Banpei

Banpei is a Python package of the anomaly detection.
Anomaly detection is a technique used to identify unusual patterns that do not conform to expected behavior.
System
Python ^3.6 (2.x is not supported)
Installation
$ pip install banpei
After installation, you can import banpei in Python.
$ python
>>> import banpei
Usage
Example
Singular spectrum transformation(sst)
import banpei
model = banpei.SST(w=50)
results = model.detect(data)
The input 'data' must be one-dimensional array-like object containing a sequence of values.
The output 'results' is Numpy array with the same size as input data.
The graph below shows the change-point scoring calculated by sst for the periodic data.

The data used is placed as '/tests/test_data/periodic_wave.csv'. You can read a CSV file using the following code.
import pandas as pd
raw_data = pd.read_csv('./tests/test_data/periodic_wave.csv')
data = raw_data['y']
SST processing can be accelerated using the Lanczos method which is one of Krylov subspace methods by specifying True for the is_lanczos argument like below.
results = model.detect(data, is_lanczos=True)
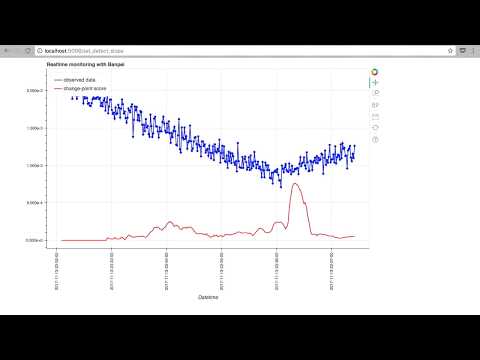
Real-time monitoring with Bokeh
Banpei is developed with the goal of constructing the environment of real-time abnormality monitoring. In order to achieve the goal, Banpei has the function corresponded to the streaming data. With the help of Bokeh, which is great visualization library, we can construct the simple monitoring tool.
Here's a simple demonstration movie of change-point detection of the data trends.
https://youtu.be/7_woubLAhXk
The sample code how to construct real-time monitoring environment is placed in '/demo' folder.
The implemented algorithm
Outlier detection
- Hotelling's theory
Change point detection
- Singular spectrum transformation(sst)
License
This project is licensed under the terms of the MIT license, see LICENSE.

 1 Nov 24, 2021
1 Nov 24, 2021
 438 Dec 17, 2022
438 Dec 17, 2022
 5 Aug 10, 2022
5 Aug 10, 2022
 1 Dec 30, 2021
1 Dec 30, 2021
 179 Dec 21, 2022
179 Dec 21, 2022
 1 Feb 10, 2022
1 Feb 10, 2022
 2.3k Dec 30, 2022
2.3k Dec 30, 2022
 868 Jan 05, 2023
868 Jan 05, 2023
 5 Apr 21, 2022
5 Apr 21, 2022
 517 Dec 31, 2022
517 Dec 31, 2022
 1.9k Jan 06, 2023
1.9k Jan 06, 2023
 1.3k Dec 26, 2022
1.3k Dec 26, 2022
 1 Sep 01, 2022
1 Sep 01, 2022
 3 Feb 08, 2022
3 Feb 08, 2022
 10 Dec 18, 2022
10 Dec 18, 2022
 13 Jul 02, 2022
13 Jul 02, 2022
 53 Jan 02, 2023
53 Jan 02, 2023
 511 Dec 20, 2022
511 Dec 20, 2022
 472 Dec 31, 2022
472 Dec 31, 2022
 204 Nov 18, 2022
204 Nov 18, 2022