当前位置:网站首页>[point cloud series] unsupervised multi task feature learning on point clouds
[point cloud series] unsupervised multi task feature learning on point clouds
2022-04-23 13:18:00 【^_^ Min Fei】
1. Summary
subject :Unsupervised Multi-Task Feature Learning on Point Clouds
The paper :https://openaccess.thecvf.com/content_ICCV_2019/papers/Hassani_Unsupervised_Multi-Task_Feature_Learning_on_Point_Clouds_ICCV_2019_paper.pdf
2. motivation
Traditional manual design features mainly capture local or global statistical attributes , Unable to represent semantic properties .
Is there a common feature for tasks that require semantic features ?
So this article This paper puts forward a method which can be used for unsupervised multitasking Feature expression of the model , Encoder based on multiscale graph . End to end training .
3. Algorithm
For three unsupervised learning tasks :
- clustering
- restructure
- Self supervised classification
The overall framework :
decoder : Multi scale ( Graph convolution + Convolution + Pooling )+ Perturbed Gaussian noise
Essentially applicable to multitasking , It's also because we used the loss of these tasks to train together , Naturally, with this function .
Definition of volume of drawing : It's actually the residual between two points ;

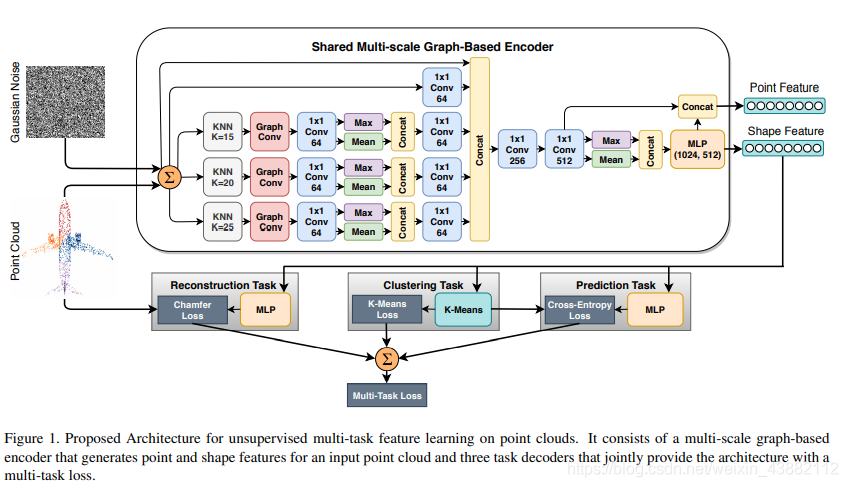
Algorithm description :
Training set : S = { s 1 , s 2 , . . . , s N } S=\{s_1, s_2, ..., s_N\} S={
s1,s2,...,sN},N A little bit .
One point : s i = { p 1 i , p 2 i , . . , p M 1 } s_i =\{ p^i_1, p^i_2, .., p^1_M\} si={
p1i,p2i,..,pM1}, M A disordered point , p j i = ( x j i , y j i , z j i ) p^i_j=(x^i_j, y^i_j, z^i_j) pji=(xji,yji,zji) Include coordinates only
Encoder : E θ : S ( R M × d i n ) → Z ( R d z ) E_{\theta}: S (\mathbb{R}^{M\times d_{in}})\rightarrow Z (\mathbb{R}^{d_z}) Eθ:S(RM×din)→Z(Rdz), d z d_z dz Far greater than d i n d_in din
In order to learn more tasks than supervision θ \theta θ, Design the following three parameter functions :
Clustering function T c : Z → y \Tau_c:Z \rightarrow y Tc:Z→y, Classify hidden codes into K K K Of the three categories , among y = [ y 1 , y 2 , . . . , y n ] y=[y_1, y_2, ...,y_n] y=[y1,y2,...,yn], y i ∈ { 0 , 1 } K y_i\in\{0,1\}^K yi∈{
0,1}K, And y n T 1 k = 1 y^T_n \mathbf{1}_k=1 ynT1k=1.
Classification function f ψ : Z → y ^ f_\psi: Z \rightarrow \hat{y} fψ:Z→y^, Category prediction after clustering , In other words , The classification function maps implicit variables to K A prediction class y ^ = [ y 1 ^ , y 2 ^ , . . . , y n ^ ] \hat{y}=[\hat{y_1}, \hat{y_2}, ...,\hat{y_n}] y^=[y1^,y2^,...,yn^], And y i ^ ∈ { 0 , 1 } K \hat{y_i}\in\{0,1\}^K yi^∈{
0,1}K. The function uses the pseudo tag generated by the clustering function as the agent training data .
Decoder function : g ϕ : Z ( R d z ) → S ^ ( R M × d i n ) g_\phi: Z(\mathbb{R}^{d_z}) \rightarrow \hat{S} (\mathbb{R}^{M\times d_{in}}) gϕ:Z(Rdz)→S^(RM×din), Reconstruct the implicit variable back to the point cloud . If only clustering loss is used, the features will be clustered into a single class , The function is designed to prevent the final aggregation into a single class .
Loss of training :
-
Clustering loss : In essence, it is learning the clustering center matrix : C ∈ R d z × K C\in \mathbb{R}^{d_z \times K} C∈Rdz×K, z n = E θ ( s n ) z_n=E_\theta(sn) zn=Eθ(sn), y n T 1 k = 1 y^T_n\mathbf{1}_k=1 ynT1k=1. among , initialization The random clustering matrix is the center , yes epoch The updated .

-
Classified loss : Cross entropy measures , y n = T c ( z n ) y_n=\Tau_c(z_n) yn=Tc(zn), y ^ n = f ψ ( z n ) \hat{y}_n=f_\psi(z_n) y^n=fψ(zn).

-
Refactoring loss :CD distance . s ^ n = g ϕ ( z n ) \hat{s}_n=g_\phi (z_n) s^n=gϕ(zn) Is the reconstructed point set , s n s_n sn yes GT. N N N: Number of training sets ; M M M: The number of points in each point set .

The ultimate loss : above 3 Weighted summation of losses

The specific description process is shown in the following figure 1 Shown :

4. experiment
Model convergence :88 Classes , actual 55 Category .
The Clustering Visualization diagram is as follows :

On classified tasks , Comparison of unsupervised and supervised methods : It works well in unsupervised methods ;

The effect of semi supervised segmentation task : 5% The effect of the training set is still very good ;

Split task effect :

Encoder The role of , Test on classification tasks : In fact, it seems to be saying here , complex Encoder The improvement after refactoring is not particularly great , The improvement of multi class tasks is very big .

Ablation Experiment : Refactoring is the key , Plus the effect of classification > The effect of clustering , Because clustering here is actually for further classification , Realize the so-called unsupervised .

5. Conclusion and thinking
Failure case list :
- apply K-Means To initialize the cluster center , But there is no improvement in the random clustering center method ;
- stay decoder And classification model soft Shared parameter mechanism , It is found that the effect is reduced , So separate the two ;
- Try to iterate over more layers , Recalculate the nearest neighbor at each layer , It is found that this is disadvantageous to classification and segmentation ;
版权声明
本文为[^_^ Min Fei]所创,转载请带上原文链接,感谢
https://yzsam.com/2022/04/202204230611136498.html
边栏推荐
- Super 40W bonus pool waiting for you to fight! The second "Changsha bank Cup" Tencent yunqi innovation competition is hot!
- 5道刁钻的Activity生命周期面试题,学完去吊打面试官!
- STD:: shared of smart pointer_ ptr、std::unique_ ptr
- 100 GIS practical application cases (51) - a method for calculating the hourly spatial average of NC files according to the specified range in ArcGIS
- Design and manufacture of 51 single chip microcomputer solar charging treasure with low voltage alarm (complete code data)
- 9419页最新一线互联网Android面试题解析大全
- “湘见”技术沙龙 | 程序员&CSDN的进阶之路
- X509 parsing
- filter()遍历Array异常友好
- The project file '' has been renamed or is no longer in the solution, and the source control provider associated with the solution could not be found - two engineering problems
猜你喜欢

你和42W奖金池,就差一次“长沙银行杯”腾讯云启创新大赛!

2020年最新字节跳动Android开发者常见面试题及详细解析

Example interview | sun Guanghao: College Club grows and starts a business with me

Vscode tips

Solve the problem of Oracle Chinese garbled code

十万大学生都已成为猿粉,你还在等什么?

Solve the problem that Oracle needs to set IP every time in the virtual machine
Common interview questions and detailed analysis of the latest Android developers in 2020
![[quick platoon] 215 The kth largest element in the array](/img/14/8cd1c88a7c664738d67dcaca94985d.png)
[quick platoon] 215 The kth largest element in the array
解决Oracle中文乱码的问题
随机推荐
基于uniapp异步封装接口请求简介
The difference between string and character array in C language
2020年最新字节跳动Android开发者常见面试题及详细解析
Filter and listener of three web components
MySQL5.5安装教程
uniapp image 引入本地图片不显示
「玩转Lighthouse」轻量应用服务器自建DNS解析服务器
Riscv MMU overview
叮~ 你的奖学金已到账!C认证企业奖学金名单出炉
PyTorch 21. NN in pytorch Embedding module
Translation of multi modal visual tracking: review and empirical comparison
Complete project data of UAV apriltag dynamic tracking landing based on openmv (LabVIEW + openmv + apriltag + punctual atom four axes)
5道刁钻的Activity生命周期面试题,学完去吊打面试官!
100 GIS practical application cases (34) - splicing 2020globeland30
Scons build embedded ARM compiler
Machine learning -- PCA and LDA
Use Proteus to simulate STM32 ultrasonic srf04 ranging! Code+Proteus
SPI NAND flash summary
EMMC / SD learning notes
51 single chip microcomputer stepping motor control system based on LabVIEW upper computer (upper computer code + lower computer source code + ad schematic + 51 complete development environment)