AVOCADO HASS TIME SERIES VÀ PREDICT PRICE
Trước khi vào Heroku muốn giao diện đẹp mọi người chuyển giúp mình theo hình bên dưới 

https://avocado-hass.herokuapp.com/ deployed to Heroku
Please change setting to theme dark
Nếu trường muốn coi trên máy local host thì làm các bước sau:
Bước 1: Down code trên github về Bước 2: Vào trang streamlit để thực hiện theo hướng dẫn của treamlit: https://docs.streamlit.io/library/get-started/installation
I. TỔNG QUAN VỀ HỆ THỐNG DỮ LIỆU
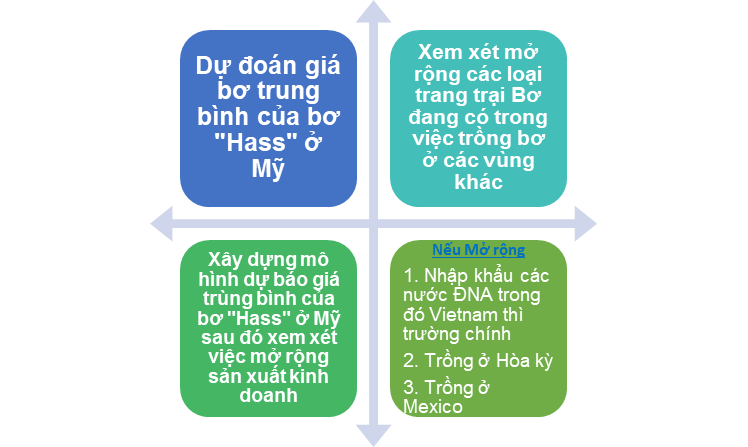
- Mục đích
- Dự đoán giá bơ trung bình của bơ "Hass" ở Mỹ
- Xem xét mở rộng các loại trang trại Bơ đang có trong việc trồng bơ ở các vùng khác
- Xây dựng mô hình dự báo giá trùng bình của bơ "Hass" ở Mỹ sau đó xem xét việc mở rộng sản xuất kinh doanh
- Vi sao có dự án nào ?
- Ai (Who): Doanh nghiệp là người cần
- Tại sao (Why): Giá bơ biến động ở các vùng khác nhau ? Có nên trồng bơ các vùng đó không ?
- Hiện tại
- Công ty kinh doanh quả bơ ở rất nhiều vùng của nước Mỹ có 2 loại bơ: Bơ thường và bơ hữu cơ
- Quy cách đóng gọi theo nhiều quy chuẩn: Small/ Large/ Xlarge Bags
- Có 3 loại item (product look up) khác nhau: 4046, 4225, 4770
- Vấn đề
- Doanh nghiệp chưa có mô hình dự báo giá bơ cho việc mở rộng
- Tối ưu sao việc tiếp cận giá bơ tới người tiêu dùng thấp nhất
- Thách thức và cách tiếp cận - Challenge and Approach
- Dữ liệu được lấy trực tiếp từ máy tính tính tiền của các nhà bán lẻ dựa trên doanh số bán lẻ thực tế của bơ Hass
- Dữ liệu đại diện cho dữ liệu lấy từ máy quét bán lẻ hàng tuần cho lượng bán lẻ (National retail volumn - units) và giá bơ từ tháng 4/2015 đến tháng 3/2018
- Giá Trung bình (Average Price) trong bảng phản ánh giá trên một đơn vị (mỗi quả bơ), ngay cả khi nhiều đơn vị (bơ) được bán trong bao
- Mã tra cứu sản phẩm - Product Lookup codes (PLU’s) trong bảng chỉ dành cho bơ Hass, không dành cho các sản phẩm khác.
- Data obtained - Thu thập dữ liệu
- Không thông quan nguồn cào data
- Toàn bộ dữ liệu được đổ ra và lưu trữ trong tập tin avocado.csv với 18249 record.
- Có 2 loại bơ trong tập dữ liệu và một số vùng khác nhau. Điều này cho phép chúng ta thực hiện tất cả các loại phân tích cho các vùng khác nhau hoặc phân tích toàn bộ nước mỹ theo một trong 2 loại bơ
- Đặt ra yêu cầu với bài toán
Yêu cầu 1: Với bài toán 1: thực hiện dự đoán giá bơ trung bình
- Thực hiện các tiền xử lý dữ liệu bổ sung (nếu cần)
- Ngoài những thuật toán regression đã được thực hiện, có thuật toán nào khác cho kết quả tốt hơn không? Thực hiện với thuật toán đó. Tổng hợp kết quả thu được."
Yêu cầu 2: Với bài toán 2: Thực hiện dự đoán giá, khả năng mở rộng trong tương lai với Organic Avocado ở vùng California
Yêu cầu 3: Hãy làm tiếp phần dự đoán giá bơ thường (Conventiton Avocado) của vùng California
Yêu cầu 4: Hãy chọn ra 1 vùng (Trong danh sách các vùng bơ "Hass" đang kinh doanh) mà bạn cho rằng trong tương lai có thể trong trọt, sản xuất kinh doanh (organic và/ hoặc Conventional Avocado). Hãy chứng minh đều này bằng cách triển khai các bài toán như đã với vùng california
II. TỔNG QUAN VỀ THỊ TRƯỜNG
- Thị trường Hoa Kỳ

- Mục tiêu và cấn tiếp cận
- Ai là người và cần gì ?

- Kết luận

III. HƯỚNG DẪN SỬ DỤNG VÀ CHỌN CÁC TÍNH NĂNG DỰ ĐOÁN GIÁ BƠ


 5.5k Jan 09, 2023
5.5k Jan 09, 2023
 1 Jan 31, 2022
1 Jan 31, 2022
 211 Dec 29, 2022
211 Dec 29, 2022
 2k Dec 28, 2022
2k Dec 28, 2022
 1.1k Jan 05, 2023
1.1k Jan 05, 2023
 29 Jan 09, 2023
29 Jan 09, 2023
 2 Aug 23, 2022
2 Aug 23, 2022
 1 Nov 01, 2021
1 Nov 01, 2021
 77 Jan 06, 2023
77 Jan 06, 2023
 182 Dec 31, 2022
182 Dec 31, 2022
 34 Jan 03, 2023
34 Jan 03, 2023
 2.5k Jan 07, 2023
2.5k Jan 07, 2023
 177 Sep 02, 2022
177 Sep 02, 2022
 1.4k Dec 28, 2022
1.4k Dec 28, 2022
 158 Jan 03, 2023
158 Jan 03, 2023
 76 Nov 25, 2022
76 Nov 25, 2022
 15 Aug 12, 2022
15 Aug 12, 2022
 19 Feb 13, 2022
19 Feb 13, 2022
 200 Dec 14, 2022
200 Dec 14, 2022
 4.1k Jan 09, 2023
4.1k Jan 09, 2023