当前位置:网站首页>基本比例尺标准分幅编号流程
基本比例尺标准分幅编号流程
2022-08-10 05:29:00 【PyGata】
一、地图分幅简介
- 首先,我国基本比例尺地形图有新旧两种分幅编号,且均是在国际规定的1:100万地形图基础上,按规定的经差和纬差采用逐次加密划分方法划分图幅,使相邻比例尺地图的经纬差、行列数和图幅数成简单的倍数。以新版图幅编号为例,我国地形图含有8种基本比例尺,分别是:1:5000、1:1万、1:2.5万、1:5万、1:10万、1:25万、1:50万、1:100万。在旧标准标号中则没有1:25w,而是1:20w。
- 1:100万地图的分幅编号:每幅1:100万地图纬差4°经差6°。从地球赤道起,向两极每纬度4°为一行,依次以字母A,B,C,…,V表示;从西经180°起,向东每6°为一列,依次以数字l,2,3,…,60表示。每幅图的编号由该图幅所在的行号(字符码)和列号(数字码)组成,列号在前,行号在后,二者之间划一短线。如北京在1:100万图上处于第J列第50行,故编号为J-50,也可简写为J50。
- 1:50万-1:5000地图的编号以1:100万地图编号为基础,按行列编号方法,即将1:100万地形图按所含各比例尺地形图的经差和纬差划分成若干行和列,横行从上到下、纵列从左到右按顺序分别用阿拉伯数字(数字码)编号。
- 具体规定与解释参考以下博文,本文不做详述,只阐述利用Arcgis制作8种基本比例尺地形分幅编号的方法。
二、基本比例尺分幅及编号
- 使用软件:Arcgis10.7
- 坐标系:CGCS2000
- 需了解的基础工具与知识:渔网工具、空间连接工具、利用python进行字段计算、model模型工具箱
(一)1:100W比例尺分幅编号
1、模板数据
模板数据来源于全国地理信息资源目录服务系统1:100w全国基础地理数据库分幅数据提取得到的边界,该网站公布了1:100w地理数据库,按标准图幅分为77幅,只能单独下载。拼接该数据的BOUA图层后新建一字段“country”,令其全为China,利用该字段融合所有离散面,结果如下图: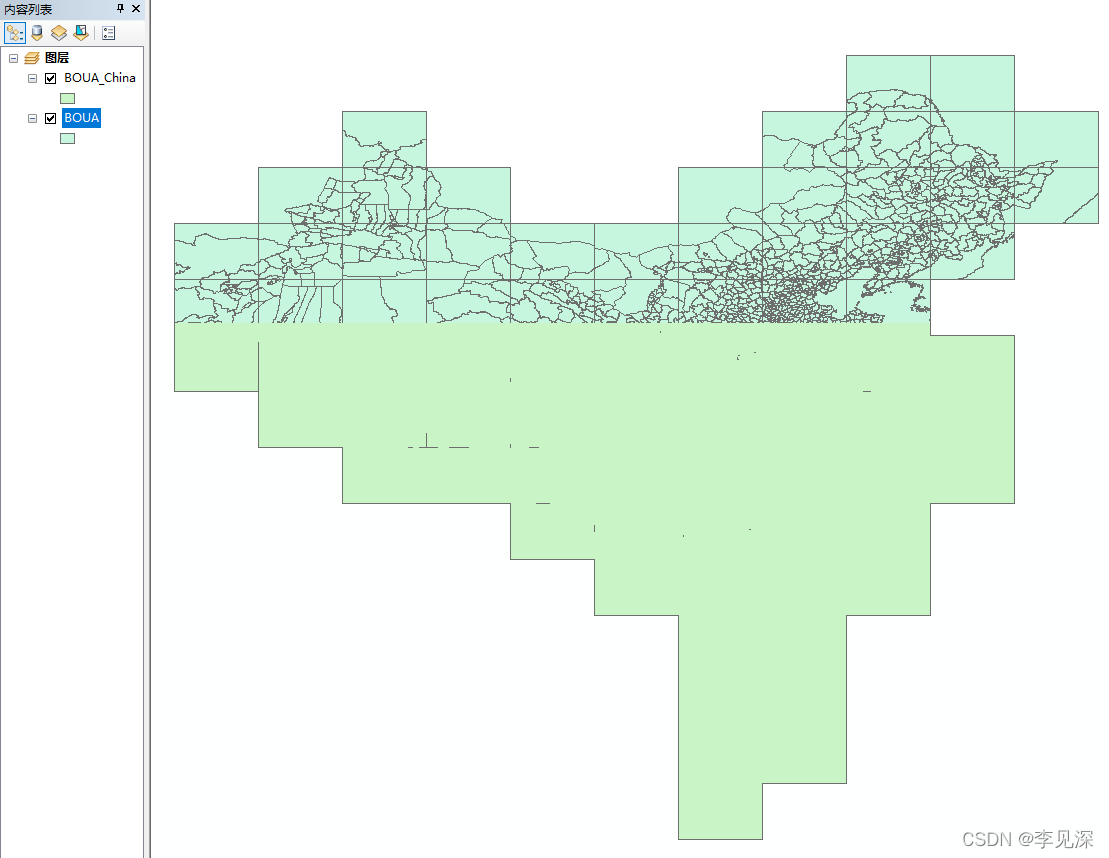
2、制作流程
首先利用渔网工具制作中国区域1:100w基本比例尺图幅,中国区域范围:维度0° ~ 56°、经度72° ~ 138,每一幅1:100w分幅的维差4°,经差6°。如下图,像元宽度为每幅图的经差,故为6,计算得到列数为11;像元高度为每幅图的维差,故为4,计算得到行数为14;点击取消标注点,选择输出几何类型为面,输出要素类命名为A,即对应1:100w比例尺编码。故填写参数如下: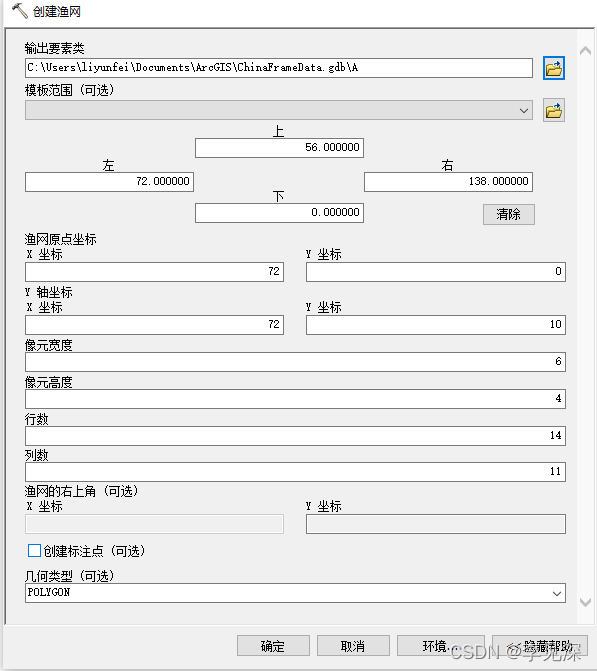
如下图,打开生成的属性表,新建双精度字段:lat_center、lon_center,利用“计算几何”得到每个分幅中心点经纬度。
但发现出现偏差,具体原因鄙人不太清楚(是和大地线和法截线有关吗,求大佬路过解答),故只能选择以上述模板数据作为模板范围生成1:100w图幅,查看其属性表后发现其结果正确无误。

接下来通过“空间连接”工具将“country”字段连接"A图层"(为了后续筛选中国区域分幅,当然也可以直接在下图取消“保留所有目标要素”),具体参数如下图: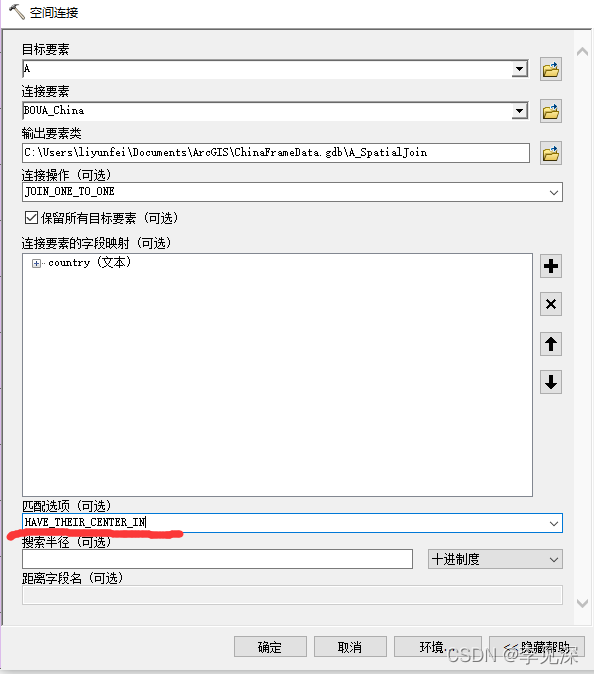
完成“country”字段连接后,删除"A"图层,更改"A_SpatialJoin"图层为"A"图层。
上图为经过"空间连接"后,该图层属性表,拥有“country”字段,质心坐标正确。
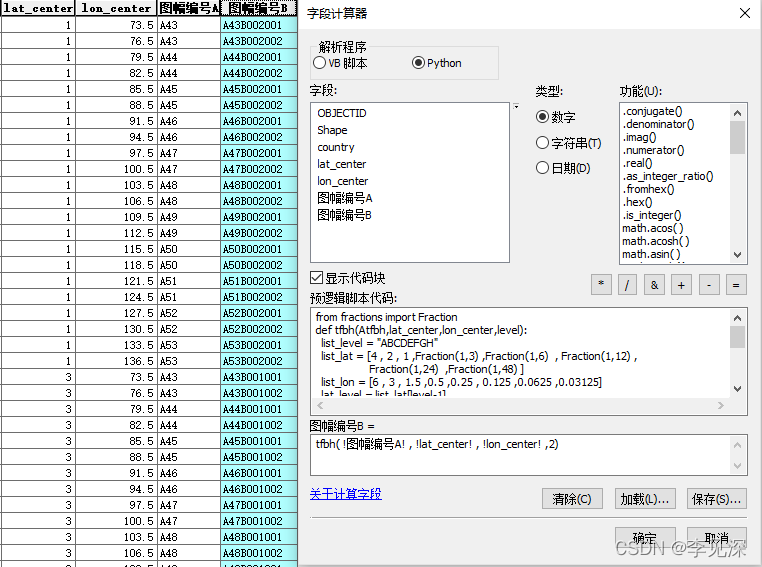
进行下一步:添加一文本类型、长度为10的字段,命名为“图幅编号A”,然后利用字段计算器根据分幅图的质心经纬度计算得到各分幅的图幅编号,计算公式、结果与python脚本函数如下:
1:100万图幅的行号和列号计算公式
1:100行号 = [纬度/4] +1 []表示取整,1为A,2为B…
1:100列号 = [经度/6]+31 []表示向下取整
""" 执行:Atfbh( !lat_center! , !lon_center! ) """
def Atfbh(lat_center,lon_center):
car = "ABCDEFGHIJKLMNOPQRSTUV"
num = int(math.floor( int(lat_center) / 4 )+1)
oid_lat = car[num-1]
oid_lon = int( math.floor( int(lon_center) / 6 )+31)
tfbh = oid_lat + str(oid_lon)
return tfbh
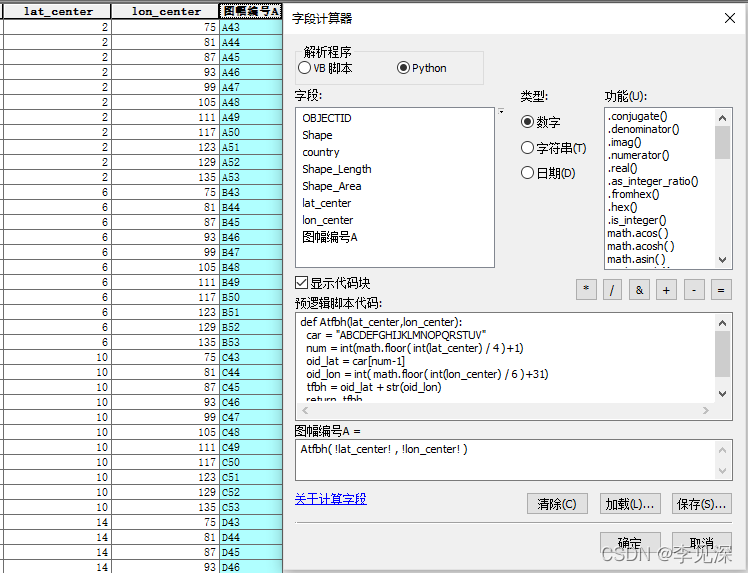
以“图幅编号A”字段标注图层,结果如下: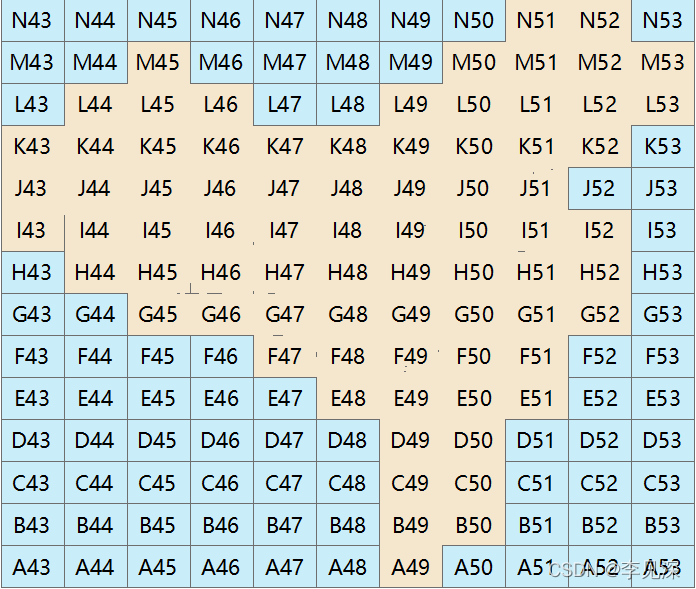
(二)1:50W比例尺分幅编号
1、分幅过程
创建渔网,1:50w分幅维差为2、经差为3,行列数相比1:100w翻倍,输出要素类命名为B,即对应1:50w比例尺编码,具体参数如下: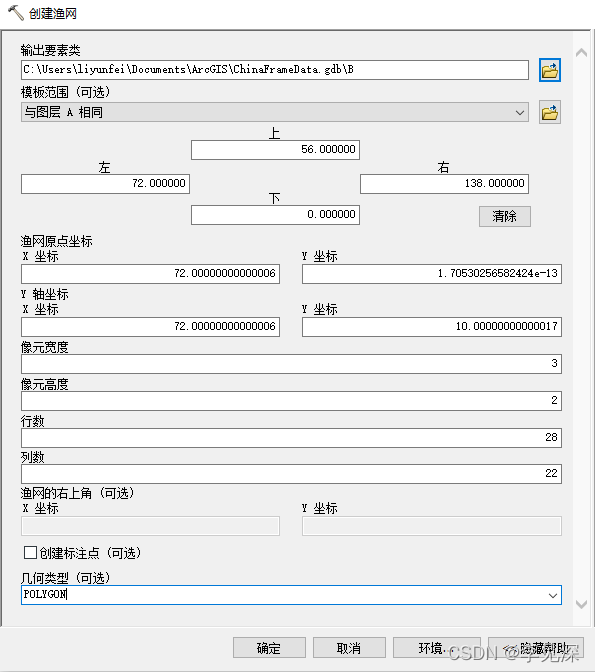
2、编码过程
进行“空间连接”操作,谈一下这个操作的意义:比如对于J50分幅,将其图幅编号赋予对应的4个1:50w分幅,同时将质心经纬度、“country”字段保留,后续不用新建直接使用,填写参数如下图(注意匹配选项):

如上图,打开修改图层名称后的“B”图层的属性表,删除和关闭不需要的字段,更新质心经纬度,添加一文本类型、长度为10的字段,命名为“图幅编号B”,然后利用字段计算器根据分幅图的质心经纬度计算得到各分幅的图幅编号,计算公式、结果与python脚本函数如下:
非1:100万图幅的行号和列号计算公式
行号 = 4º/纬差 - [(纬度/4º)/纬差] []为取整,()为取余
列号 = [(经度/4º)/经差]+1 []为取整,()为取余
1:50万图幅,经差为:3°,纬差为:2°
""" 输出为1:100万比例尺图幅编,非1:100w各分幅质心经纬度 还有比例尺级别,在此为了方便,用2345678代替BCDEFGH 执行:tfbh( !图幅编号A! , !lat_center! , !lon_center! ,2) """
from fractions import Fraction
def tfbh(Atfbh,lat_center,lon_center,level):
list_level = "ABCDEFGH"
list_lat = [4 , 2 , 1 ,Fraction(1,3) ,Fraction(1,6) , Fraction(1,12) ,
Fraction(1,24) ,Fraction(1,48) ]
list_lon = [6 , 3 , 1.5 ,0.5 ,0.25 , 0.125 ,0.0625 ,0.03125]
lat_level = list_lat[level-1]
lon_level = list_lon[level-1]
level_letter = list_level[level-1]
lat_center = float(lat_center)
lon_center = float(lon_center)
num_lat =str(1000 + int(4 / lat_level - math.floor(( lat_center%4)/ lat_level )))
num_lon = str(1000 + int(math.floor((lon_center%6)/ lon_level) + 1))
tfbh = Atfbh + level_letter + num_lat[-3:] + num_lon[-3:]
return tfbh
以“图幅编号B”字段标注图层,叠加1:100w分幅,结果如下:
(三)其余基本比例尺分幅编号
其余基本比例尺分幅编码步骤与上述1:50w完全一致
按照上表经纬差进行其余比例尺分幅出图,下方展示其中一些过程数据
如下图:1:25w基本比例尺分幅图"创建渔网"参数设置
如下图:J50D012012分幅内部1:5w、1:2.5w分幅及编号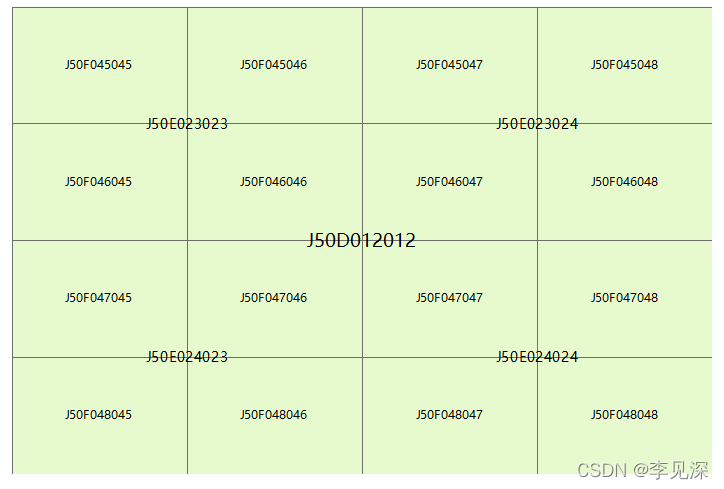
如下图:1:2.5w分幅出图结果,J50下共计48*48=2304个1:2.5w分幅。
如下图:J50F048048分幅内部1:1w、1:5000分幅及编号
(四)分幅编号结果展示
以下为一个小流域所占据的1:1w比例尺地形图的图幅与编号,写这篇文章也是因为我想快速知道一些区域它位于哪些比例尺地形图上,编码是多少,具体有哪些,这是我的目的所在。
下图则是点击提取了该小流域左上方区域一点度分秒格式经纬度,并在我个人制作的安卓工具集中使用图幅编号工具计算得到该位置1:1w地形图编号,结果与之相同,没有差错。
三、数据整理与小结
(一)数据整理
通过上述流程,我们获得了CGCS2000大地坐标系下,中国区四至坐标范围内,1:5000到1:100w八个基本比例尺分幅图及其编号,统一以其比例尺等级命名,如1:100w命名为A、1:10000命名为G。
不过上述数据是在四至范围内部,是一个矩形数据,为了精简数据,我们可以筛选中国区范围内的分幅数据,之前空间连接的“country”字段便是用来筛选的,在这里我使用Arcgis模型工具进行遍历筛选及导出,过程如下: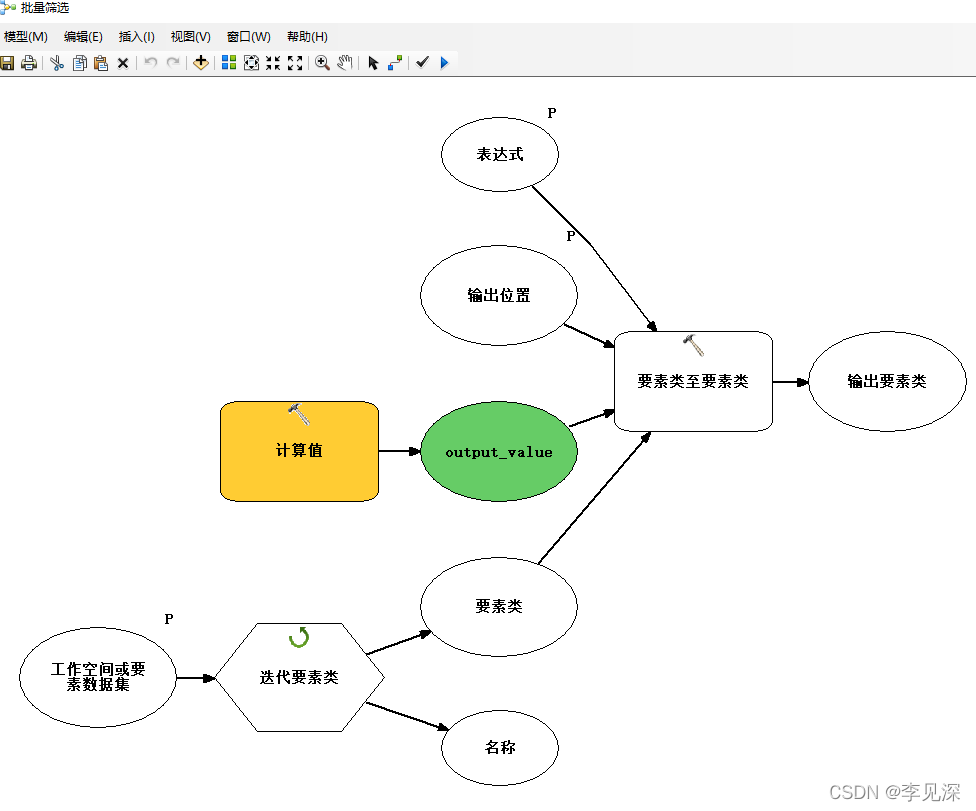
上述模型流程就是遍历地理数据库要素类,对8个要素类进行筛选,再导出,过程及结果如下:

到这里并没有结束,当我打开八个图层属性表的时候,我发现除了A图层,其他图层的图幅编号字段都没有了…
好一番找发现是这个原因,如下:
选择工作空间后就直接确定了“字段映射”,而且还不随迭代要素的变化而变化,所以最后8个要素类都只有这些字段。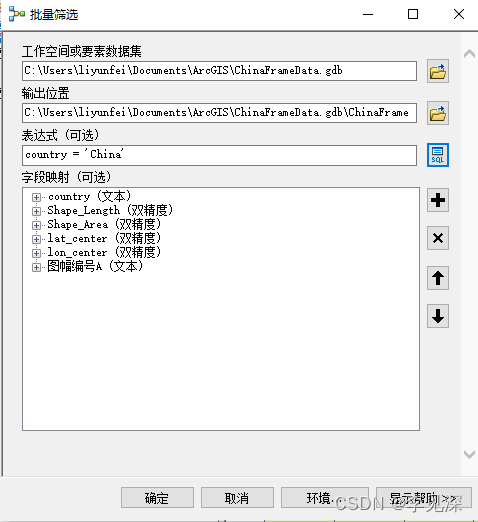
最后实在没找到解决办法(路过大佬看看怎么解决),python脚本又不想写了,直接进行批处理,浏览填充一波走起,速度也不慢,如下: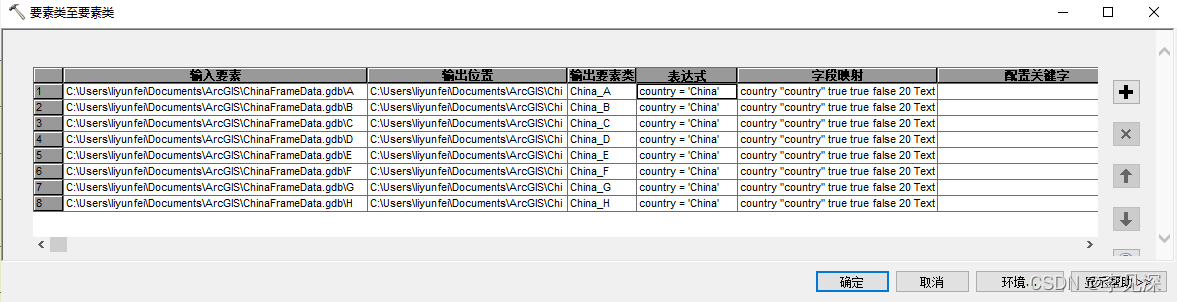
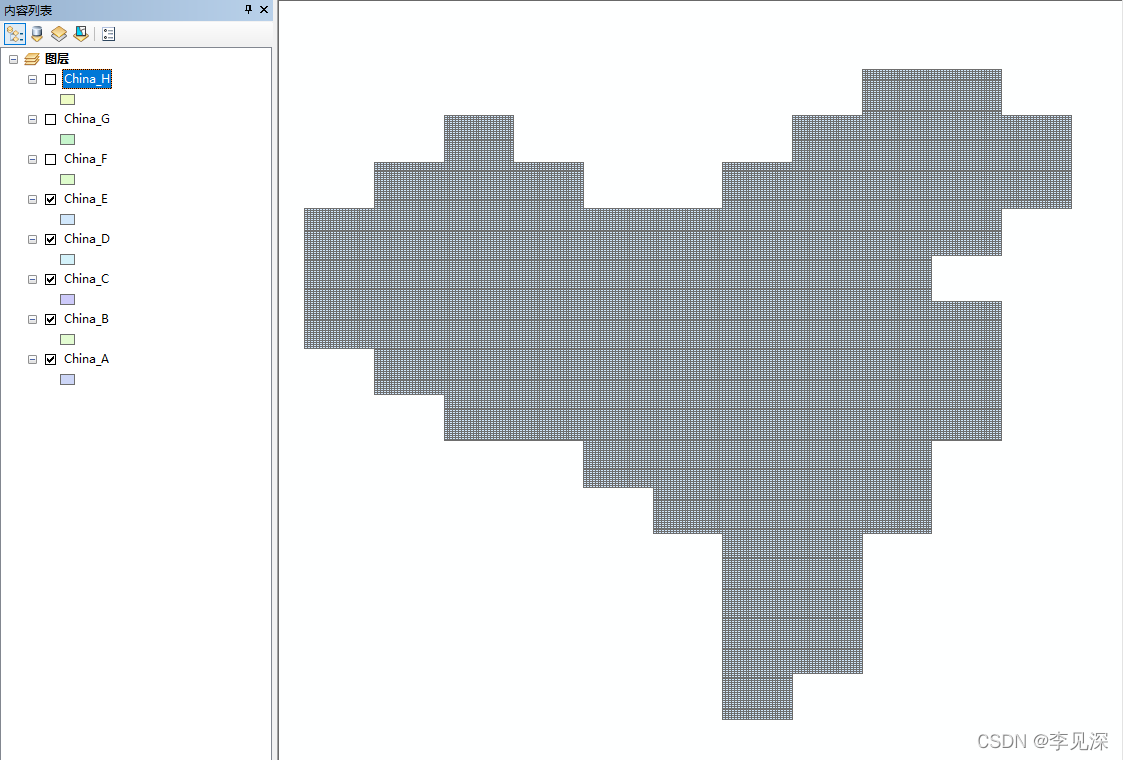

(二)小结
以上,便是本篇博文主要流程,虽然出现了一些小问题,但结果还是可以的。
这也算是本人第一篇正式的博文吧,欢迎广大朋友在评论区讨论。
此外,所有数据已经整理压缩(共计50M),若有数据需要,可以用“基本比例尺标准分幅编号数据”为标题,写明使用原因,发送至我的邮箱:[email protected],我会尽快回复。
边栏推荐
- An article will help you understand what is idempotency?How to solve the idempotency problem?
- How does flinksql write that the value of redis has only the last field?
- 一篇文章掌握整个JVM,JVM超详细解析!!!
- CORS跨域资源共享漏洞的原理与挖掘方法
- Shell编程三剑客之awk
- 栈与队列 | 有效的括号、删除字符串中的所有相邻元素、逆波兰表达式求值、滑动窗口的最大值、前K个高频元素 | leecode刷题笔记
- An article to master the entire JVM, JVM ultra-detailed analysis!!!
- 【Pei Shu Theorem】CF1055C Lucky Days
- strongest brain (1)
- 反转链表中的第m至第n个节点---leetcode
猜你喜欢

pytorch框架学习(6)训练一个简单的自己的CNN (三)细节篇

Pony语言学习(八):引用能力(Reference Capabilities)

Rpc interface stress test
Joomla vulnerability reproduced

What are the common commands of mysql

细数国产接口协作平台的六把武器!

Become a language that hackers have to learn. Do you think it's okay after reading it?

Kubernetes:(十六)Ingress的概念和原理

论文精度 —— 2016 CVPR 《Context Encoders: Feature Learning by Inpainting》

Conda creates a virtual environment method and pqi uses a domestic mirror source to install a third-party library method tutorial
随机推荐
Shield Alt hotkey in vscode
Linear Algebra (4)
基于Qiskit——《量子计算编程实战》读书笔记(一)
树莓派入门(4)LED闪烁&呼吸灯
You can‘t specify target table ‘kms_report_reportinfo‘ for update in FROM clause
动手写prometheus的exporter-02-Counter(计数器)
Attention candidates for the soft exam! The detailed registration process for the second half of 2022 is coming!
Pony语言学习(九)——泛型与模式匹配(终章)
How does flinksql write that the value of redis has only the last field?
pytest测试框架
Qiskit官方文档选译之量子傅里叶变换(Quantum Fourier Transform, QFT)
一文带你搞懂OAuth2.0
FPGA engineer interview questions collection 31~40
Introduction to curl command
AVL树的插入--旋转笔记
如何模拟后台API调用场景,很细!
深度梳理:防止模型过拟合的方法汇总
The time for flinkcdc to read pgsql is enlarged. Does anyone know what happened? gmt_create':1
Zhongang Mining: Strong downstream demand for fluorite
MongoDB 基础了解(一)