当前位置:网站首页>学习小笔记---机器学习
学习小笔记---机器学习
2022-08-09 06:56:00 【Anakin6174】
看书的时候做点笔记,偶尔翻出来看看才能真正掌握;否则很快就遗忘了(艾宾浩斯遗忘曲线)。
1 集成学习
集成学习 (ensemble learning)通过构建并结合多个学习器来完成学习任务。
根据个体学习器的生成方式 ,集成学习方法大致可分为两大类:即个体学习器问存在强依赖关系、必须串行生成的序列化方法?以及个体学习器间不存在强依赖关系、可同时生成的并行化方法;前者的代表是 Boosting,后者的代表是 Bagging 和"随机森林" (Random Forest) 。
Boosting 是一族可将弱学习器提升为强学习器的算法.这族算法的工作机制类似:先从初始训练集训练出一个基学习器,再根据基学习器的表现对训练样本分布进行调整,使得先前基学习器做错的训练样本在后续受到更多关注,然后基于调整后的样本分布来训练下一个基学习器;如此重复进行,直至基学习器数目达到事先指定的值 T , 最终将这 T 个基学习器进行加权结合.Boosting 族算法最著名的代表是 AdaBoost 。
Bagging与随机森林
欲得到泛化性能强的集成,集成中的个体学习器应尽可能相互独立;虽然"独立"在现实任务中无法做到,但可以设法使基学习器尽可能具有较大的差异.给定一个训练数据集,一种可能的做法是对训练样本进行采样,产生出若干个不同的子集,再从每个数据子集中训练出一个墓学习器.这样,由于训练数据不同,我们获得的基学习器可望具有比较大的差异.
Bagging基于自助采样法;给定包含 m 个样本的数据集,我们先随机取出一个样本放入采样集中,再把该样本放回初始数据集,使得下次采样时该样本仍有可能被选中,这样,经过 m次随机采样操作,我们得到含 m 个样本的采样集,初始训练集中有的样本在采样集里多次出现,有的则从未出现.由式 (2.1)可知,初始训练集中约有 63.2%的样本出现在来样集中.
照这样,我们可采样出 T 个含 m 个训练样本的采样集,然后基于每个采样集训练出一个基学习器,再将这些基学习器进行结合.这就是 Bagging 的基本流程.在对预测输出进行结合时, Bagging 通常对分类任务使用简单投票法,对回归任务使用简单平均法。
自助采样过程还给 Bagging 带来了另一个优点:由于每个基学习器只使用了初始训练集中约 63.2% 的样本,剩下约 36.8% 的样本可用作验证集来对泛化性能进行"包外估计" 。
随机森林(Random Forest,简称 RF)是 Bagging的一个扩展变体.在以决策树为基学习器构建 Bagging 集成的基础上,进一步在决策树的训练过程中引入了随机属性选择.具体来说,传统决策树在选择划分属性时是在当前结点的属性集合(假定有 d 个属性)中选择一个最优属性;而在RF 中,对基决策树的每个结点,先从该结点的属性集合中随机选择一个包含 k 个属性的子集,然后再从这个子集 中选择一个最优属性用 于划分. 这里的参数k 控制了 随机性的引入程度 ;若令 k = d , 则基决策树的构建与 传统决策树相同;若令 k = 1 , 则是随机选择一个属性用 于划分 ; 一般情况下,推荐值 k = log2 d[Breiman, 2001].
随机森林中基学习器的多样性不仅来自样本扰动,还来自属性扰动,这就使得最终集成的泛化性能可通过个体学习器之间差异度的增加而进一步提升。
2, 如何进行多样性增强?
在集成学习中需有效地生成多样性大的个体学习器 . 与简单地直接用初始数据训练出个体学习器相比,如何增强多样性呢?一般思路是在学习过程中引入随机性,常见做法主要是对数据样本、 输入属性、输出表示 、 算法参数进行
扰动 。
3,特征选择
作用:
1,现实任务中常遇到维数灾难问题,若能选择出重要的特征,仅在一部分特征上构造模型,则维数灾难问题可大为减轻;
2,去除不相关的特征往往会降低学习任务的难度,就像侦探破案一样,若将纷繁复杂的因素抽丝剥茧,只留下关键因素,则真相往往更易看清。
3,减少涉及的计算和存储开销
选择过程:子集搜索 + 子集评价(可用信息熵增益)
常见特征选择分为三大类:过滤式(filter)、包裹式(wrapper)、嵌入式(embedding);
过滤式方法先对数据集进行特征选择,然后再训练学习器,特征选择过程与后续学习器无关.这相当于先用特征选择过程对初始特征进行"过滤",再用过滤后的特征来训练模型.
包裹式特征选择直接把最终将要使用的学习器的性能作为特征于集的评价准则.换言之,包裹式特征选择的目的就是为给定学习器选择最有利于其性能、 "量身走做"的特征子集.
在过滤式和包裹式特征选择方法中,特征选择过程与学习器训练过程有明显的分别;与此不同,嵌入式特征选择是将特征选择过程与学习器训练过程融为一体,两者在同一个优化过程中完成,即在学习器训练过程中自动地进行了特征选择.
4 L1范式与L2范式


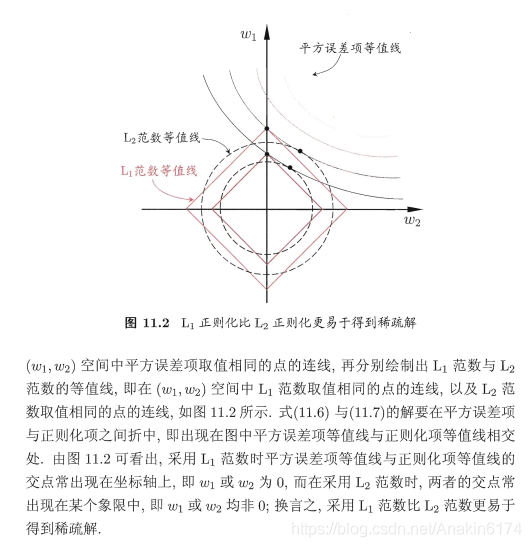
总的来说,L1与L2范式都可以降低过拟合风险,但L1更容易获得稀疏解。
5 强化学习(Reinforcement Learning)简介
强化学习是机器学习中的一个领域,强调如何基于环境而行动,以取得最大化的预期利益。其灵感来源于心理学中的行为主义理论,即有机体如何在环境给予的奖励或惩罚的刺激下,逐步形成对刺激的预期,产生能获得最大利益的习惯性行为。(得到一种策略)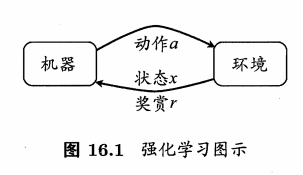
强化学习任务通常用马尔可夫决策过程 (Markov Decision Process,简称 MDP)来描述:机器处于环境 E 中,状态空间为 X,其中每个状态 x 属于X ,是机器感知到的环境的描述,如在种瓜任务上这就是当前瓜苗长势的描述;机器能采取的动作构成了动作空间 A , 如种瓜过程中有浇水、施不同的肥、使用不同的农药等多种可供选择的动作;若某个动作 a属于A 作用在当前状态 x上,则潜在的转移函数 P 将使得环境从当前状态按某种概率转移到另 A个状态,如瓜苗状态为缺水,若选择动作浇水,则瓜苗长势会发生变化,瓜苗有一定的概率恢复健康,也有一定的概率无法恢复;在转移到另一个状态的同时,环境会根据潜在的"奖赏" (reward) 函数 R 反馈给机器一个奖赏,如保持瓜苗健康对应奖赏 +1,瓜苗凋零对应奖赏-10,最终种出了好瓜对应奖赏 +100. 综合起来,强化学习任务对应了四元组 E = (X,A,P,R),其中 P:X×A×X -->R 指定了状态转移概率 , R:X×A×X -->R 指定了奖赏;在有的应用中,奖赏函数可能仅与状态转移有关,即 R:X×X -->R .
需注意"机器"与"环境"的界限,例如在种西瓜任务中,环境是因瓜生长的自然世界;在人棋对弈中,环境是棋盘与对手;在机器人控制中,环境是机器人的躯体与物理世界.总之,在环境中状态的转移、奖赏的返回是不受机器控制的,机器只能通过选择要执行的动作来影响环境,也只能通过观察转移后的状态和返回的奖赏来感知环境。
机器要做的是通过在环境中不断地尝试而学得一个"策略" (policy) π,根
据这个策略,在状态 z 下就能得知要执行的动作 α= π(x) , 例如看到瓜苗状态是缺水时,能返回动作"浇水"策略有两种表示方法:二种是将策略表示为函数π :X -->A , 确定性策略常用这种表示;另一种是概率表示汀 :X×A–>R.,
随机性策略常用这种表示.π(x ,α) 为状态 x下选择动作 α 的概率;这里必须有∑π(x ,α)= 1 ;
强化学习在某种意义上可看作具有"延迟标记信息"的监督学习问题.
“K-摇臂赌博机”可以看做是一个单步强化学习的实例。
在强化学习的经典任务设置中,机器所能获得的反馈信息仅有多步决策后的累积奖赏,但在现实任务中,往往能得到人类专家的决策过程范例,例如在种瓜任务上能得到农业专家的种植过程范例.从这样的范例中学习,称为"模仿学习" (imitation learning) 。
深度强化学习全称是 Deep Reinforcement Learning(DRL),其所带来的推理能力 是智能的一个关键特征衡量,真正的让机器有了自我学习、自我思考的能力。深度强化学习(Deep Reinforcement Learning,DRL)本质上属于采用神经网络作为值函数估计器的一类方法,其主要优势在于它能够利用深度神经网络对状态特征进行自动抽取,避免了人工 定义状态特征带来的不准确性,使得智能体Agent能够在更原始的状态上进行学习。
6 基于梯度的学习
线性模型和神经网络的最大区别,在于神经网络的非线性导致大多数我们感兴趣的损失函数都成为了非凸的。这意味着神经网络的训练通常使用的迭代的、基于梯度的优化,仅仅使得代价函数达到一个非常小的值;而不是像用于训练线性回归模型的线性方程求解器,或者用于训练逻辑回归或SVM的凸优化算法那样具有全局的收敛保证。凸优化从任何一种初始参数出发都会收敛(理论上如此——在实践中也很鲁棒但可能会遇到数值问题)。用于非凸损失函数的随机梯度下降没有这种收敛性保证,并且对参数的初始值很敏感。对于前馈神经网络,将所有的权重值初始化为小随机数是很重要的。偏置可以初始化为零或者小的正值。训
练算法几乎总是基于使用梯度来使得代价函数下降的各种方法即可。一些特别的算法是对梯度下降思想的改进和提纯。
深度神经网络设计中的一个重要方面是代价函数的选择。
贯穿神经网络的一个主题是代价函数的梯度必须足够的大和具有足够的预测性,来为学习算法提供一个好的指引。饱和(变得非常平)的函数破坏了这一目标,因为它们把梯度变得非常小。这在很多情况下都会发生,因为用于产生隐藏单元或者输出单元的输出的激活函数会饱和。负的对数似然帮助我们在很多模型中避免这个问题。很多输出单元都会包含一个指数函数,这在它的变量取绝对值非常大的负值时会造成饱和。负对数似然代价函数中的对数函数消除了某些输出单元中的指数效果。
边栏推荐
- 默默重新开始,第一页也是新的一页
- 简单工厂模式
- 移远EC20 4G模块拨号相关
- 高项 03 项目立项管理
- Search 1688 product interface by image (item_search_img-search 1688 product by image (Politao interface) code docking tutorial
- 2022.8.8DAY628
- Error jinja2.exceptions.UndefinedError: 'form' is undefined
- Error: flask: TypeError: 'function' object is not iterable
- 我入职阿里后,才知道原来简历这么写
- 排序第二节——选择排序(选择排序+堆排序)(两个视频讲解)
猜你喜欢
移远EC20 4G模块拨号相关

细谈VR全景:数字营销时代的宠儿
ByteDance Interview Questions: Mirror Binary Tree 2020
CMake中INSTALL_RPATH与BUILD_RPATH问题
The working principle of the transformer (illustration, schematic explanation, understand at a glance)
ByteDance Written Exam 2020 (Douyin E-commerce)
Fragments

Variable used in lambda expression should be final or effectively final报错解决方案
字节跳动面试题之镜像二叉树2020
高项 04 项目整体管理
随机推荐
先序遍历,中序遍历,后序遍历,层序遍历
Import the pycharm environment package into another environment
Rsync常见错误
2022-08-08: Given an array arr, it represents the height of the missiles that will appear in order from morning to night.When the cannon shoots missiles, once the cannon is set to shoot at a certain h
io.lettuce.core。RedisCommandTimeoutException命令超时
String.toLowerCase(Locale.ROOT)
【ROS2原理8】节点到参与者的重映射
Common Oracle Commands
常用测试用例设计方法之正交实验法详解
【报错】Root Cause com.mysql.jdbc.exceptions.jdbc4.CommunicationsException: Communications link failure
makefile记录
Fragments
leetcode:55. 跳跃游戏
APP product source data interface (taobao, jingdong/spelling/suning/trill platform details a lot data analysis interface) code and docking tutorial
Built-in macros in C language (define log macros)
VS2019 common shortcut keys
移远EC20 4G模块拨号相关
MySQL高级特性之分布式(XA)事务的介绍
Variable used in lambda expression should be final or effectively final报错解决方案
Introduction and use of BeautifulSoup4