Self-Training with Weak Supervision
This repo holds the code for our weak supervision framework, ASTRA, described in our NAACL 2021 paper: "Self-Training with Weak Supervision"
Overview of ASTRA
ASTRA is a weak supervision framework for training deep neural networks by automatically generating weakly-labeled data. Our framework can be used for tasks where it is expensive to manually collect large-scale labeled training data.
ASTRA leverages domain-specific rules, a large amount of unlabeled data, and a small amount of labeled data through a teacher-student architecture:
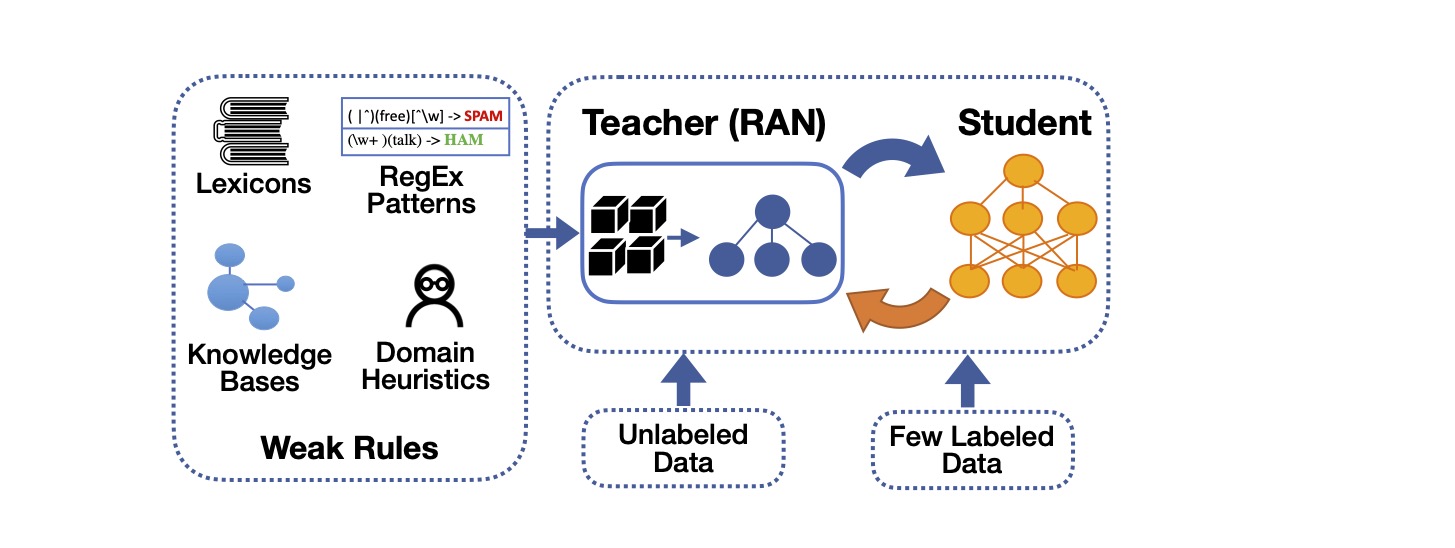
Main components:
- Weak Rules: domain-specific rules, expressed as Python labeling functions. Weak supervision usually considers multiple rules that rely on heuristics (e.g., regular expressions) for annotating text instances with weak labels.
- Student: a base model (e.g., a BERT-based classifier) that provides pseudo-labels as in standard self-training. In contrast to heuristic rules that cover a subset of the instances, the student can predict pseudo-labels for all instances.
- RAN Teacher: our Rule Attention Teacher Network that aggregates the predictions of multiple weak sources (rules and student) with instance-specific weights to compute a single pseudo-label for each instance.
The following table reports classification results over 6 benchmark datasets averaged over multiple runs.
| Method | TREC | SMS | YouTube | CENSUS | MIT-R | Spouse |
|---|---|---|---|---|---|---|
| Majority Voting | 60.9 | 48.4 | 82.2 | 80.1 | 40.9 | 44.2 |
| Snorkel | 65.3 | 94.7 | 93.5 | 79.1 | 75.6 | 49.2 |
| Classic Self-training | 71.1 | 95.1 | 92.5 | 78.6 | 72.3 | 51.4 |
| ASTRA | 80.3 | 95.3 | 95.3 | 83.1 | 76.1 | 62.3 |
Our NAACL'21 paper describes our ASTRA framework and more experimental results in detail.
Installation
First, create a conda environment running Python 3.6:
conda create --name astra python=3.6
conda activate astra
Then, install the required dependencies:
pip install -r requirements.txt
Download Data
We will soon add detailed instructions for downloading datasets and domain-specific rules as well as supporting custom datasets.
Running ASTRA
You can run ASTRA as:
cd astra
python main.py --dataset --student_name --teacher_name
Supported < STUDENT > models:
- logreg: Bag-of-words Logistic Regression classifier
- elmo: ELMO-based classifier
- bert: BERT-based classifier
Supported < TEACHER > models:
- ran: our Rule Attention Network (RAN)
We will soon add instructions for supporting custom student and teacher components.
Citation
@InProceedings{karamanolakis2021self-training,
author = {Karamanolakis, Giannis and Mukherjee, Subhabrata (Subho) and Zheng, Guoqing and Awadallah, Ahmed H.},
title = {Self-training with Weak Supervision},
booktitle = {NAACL 2021},
year = {2021},
month = {May},
publisher = {NAACL 2021},
url = {https://www.microsoft.com/en-us/research/publication/self-training-weak-supervision-astra/},
}
Contributing
This project welcomes contributions and suggestions. Most contributions require you to agree to a Contributor License Agreement (CLA) declaring that you have the right to, and actually do, grant us the rights to use your contribution. For details, visit https://cla.opensource.microsoft.com.
When you submit a pull request, a CLA bot will automatically determine whether you need to provide a CLA and decorate the PR appropriately (e.g., status check, comment). Simply follow the instructions provided by the bot. You will only need to do this once across all repos using our CLA.
This project has adopted the Microsoft Open Source Code of Conduct. For more information see the Code of Conduct FAQ or contact [email protected] with any additional questions or comments.
Trademarks
This project may contain trademarks or logos for projects, products, or services. Authorized use of Microsoft trademarks or logos is subject to and must follow Microsoft's Trademark & Brand Guidelines. Use of Microsoft trademarks or logos in modified versions of this project must not cause confusion or imply Microsoft sponsorship. Any use of third-party trademarks or logos are subject to those third-party's policies.

 28 Dec 09, 2022
28 Dec 09, 2022
 205 Jan 02, 2023
205 Jan 02, 2023
 4 Nov 07, 2022
4 Nov 07, 2022
 3 Dec 08, 2022
3 Dec 08, 2022
 31 Feb 26, 2022
31 Feb 26, 2022
 57 Nov 21, 2022
57 Nov 21, 2022
 842 Jan 04, 2023
842 Jan 04, 2023
 2 Nov 23, 2019
2 Nov 23, 2019
 58 Nov 30, 2022
58 Nov 30, 2022
 144 Dec 26, 2022
144 Dec 26, 2022
 91 Nov 10, 2022
91 Nov 10, 2022
 201 Nov 21, 2022
201 Nov 21, 2022
 2 Mar 19, 2022
2 Mar 19, 2022
 7 Dec 14, 2022
7 Dec 14, 2022
 99 Dec 23, 2022
99 Dec 23, 2022
 1 Jan 18, 2022
1 Jan 18, 2022
 1.7k Jan 03, 2023
1.7k Jan 03, 2023
 53 Dec 26, 2022
53 Dec 26, 2022
 9 Jun 06, 2022
9 Jun 06, 2022