JS-Secrets-Scraper
Python based Web Scraper which can discover javascript files and parse them for juicy information (API keys, IP's, Hidden Paths etc).
Screenshots
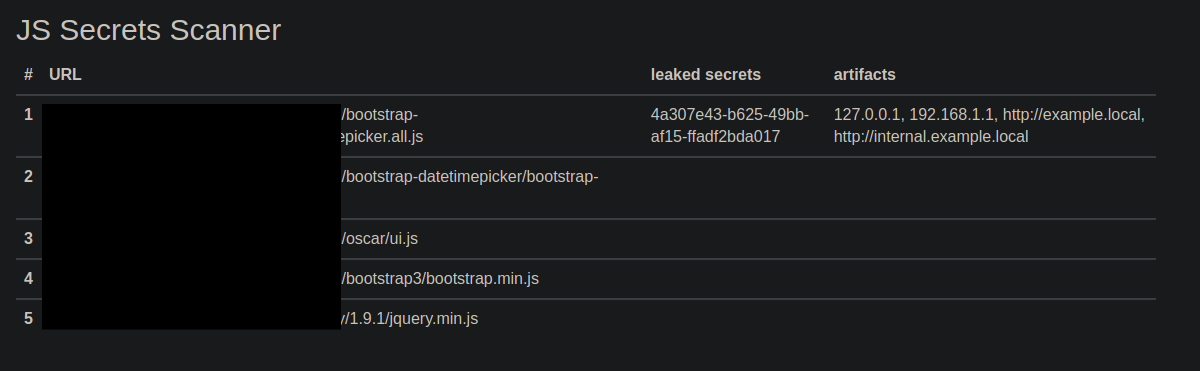
Technologies Used
- Flask
- Scrapy
Requirements
- Python 3
- Linux/Windows/MAC OSX
Installation
pip3 install -r requirements.txt
Usage
(+) usage: python3 ./web/main.py
Example
$ python3 ./web/main.py 2 ⨯
* Serving Flask app "main" (lazy loading)
* Environment: production
WARNING: This is a development server. Do not use it in a production deployment.
Use a production WSGI server instead.
* Debug mode: on
* Running on http://127.0.0.1:5000/ (Press CTRL+C to quit)
* Restarting with stat
* Debugger is active!
* Debugger PIN: XXX-XXX-XXX
Then, access the interface on http://127.0.0.1:5000/

 8 Aug 07, 2022
8 Aug 07, 2022
 0 Aug 18, 2021
0 Aug 18, 2021
 61 Jun 21, 2021
61 Jun 21, 2021
 22 Nov 21, 2022
22 Nov 21, 2022
 47 Nov 23, 2022
47 Nov 23, 2022
 2 Nov 26, 2021
2 Nov 26, 2021
 1 Oct 24, 2021
1 Oct 24, 2021
 1 Jul 04, 2022
1 Jul 04, 2022
 299 Dec 15, 2022
299 Dec 15, 2022
 90 Feb 09, 2021
90 Feb 09, 2021
 5 Apr 12, 2022
5 Apr 12, 2022
 1 Mar 18, 2022
1 Mar 18, 2022
 3 Feb 13, 2022
3 Feb 13, 2022
 2 Jul 20, 2022
2 Jul 20, 2022
 5 Nov 19, 2021
5 Nov 19, 2021
 0 Nov 07, 2022
0 Nov 07, 2022
 35 Aug 29, 2022
35 Aug 29, 2022
 10 Aug 18, 2022
10 Aug 18, 2022
 118 Dec 16, 2022
118 Dec 16, 2022
 30 Mar 01, 2022
30 Mar 01, 2022