log4Net启动一段时间后记录日志到数据库中失败问题

Exploration of MySQL index
SuperSocket在.Net5中使用——AppSession和SuperSocketService篇

随机推荐
MySql查询指定一行排序到第一行
世平信息上榜《CCSIP 2021中国网络安全产业全景图》
jmeter 接口请求出现安全验证解决方案
web问题定位实战:2.提示信息、字段校验
php 使用redis简单实例
IDE-IDEA-问题
.net WebAPI访问授权机制及流程设计(header token+redis)
Charles使用之修改请求和响应的三种方式
专注数据安全,世平信息上榜中国网络安全行业全景图六大细分领域
.NetCore设置API post方式可以直接括号内接受参数
WordPress personal website construction
ui自动化登录绕过验证码
pytest_第一节课
adb 命令总结
Figure 2022 work plan of industrial Internet special working group
世平信息参与衡阳市“船山论坛”企业路演,畅谈数据安全,助力协同创新
Fiddler使用
Shiping information appeared at the China traditional Chinese medicine information conference to help build the data security system of the pharmaceutical industry
[Shiping information] solutions for confidentiality inspection and compliance control of recorded content
Flash data model migration error