Password-Data-Analysis
If your password is on this list of 10,000 most common passwords, you need a new password. A hacker can use or generate files like this, which may readily be compiled from breaches. Usually, passwords are not tried one-by-one against a system's secure server online; instead, a hacker might manage to gain access to a shadowed password file protected by a one-way encryption algorithm, then test each entry in a file like this to see whether it encrypted form matches what the server has on record. The passwords may then be tried against any account online that can be linked to the first, to test for passwords reused on other sites.
From data we initially get this basic information-
-
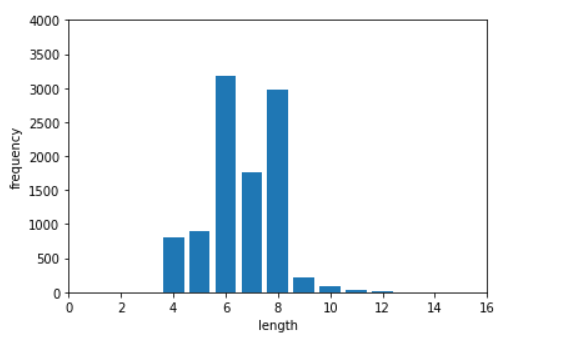
Mean length ~= 6.65
-
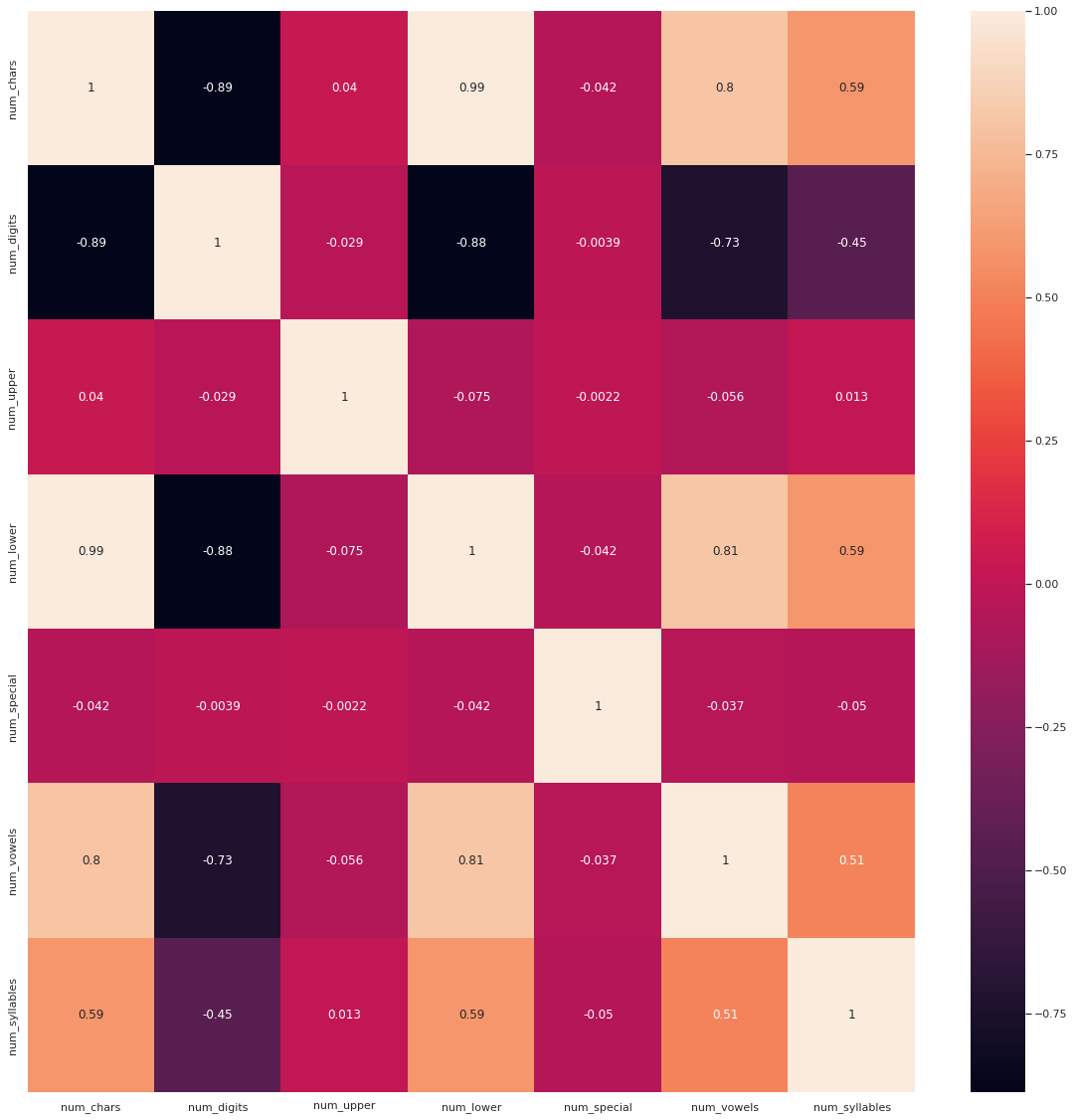
Mean num_chars ~= 5.03
-
Mean num_digits ~= 1.62
-
Mean num_upper ~= 0.03
-
Mean num_lower ~= 5.005
-
Mean num_special ~= 0.003
-
Mean num_vowels ~= 1.81
-
Mean num_syllables ~= 1.61
-
Minimum password length = 3
-
Maximum password length = 16
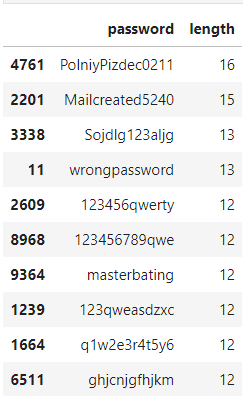
Top 10 shortest passwords-

Top 10 longest passwords-
Plotting password length data-
Co-relations between diffrent parameters-

 20 Dec 22, 2022
20 Dec 22, 2022
 2 Oct 01, 2021
2 Oct 01, 2021
 3 Aug 24, 2022
3 Aug 24, 2022
 2.1k Jan 05, 2023
2.1k Jan 05, 2023
 3 Aug 22, 2022
3 Aug 22, 2022
 687 Dec 25, 2022
687 Dec 25, 2022
 2.9k Jan 08, 2023
2.9k Jan 08, 2023
 36.4k Jan 03, 2023
36.4k Jan 03, 2023
 14 Aug 30, 2022
14 Aug 30, 2022
 2.2k Dec 25, 2022
2.2k Dec 25, 2022
 4 Jul 29, 2022
4 Jul 29, 2022
 1 Nov 25, 2021
1 Nov 25, 2021
 5 Apr 28, 2022
5 Apr 28, 2022
 14 Aug 19, 2022
14 Aug 19, 2022
 4 Jun 05, 2022
4 Jun 05, 2022
 1 Dec 16, 2021
1 Dec 16, 2021
 12 Dec 24, 2022
12 Dec 24, 2022
 4 Jul 10, 2022
4 Jul 10, 2022
 1 Nov 17, 2021
1 Nov 17, 2021
 3 Mar 03, 2022
3 Mar 03, 2022