当前位置:网站首页>3 Feature Binning Methods!
3 Feature Binning Methods!
2022-08-09 18:45:00 【Junhong's data analysis road】
一般在建立分类模型时,When we go on characteristics of the engineering work often need to deal with the discretization of continuous variables,Is the continuous field into discrete field.
In the process of discretization,A recap of the continuous variable coding.特征离散化后,模型会更稳定,降低了模型过拟合的风险.本文主要介绍3A common feature points method:

Points box features
Continuous variables discretization points of operation on,Can present more concise data information
Elimination of the influence of characteristic variable dimension,Because after points are category number,例如:0,1,2...
To a certain extent, reduce the influence of outliers,对异常数据有很强的鲁棒性
模拟数据
Simulation of a simple data and incomeINCOME相关
In [1]:
import pandas as pd
import numpy as npIn [2]:
df = pd.DataFrame({"ID":range(10),
"INCOME":[0,10,20,150,35,78,50,49,88,14]})
df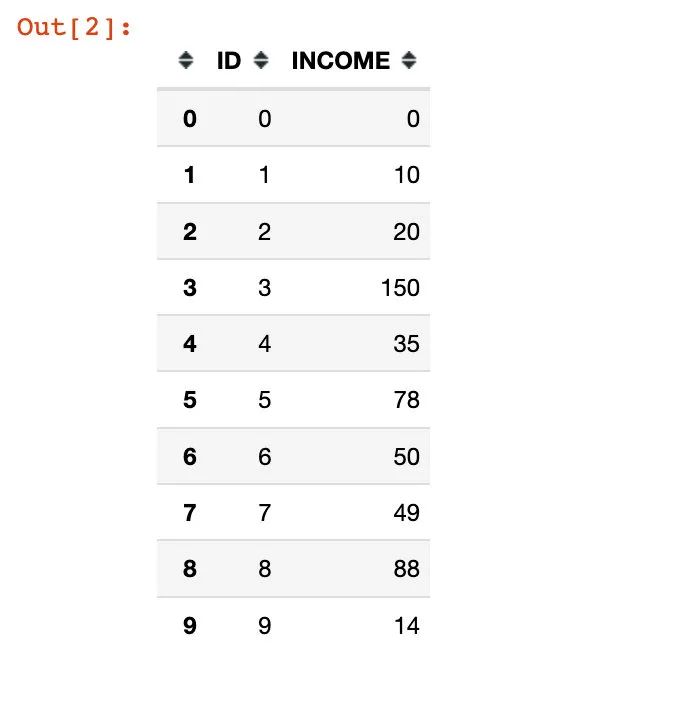
sklearn之KBinsDiscretizer类
本文中介绍的3Of operation are based onsklearn中的KBinsDiscretizer类,官网学习地址:
https://scikit-learn.org/stable/modules/generated/sklearn.preprocessing.KBinsDiscretizer.html
from sklearn.preprocessing import KBinsDiscretizer
sklearn.preprocessing.KBinsDiscretizer(n_bins=5,
encode='onehot',
strategy='quantile',
dtype=None,
subsample='warn',
random_state=None)全部参数解释:
All attribute information:

重点解释3个参数的使用:
n_bins
参数n_binsThe number of parameters specified on need points,默认是5个
strategy
To specify different points strategystrategy:KBinsDiscretizerClass implements the different points of the strategy,可以通过参数strategy进行选择:
等宽:
uniformStrategy with fixed widthbins;The width of the box body is consistent等频:
quantileStrategy used on each feature quantile(quantiles)Value in order to have the same fillingbins聚类:
kmeansStrategy based on independent execution on each featurek-meansClustering process definitionbins.
encode
encode参数表示分箱后Discrete field if you need further hot coding or other coding processing alone
KBinsDiscretizerClass can only identify column,需要将DataFrame的数据进行转化:
In [3]:
income = np.array(df["INCOME"].tolist()).reshape(-1,1)
incomeOut[3]:
array([[ 0],
[ 10],
[ 20],
[150],
[ 35],
[ 78],
[ 50],
[ 49],
[ 88],
[ 14]])Before using the guide in:
In [4]:
from sklearn.preprocessing import KBinsDiscretizer等宽分箱
So-called box is wide, such as, the data is divided into such as the width of a few,Such as analog data inINCOME的范围是0-150.Now its width divided into3份,So is the scope of each corresponding values:[0,50),[50,100)[100,150]
In [5]:
from sklearn.preprocessing import KBinsDiscretizer
dis = KBinsDiscretizer(n_bins=3,
encode="ordinal",
strategy="uniform"
)
disOut[5]:
KBinsDiscretizer(encode='ordinal', n_bins=3, strategy='uniform')In [6]:
label_uniform = dis.fit_transform(income) # 转换器
label_uniformOut[6]:
array([[0.],
[0.],
[0.],
[2.],
[0.],
[1.],
[1.],
[0.],
[1.],
[0.]])Width border check points:
In [7]:
dis.bin_edges_Out[7]:
array([array([ 0., 50., 100., 150.])], dtype=object)In [8]:
dis.n_binsOut[8]:
3等频分箱
Such as frequency division is the general term used to describe each band contains the value of number is the same,The difference between and width box:
等频分箱:每个区间内包括的值一样多,pd.qcut
等宽分箱:每两区间之间的距离是一样的,pd.cut
Before the implementation of frequency division box,我们需要先对数据进行升序排列,Then take the median points
In [9]:
# 1、先排序
sort_df = sorted(df["INCOME"])
sort_dfOut[9]:
[0, 10, 14, 20, 35, 49, 50, 78, 88, 150]分成2个类别
In [10]:
# 2、中间值:35和49的均值
(35 + 49) / 2Out[10]:
42.0下面我们以42As the basis of frequency division such as box:
In [11]:
dis = KBinsDiscretizer(n_bins=2,
encode="ordinal",
strategy="quantile"
)
dis.fit_transform(income) # 转换器Out[11]:
array([[0.],
[0.],
[0.],
[1.],
[0.],
[1.],
[1.],
[1.],
[1.],
[0.]])In [12]:
dis.bin_edges_Out[12]:
array([array([ 0., 42., 150.])], dtype=object)分成3个类别
总共是10个元素,分成3个类,10/3=3...1,前面两个3个元素,最后一个是4个元素,The last case contains the elements of the remainder part:
In [13]:
dis = KBinsDiscretizer(n_bins=3,
encode="ordinal",
strategy="quantile"
)
label_quantile = dis.fit_transform(income) # 转换器
label_quantileOut[13]:
array([[0.],
[0.],
[1.],
[2.],
[1.],
[2.],
[2.],
[1.],
[2.],
[0.]])In [14]:
dis.bin_edges_ # Points boundaryOut[14]:
array([array([ 0., 20., 50., 150.])], dtype=object)In [15]:
sort_df # 排序后的数据Out[15]:
[0, 10, 14, 20, 35, 49, 50, 78, 88, 150]聚类分箱
Clustering points box refers to the first type of continuous variable clustering,Then the sample classes as a logo to replace the original value.
In [16]:
from sklearn import clusterIn [17]:
kmeans = cluster.KMeans(n_clusters=3)
kmeans.fit(income)Out[17]:
KMeans(n_clusters=3)Clustering is completed for each sample belongs to category:
In [18]:
kmeans.labels_Out[18]:
array([1, 1, 1, 2, 1, 0, 0, 0, 0, 1], dtype=int32)使用KBinsDiscretizerTo implement clustering points:
In [19]:
dis = KBinsDiscretizer(n_bins=3,
encode="ordinal",
strategy="kmeans"
)
label_kmeans = dis.fit_transform(income) # 转换器
label_kmeansOut[19]:
array([[0.],
[0.],
[0.],
[2.],
[0.],
[1.],
[0.],
[0.],
[1.],
[0.]])In [20]:
dis.bin_edges_ # Points boundaryOut[20]:
array([array([ 0. , 54.21428571, 116.5 , 150. ])],
dtype=object)3种方法对比
In [21]:
df["label_uniform"] = label_uniform
df["label_quantile"] = label_quantile
df["label_kmeans"] = label_kmeans
df
参考
特征离散化(分箱)综述:https://zhuanlan.zhihu.com/p/68865422
书籍《特征工程入门与实践》
sklearn官网
边栏推荐
猜你喜欢

网络——局域网和广域网

日志定期压缩、清除
安装MySQL的最后一步第四个红叉怎么解决
B44 - Based on stm32 bluetooth intelligent voice recognition classification broadcast trash

Smart Light Pole Gateway Smart Transportation Application

B43 - 基于STM32单片机的自动视力检测仪
2022年8月9日:用C#生成.NET应用程序--使用 Visual Studio Code 调试器,以交互方式调试 .NET 应用(不会,失败)

网络——数字数据编码

测试/开发程序员喜欢跳槽?跳了就能涨工资吗?

央企施工企业数字化转型的灵魂是什么
随机推荐
After the WeChat developer tool program is developed, no error is reported, but the black screen "recommended collection"
领先实践|全球最大红酒App如何用设计冲刺创新vivino模式
苹果开发者账号 申请 D-U-N-S 编号
HR to get the entry date RP_GET_HIRE_DATE
打印星型图「建议收藏」
无需支付688苹果开发者账号,xcode13打包导出ipa,提供他人进行内测
ECCV 2022 | BMD: 面向无源领域自适应的类平衡多中心动态原型策略
想通这点,治好 AI 打工人的精神内耗
HR获取入职日期 RP_GET_HIRE_DATE
B50 - 基于51单片机的儿童成长管理系统
2022年中国第三方证券APP创新专题分析
yolov5训练并生成rknn模型以及3588平台部署
Redis Cache Expiration and Retirement Policy
No need to pay for the 688 Apple developer account, xcode13 packaged and exported ipa, and provided others for internal testing
聊聊基于docker部署的mysql如何进行数据恢复
【1413. 逐步求和得到正数的最小值】
pgsql备份工具,哪个比较好?
网络——IPV4地址(三)
反转链表的多种写法(武器库了属于是)
Insert a number and sort "Suggested Favorites"