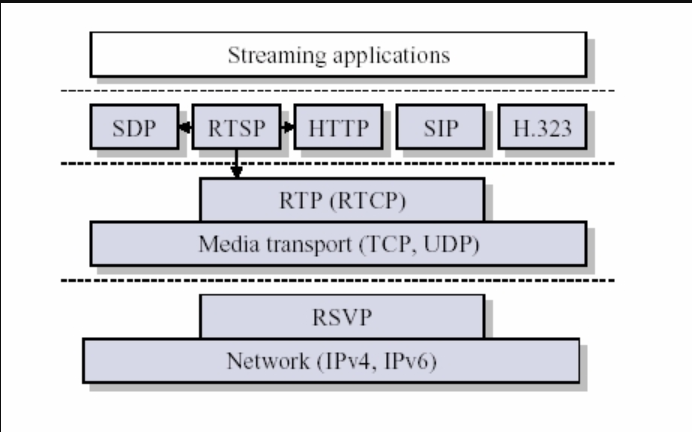
“哪些业务需求可以数字?”
“数据科学只是单纯的技术问题?”
“数据科学家的最大的挑战是什么?”
第四次工业革命来临,许多企业已经意识到了要利用数据科学能力推动商业模式的创新,尝试将经营中产生的数据转化为适配业务需求的决策模型,由原本依靠经验的“人治”变为“数治”。
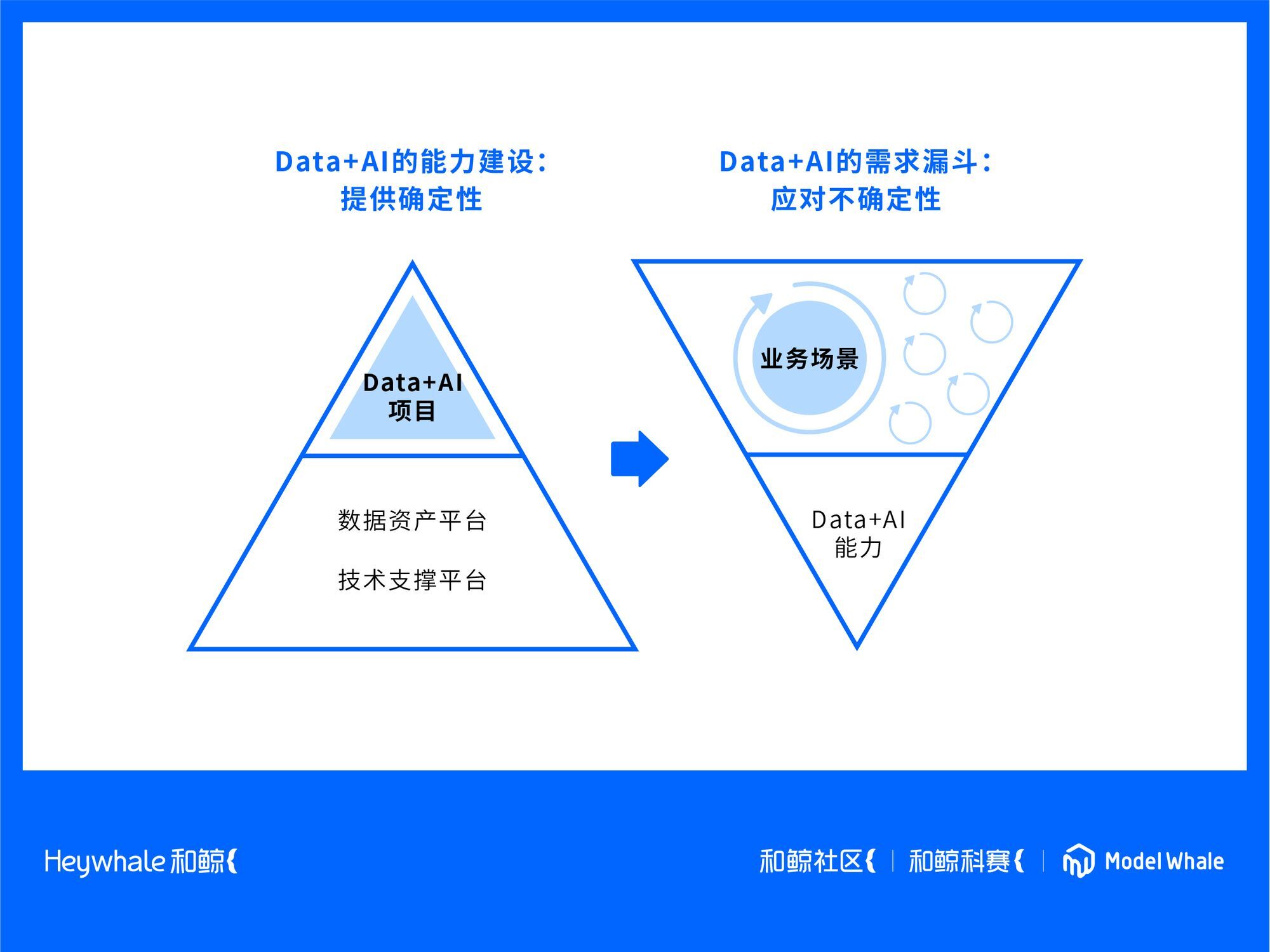
数据科学的应用领域同数据科学领域本身一样多样化,但成功突围的却是少数。“数据智能项目很难达到目标,90%的立项,最后只能草草收场。”
越是艰难,越是能让这些项目形成企业能力上的核心资产。任何企业都会产生数据,但数据本身不是万灵丹,它只是加速器,方向盘仍旧掌握在人的手中。
截至2021年,和鲸已经帮助了七个行业的 Top3 客户完成了数据智能的价值落地。将协同能力的内核落实到数据科学开发的全流程中,和鲸的经验或许能帮助大家揭开数据科学的图景。我们邀请了和鲸科技创始人兼 CEO 范向伟先生,对大家常提出的问题进行了统一回答。

和鲸科技创始人 范向伟
01 数据智能项目的两个挑战
问:
过去5、6年,大数据经历了一个高峰,也经历了一个低谷。高峰期在16-17年,市面上最贵的工程师都投身于人工智能,而低谷也就是过去两年,人工智能主流的公司在上市过程中遇到了很大的挑战。一个现象就是,大部分人工智能项目都赚不到钱,对此您怎么看?
范向伟:
现象确实存在。无论是在乙方还是在甲方内部,目前人工智能相关项目评估下来的 ROI 都很低。数据智能项目普遍达不到立项的目标,这个比例在90%,相信接触过相关项目的小伙伴都会有一些比较感同身受的经历。
和鲸作为数据科学平台,其实也做过各方面调研,我们归纳下来认为,大部分数据智能项目都面临着两个挑战,是导致项目失败的常见原因。
一个在供给侧,一个在需求侧。
供给侧,为企业数据能力负责的数据工程师或者算法科学家,都会去构建一个基础设施的金字塔结构,也就是保证底层的技术平台尽可能稳固、标准、可拓展,从而可以处理更多数据,产生更高计算效率。然后再一层层往上叠,将这个能力转化为更低的服务成本,去支撑更多需求场景。这是对数据工程师的挑战。
而需求侧,目前几乎所有可以用 KPI 描述业务的部门,都会给数据部门提需求,需求场景是指数级上升的。但100个需求场景中,合理的比例,可能只有10%,剩下的90%,是因为他缺乏业务的思路,单纯想看到更多数据报表,这就会导致需求描述不清楚。所以这是对业务人员的挑战。
这样的结构,导致数据智能项目,往往很难让做数据的人和用数据的人看到进展,因为它是一个
非线性爬坡
的过程,你不知道是在哪里被卡住了。需求本身不确定,用什么样的数据也不确定,往往还不知道自己哪里做错了,项目就被叫停了。
供给与需求的结构性矛盾
这两个挑战带来的结果是什么?
一个是更高的工程成本,或者说
指数级的工程成本
。要搭建起金字塔结构,工程师将面临着大量跟机器学习、数据分析无关的基础工作、协调工作要处理 ,需要大量时间投入。与此同时,系统搭建起来后跑模型,模型结果不好的原因也有很多,而且相互影响、相互嵌套,导致排查、调试的时间成本是指数级上升的。
另一个结果,可以概括为
更不确定的业务需求
。既然业务链条中的各种问题都会找到数据部门,那数据部门到底怎么设计数据平台的架构、怎么积累算法模型的能力、怎么安排时间,就类似于是个风险投资问题了。数据智能项目的 ROI 符合幂律分布(Power Law)——极少数项目产生的价值非常大,而大部分项目几乎不产生价值。它就要求数据科学家一定要非常慎重地去做需求分析,如果业务方无法清晰地陈述自己的需求,就很可能是伪需求。
所以这两个挑战直接导致企业中
供给和需求存在着结构性的错配
,数据部门跟业务部门常常相互不满意。业务部门想要提需求,但很难把数据智能的需求说清楚,数据权限都拿不到,或者找不到合适的数据。又因为需求不清楚,成功率不高,企业不愿意投入资源,拿不到资源,也很难完成模型的打磨。数据智能的落地,就陷入了需求不清晰、供给低质量的恶性循环。
02 从数据到业务应用的反馈闭环
问:
既然供给侧和需求侧存在着错配,那让它重新形成回路是不是就能解决这些问题了。放到实际工作场景中,供需双方该如何去做呢?可以通过彼此多“沟通”解决吗?
范向伟:
如何去做,基本原则很简单,就是按照敏捷开发的原则,把大回路拆成小回路,最重要的是,要跟业务部门掰扯清楚,业务到底想回答什么问题,要搞清楚这个事情到底有没有价值。
这是一门很大的学问,我们观察下来,大部分数据工程师都不喜欢干这个事情,不喜欢进行需求的争论和探究。但这件事又很重要,我们自己认为,
一个项目70%的成败与否都取决于这个需求是不是一个真实的需求、重要的需求
。
因为和工程相关的工作,在过去几年已经越来越成熟了,包括现在也出现了大模型,自动化调参、分布式训练的方案,这里面的平均水准越来越高。更大的问题还是在于,大部分业务需求的质量还是很低,很少有业务人才能够把自己的数据需求、算法需求给理清楚。
一个是需求的质量,一个是数据的质量
,这两块现在在 AI 的实践中问题很大。不管多优秀的算法科学家,在这两段都容易掉到坑里面去。我们能建议的,就是在实战中,数据工程师可以更多地去关注,或者说多想一想 Power Law 分布——到底这个需求有没有前途,或者说需求方到底有没有想清楚。数据智能在企业中表现出的是需求的流转,在各个业务部门都会提需求的情况下,数据科学家一定要看到整一个的大画面,要能够在需求之间进行比较和取舍。
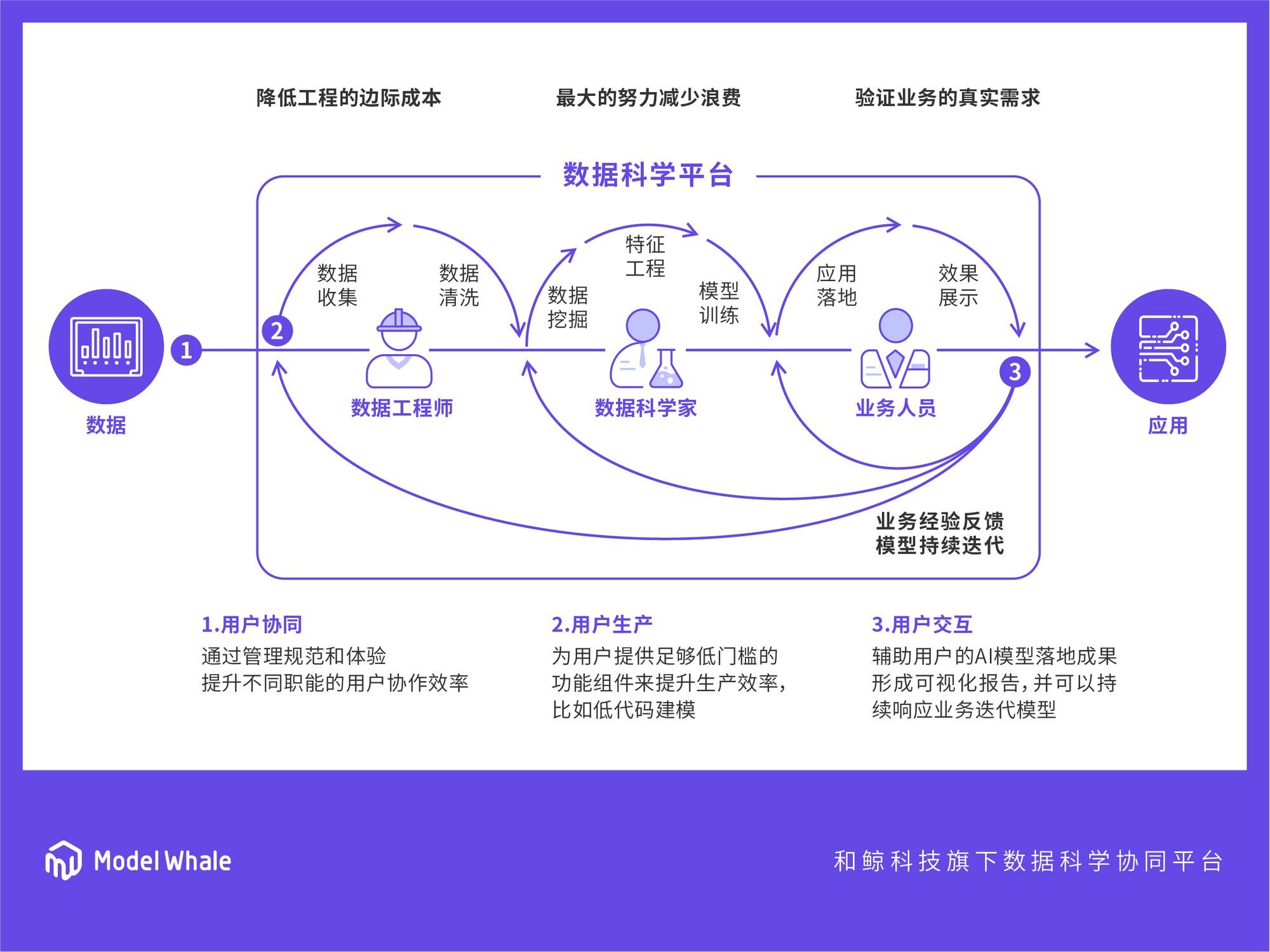
从数据到业务应用的反馈闭环
不过即使这样,想实现从数据到业务应用的反馈闭环,还是很困难。早在2016年,我们和拍拍贷、携程、百度等企业合作算法比赛的过程中,就发现了这个问题。业务需求沟通成本高,开发环境搭建、模型成果复用难度大,整个链条存在着惊人的浪费。
模型开发、模型评价、模型落地的三个环节,彼此间是断裂的。
这不是光靠“沟通”就能解决的问题。数据科学家普遍都很聪明,但工作流程却很原始,效率很低。不仅仅是重复造轮,更像是“科学家在开拖拉机”。
所以这也是和鲸产品的协同理念最开始形成的原因,就是把数据工具的开源化,和开发工具的协同化,这两个趋势结合起来。
03 三位一体:社区、赛事、工具
问:
您说到了协同,我们知道协同其实是所有的生产力工具的核心价值,任何 SaaS 产品,都需要考虑协同作为一种核心能力、核心体验。大家能理解协同的重要性,但数据科学场景下的协同有什么特殊之处呢?实现起来的难点又在哪里?
范向伟:
特殊之处,可能就是跟其他场景相比,数据科学的协同更加难以实现吧。
其实 SaaS 的协同都不好设计,看似简单的场景,做深了都是在考验产品团队的世界观。只是数据科学这件事会更难,要让数据、镜像、算力、模型、图表、文档等各个要素,在任务的各个阶段,被企业的各个角色,在业务的各个场景,都能够安全、可控、友好地被接入、被使用、被分享,这对于产品设计来说,几乎是一个不可能完成的任务。
和鲸也不是天生就有对数据科学用户和场景的敏感度的,我们在社区中天天和用户泡在一起,才看到了别人看不到的问题。
社区、赛事、工具三位一体的商业模式
就是和鲸自身最独特的协同能力,支撑着我们的协同产品 ModelWhale 有更高的研发效率、触达效率。
和鲸应该是在数据公司里面,很少能把 PLG 模式运转起来的公司,这个模式对于企业的要求很高,需要有足够多的用户,足够好的产品体验,还要有足够强的企业级价值。否则很容易陷入,有用户,但是没有收入,或者有收入,但是没有增长的两种怪圈里面。
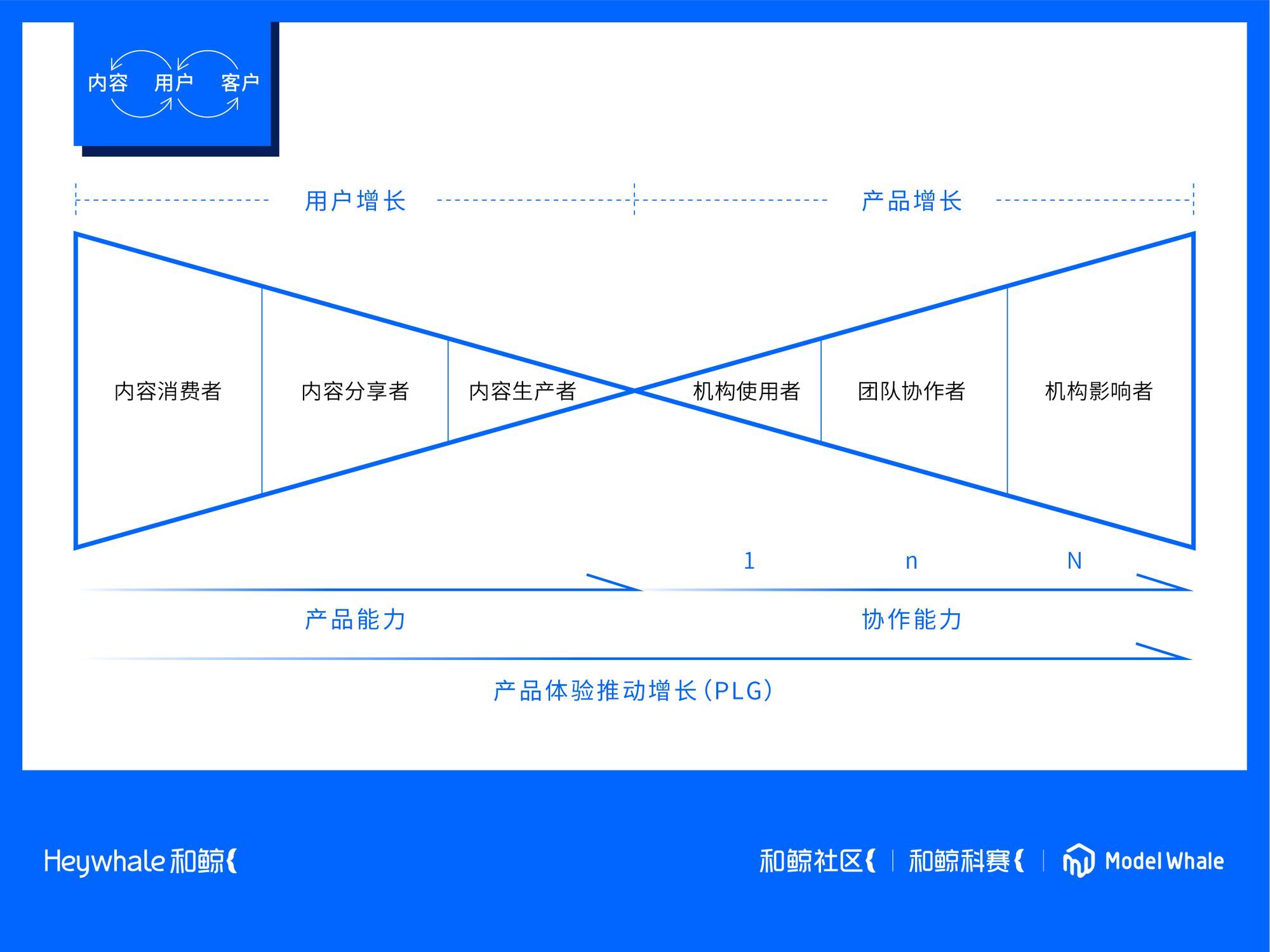
产品体验推动增长(PLG)
问:
目前在数据智能的基础设施的行业里,我们看到好像只有和鲸把机器学习的团队协同当做核心能力来建设,选择走这样一条独木桥,您有没有后悔过?
范向伟:
后悔肯定是没有,但确实发现了协同这个事儿远非我们当初想的那么简单。
开始我们只是想把 Gitlab 和 Jira 的产品模式应用在机器学习这个领域,后面发现,数据科学家协同的复杂性,比软件工程师的协同还要高一个数量级。数据科学的业务落地、能力普及,都在很早期的阶段,可能进度条只到了10%。和鲸也只是在路上。要成为一个理想的协同工具,我们做好了还有很长一段路要走的心理准备。
在数据科学团队协作产品这个赛道里,中国几乎没有细分定位的生存土壤,我们的产品只有越来越厚,才能生存下来。虽然中间确实走过一些弯路,但比较高兴的是,16年到现在,和鲸在协同这件事情上,还是走到了很深的无人区。
和鲸社区场景和赛事场景的协同深度都是很少见的,ModelWhale 已经包括了
团队级协同
(数据科学家、数据分析师之间的协作)、
企业级协同
(IT、数据、业务部门之间的协作)和
产业级协同
(企业和供应商、科研院所、社区开发者的协同),每一层又都相互穿透、相互支撑。
所以在2021年,我们看到有七个行业的 Top3 客户都做出了产品置换的决策,从同类产品迁移到了 ModelWhale ,这对于我们来说,是比较实在的鼓励,因为 PaaS 产品的竞争力,很大程度上是由行业标杆客户定义的。
04 工作流:用更好的数据回答问题
问:
Gartner 已经把“协同”定义成数据科学平台和机器学习平台的核心能力,相信未来大家会越来越重视。那我们回到之前的话题,既然数据部门和业务部门之间很难合作起来,和鲸的产品是如何去帮助他们实现的?有没有比较典型的客户案例实践可以给大家参考?
范向伟:
我们的理念很简单,就是把之前说的全链路放到一个统一的工作环境中。当然,理念虽然简单,工程实现还是很复杂,产品设计也有很多挑战。
首先,前端不仅要有开发环境,还要能
把整体逻辑先拆开、再拉通
,让业务部门明白你的代码、你的模型是什么意思,你用了什么数据,比如哪个环节是在接入数据,哪个环节是在建模,哪个环节是在做预测。总之,要让业务部门能尽可能看懂,并且提出来自于业务视角的问题和建议。
其次,机器学习中的很多问题,归根结底是数据问题,很多问题的解决只是因为找到了很好的数据。但是数据质量存在着巨大的方差,而工程师是不太喜欢跟数据打交道的,这是“杂活累活”。所以 ModelWhale 会把各种各样的数据源,做干净的接入,可以实现
数据和模型开发的全流程的对接、管控和追溯
。
另外,做好成果沉淀、代码沉淀,在数据科学、机器学习项目中是很容易被忽视的,会造成很多重复劳动、资源浪费。机器学习项目经常处于一种黑箱状态,没有办法讲清楚到底哪个环节发生了问题,反正模型效果就是不好。所以每个阶段的思路,不同参数、不同版本、不同结果,最后都应该变成一个知识库,支撑未来的复用和迭代。
模型环节也有很复杂的流转和很长的生命周期,“模型要用”和“模型要改”,这两件事情永远做不完,怎么用一个工作流水线,让它的效率能够大幅提升就很重要。一旦某个模型跑通了,只要过程是可以追溯的,结果是可以复现的,企业就会发现机器学习是可靠的、有用的,并产生更多模型开发的需求。
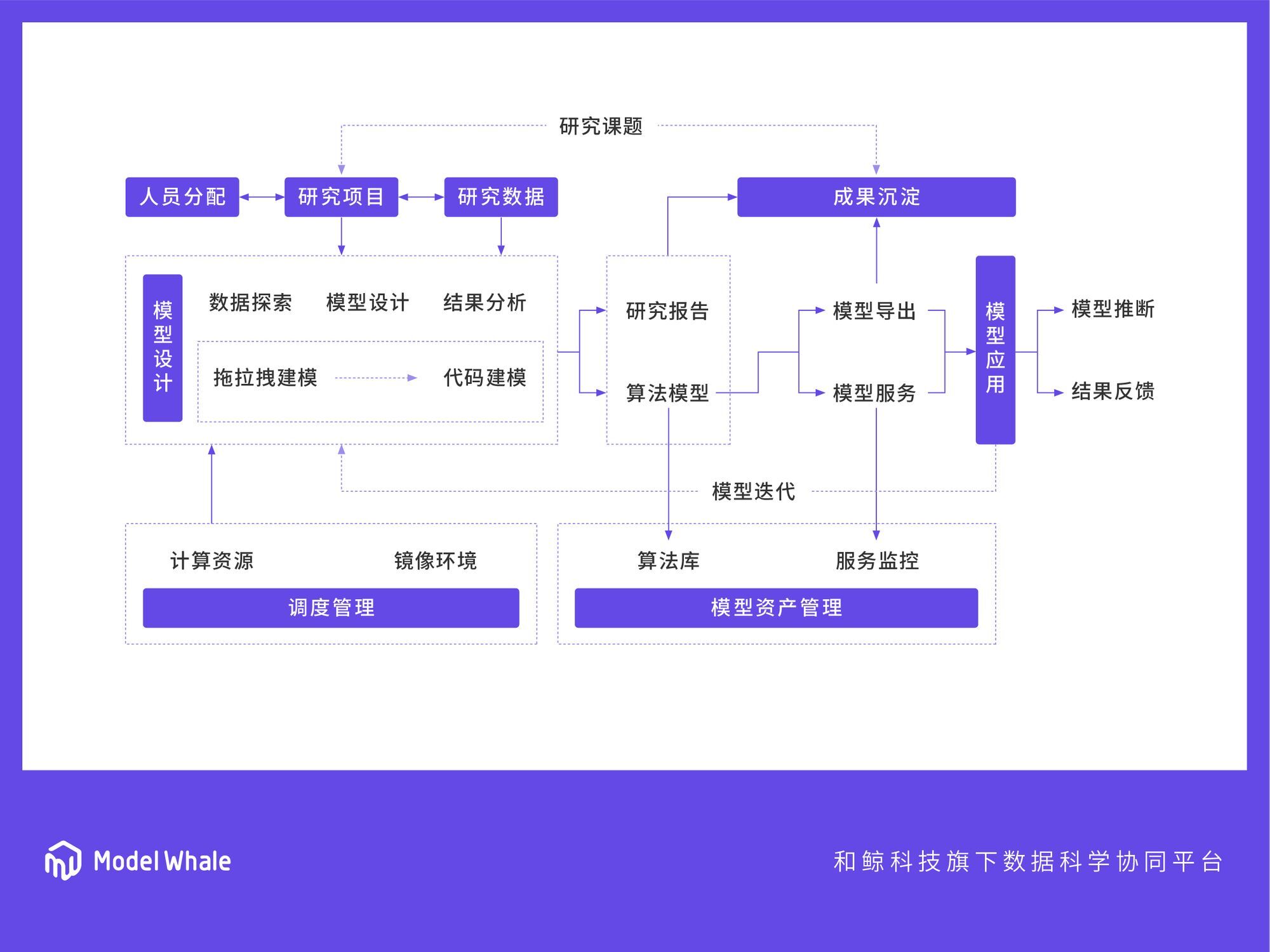
ModelWhale 适用研究
因为新能源也是未来的支柱产业,产业需求和数据科学协同平台的关系,我可以介绍一下金风科技的案例。大家可能很难理解说人工智能去预测一个风机的运行状态,这有什么难的,用个逻辑回归不就可以判断哪些机器有故障了吗。站在理论的角度是这样,模型的原理就是这样的,但这只解决了所有问题的10%。风机在沙漠里,草原上、海里等等不同的地理环境,数据用什么方式回传,是在端上处理还是回到数据中心处理,要处理通信问题、网络问题和设备问题。风机故障也有很多种不同的原因,是因为电击,还是低温结冰,又或是风速太大叶片断裂了,也对应了不同的干预策略,涉及到了IT、运维、数据等不同部门,进行持续的数据传输、模型训练、效果验证、设备维护、设备维修的协同工作。
因为存在着大量的重复工作、实验工作、协调工作,所以可以复用的工作流,就尤其重要,要让
工作模块化的程度、可复用的程度、自动化的程度、包括可解释的程度
尽可能的高,否则一个问题就会把整个团队的工作卡住,而这样的问题又是一个接一个的。
05 数据智能的大同世界
问:
我们从数据智能项目的大环境讲到了和鲸的协同产品,最后一个问题是,那您认为数据科学协同产品的实质是什么?或者说和鲸最终的理念又是什么?
范向伟:
不知道你有没有发现,在聊天的过程中我们多次提到了数据科学、人工智能,这两者其实很接近,但定位不同。和这些年很多商学院会新建数据科学专业,计算机学院则是更多会建人工智能专业一样,它们一个关注经济效益,一个关注工程效率,这就关系到了数据科学协同产品的实质。
企业对于数据科学平台的期待,可能和大多数的人想的不一样。性能怎么样、速度怎么样、功能怎么样,当然都很重要,但数据科学的实质不是一个技术问题、业务问题,而是一个管理问题、经营问题:到底怎样借助数字化能力,帮助公司实现更好的生存。
领先的企业会把数据科学,当做一个杠杆、一个枢纽来看待,用数据科学的关联能力、预测能力,把整个企业的资产、流程、指标串联起来,构建起一个经营效率爬坡的良性循环,也就是“业务数据化”。这是一个很难实现的转变,但 TikTok 、Shein 、元气森林已经实现了各个行业中的打样,得到的效果是很惊人的。
所以在我们的设想中,数据科学协同产品最大的价值,就是变成一张网,
覆盖企业所有的数据资产、人才资产、需求场景,并把他们连接起来、运转起来,为人才赋予数字化的能力,为场景赋予智能化的效率,从而成为一个企业的数字化转型的枢纽
。这个枢纽的内核还是人才资产,而不是数据资产。这是 SaaS 产品的生命力的源头——SaaS 产品的价值,是改善人的处境,进而改善企业效率。
我们希望数据工程师、数据科学家,可以帮助业务人才建立起用数据的习惯和能力。数据部门要把数据的能力沉淀成可复用的、低代码、已落地的算法模板、模型仓库,业务人员是在不同的能力模板里面做实验和复用,把已经跑通的少数模型能力、模型资产,在更多的业务场景进行复制。
AI 的需求是无穷多的,预测的需求是无穷多的,但是AI的底层原理是相同的,业务的需求逻辑也是相似的,如果不开发业务人员的数据能力,大部分分析需求、预测需求,是来不及被满足的。
面对现在工程和技术进步的速度,大家都有比较强的焦虑,所以无论是工程师、数据科学家还是业务人员,都要用好时间、节约时间、快速成长。业务人才需要学会用数据,数据人才需要学会做管理。
下个阶段工程师所面对的新世界是不一样的。过去,工程师在做ETL 、建数据库、搭云平台、做模型,但是真正的机会其实是在
数据消费
。数据团队需要走出舒适圈,提高数据平台易用性,需要对接所有的数据需求场景、所有的数据需求人员,帮助他们用好数据,否则数据平台是没有未来的。
更强的数据计算平台+更多的业务用户+更多的需求场景,这三者如何结合,才是最大的机会所在。
我们希望,以数据科学协同能力为底座,每一个问题都能找到它所需要的数据,每一个模型都找到需要它的问题。
这就是我们理想中的,数据智能的大同世界。
和鲸科技旗下数据科学协同平台 ModelWhale 提供即开即用的云端分析环境,将数字资产管理、Notebook 交互式 & Canvas 拖拽式编程、建模分析、模型服务、任务及权限管理等功能深度整合,一体化解决企业大数据分析的多种协同问题,使数据驱动的决策更加便捷高效。
ModlWhale 同时支持 SaaS 云端使用及本地私有化部署,可满足不同组织需求。
欢迎进入
注册体验
,个人专业版及团队版内含更多高阶功能,首次注册即享 15 天免费试用,也可
扫码官网右侧二维码
(移动端可点击此超链)了解更多详情。
原网站版权声明
本文为[InfoQ]所创,转载请带上原文链接,感谢
https://xie.infoq.cn/article/15830dc76c6065923d66c559b

![[10 o'clock open class]: Optimization of AV1 encoder and its application in streaming media and real-time communication](/img/86/a6cd309cd66eb37159fcb8ae3338b1.png)