当前位置:网站首页>[Semantic Segmentation] DeepLab Series
[Semantic Segmentation] DeepLab Series
2022-08-10 14:54:00 【Coke Daniel】
DeepLab V1
概述
我们之前有提到FCNConvert the fully connected operation of the classification network into a convolution operation,An end-to-end segmentation network is obtained,Then think about how to improve the effect of this network.There are two ideas in the text,One is to increase the size of the final output feature map,Then the result after upsampling will be better;另一种就是使用skip-connection操作,Upsampling slowly,and add features.
DeepLab v1It is a further thought on the basis of the first idea,By modifying the backbone network(Reduce pooling times and add atrous convolutions),在保证感受野的同时,Increase the size of the output feature map,And use fully connectedCRFFine-tune the final output,得到更好的效果.
细节
网络结构
骨干网络是VGG,But with some modifications,包括:
1、将全连接层转换为卷积层(FCN的思想),
2、The stride of the last two pooling layers becomes 1(The size does not change before and after pooling,So the final output size is the original image1/8,而不是1/32了),
3、第5个stage的卷积层和fc1的卷积层,into atrous convolution(As for parameter settings,is to guarantee andVGGThe receptive field of the network is the same.)
注:The second modification is to make the final output size a bit larger,The third modification is to solve the problem that the second modification makes it impossible to use the pre-trained model.It makes the receptive field of the modified network the same as the original network,The pretrained parameters can then be used,Just set the extra parameter to 0就可以了.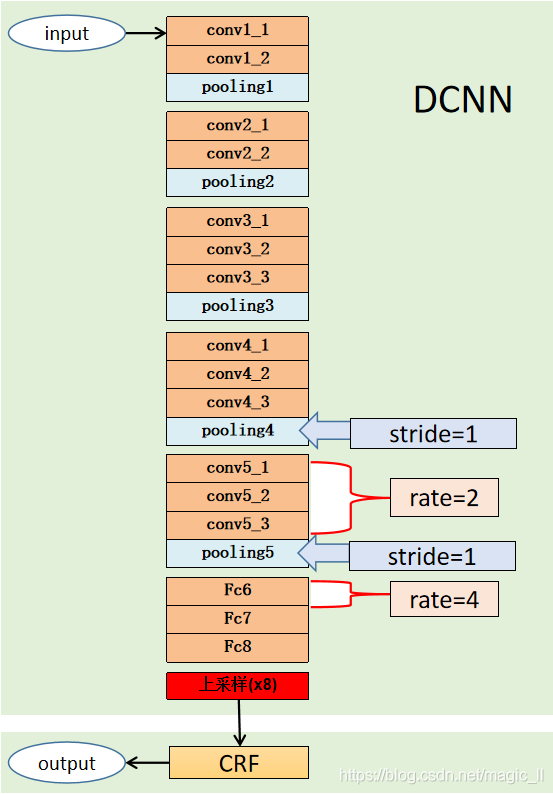
图片来自:链接
空洞卷积
是什么:It is to inject holes in the standard convolution,从而增大感受野.Basic deep learning frameworks now support this type of convolution,Compared with standard convolution, there is an additional parameter of dilation rate,Indicates the number of intervals.The actual kernel size of atrous convolution is
K = K + ( k − 1 ) ( a − 1 ) K = K + (k-1)(a-1) K=K+(k−1)(a−1),
其中 K K K是卷积核的大小, a a a是空洞率.例如,A void ratio is 2的3*3卷积,相当于一个5*5卷积.The standard convolution is equivalent to the hole convolutiona取为1的特例.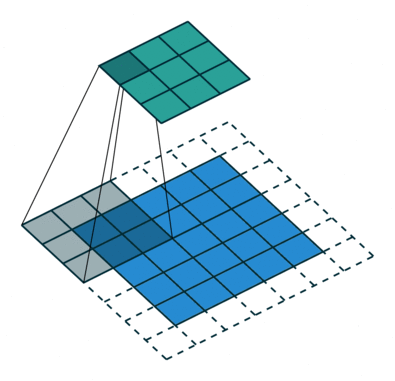
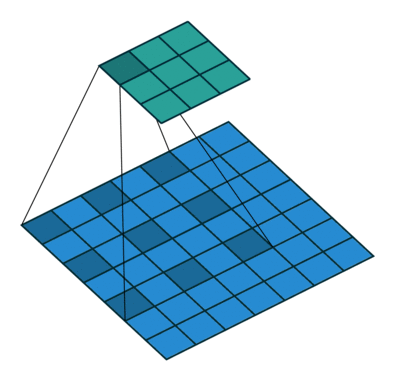
有什么用:
1、扩大感受野.The downsampling operation can be replaced by atrous convolution(步长为2的卷积或者池化),And can not reduce the resolution or reduce the resolution less,另一方面,Atrous convolution is relative to standard convolution,没有引入额外的参数.
2、Obtain multi-scale contextual information.不同的空洞率,Bring different feeling fields,There are also different contextual information,This information is either in series or in parallel,都是很优秀的.
缺陷:May bring grid effect.If only in series,Not all pixels in the image are used for computation,Some local information is lost,And the information obtained is discrete,不是连续的;另一方面,The segmentation of small objects does not actually bring much benefit,Instead, there will be disadvantages.因此,The authors are just the last two on the webstage,Cancel the downsampling operation,之后采用空洞卷积弥补丢失的感受野.
全连接CRF
CRF(概率图模型,线性条件随机场)The application in traditional image processing is smoothing.CRF在决定一个位置的像素值时,The values of surrounding pixels are considered.但是通过CNNThe resulting probability map is smooth enough to a certain extent,So short rangeCRF没有太大的意义.So consider using fully connectedCRF,This will comprehensively consider global information,Restore detailed local structure,Like the outline of a precise figure.CRFIt can be used to improve image accuracy in almost all segmentation tasks.
CRFis a post-processing stage,It is equivalent to an optimization process for the segmentation map.
多尺度预测
previous studies have shown,Multi-scale prediction can get better results,This article has also tried.注:Multi-scale prediction is actually sumskip-connetion操作类似
具体方式就是,before entering the picture and4个 maxpooliing后添加 MLP层(多层感知机,第一层是 3x3x33x128卷积,第二层是 1x1x11x128 卷积),得到预测结果,Then combine this result with the output of the last layerconcat起来,得到最终的结果.This operation is also improved,But not fully connectedCRF带来的提升更多.
DeepLab V2
概述
v2在v1的基础上加入了ASPP,And put the backbone network fromVGG-16换成了ResNet-101,At the same time added some trainingtirck.
细节
ASPP
This paper proposes an atrous spatial convolutional pooling pyramidAtrous spatial pyramid pooling (ASPP),Detection is done by parallelizing multiple atrous convolutional layers with different sampling rates,以多个比例捕捉对象以及图像上下文.
First, atrous convolution is equivalent to a convolution with a larger convolution kernel,then setpadding之后,No matter how much void ratio,All feature maps of the same size can be obtained,Finally, these feature maps are fused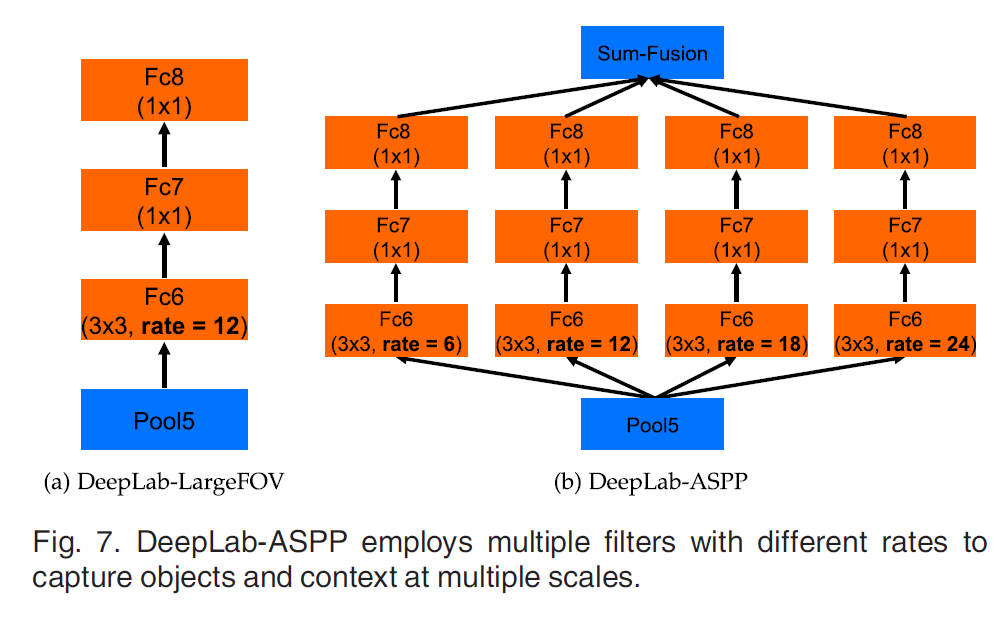
边栏推荐
- 快速了解大端模式和小端模式
- PyTorch 多机多卡训练:DDP 实战与技巧
- Flask框架——基于Celery的后台任务
- 作业
- 第五讲 测试技术与用例设计
- 等保2.0一个中心三重防护指的是什么?如何理解?
- 系统架构系列文章三--解决传统企业核心系统的性能问题
- High-paid programmers & interview questions series 135 How do you understand distributed?Do you know CAP theory?
- 2022-08-10 Daily: Swin Transformer author Cao Yue joins Zhiyuan to carry out research on basic vision models
- How does IT Xiaobai learn PHP systematically
猜你喜欢

Understanding_Data_Types_in_Go
BCG库简介
奢侈品鉴定机构小程序开发制作功能介绍

这一次,话筒给你:向自由软件之父斯托曼 提问啦!
Send a post request at the front desk can't get the data

Analysys and the Alliance of Small and Medium Banks jointly released the Hainan Digital Economy Index, so stay tuned!
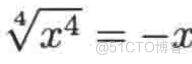
普林斯顿微积分读本05第四章--求解多项式的极限问题
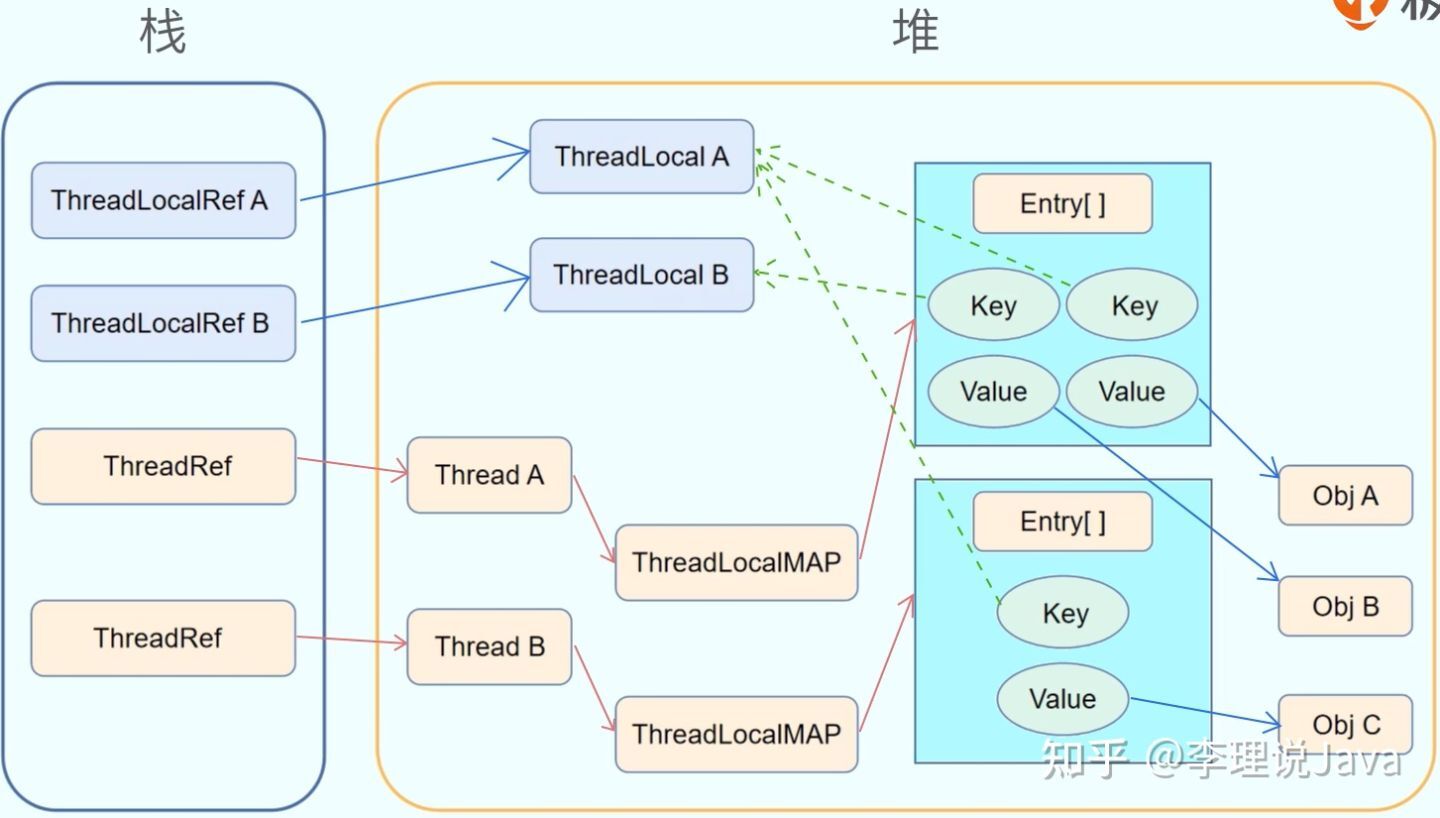
1W word detailed thread local storage ThreadLocal

阿里五位MySQL封神大佬耗17个月总结出53章性能优化法则
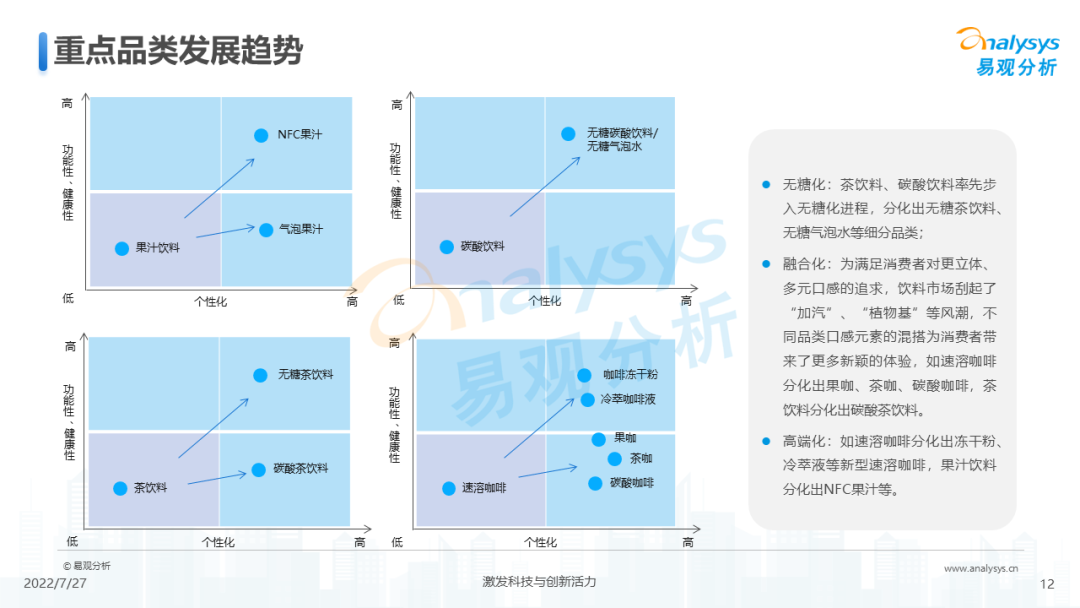
2022年中国软饮料市场洞察
随机推荐
静态变量存储在哪个区
Error: Rule can only have one resource source (provided resource and test + include + exclude)
领域驱动模型设计与微服务架构落地-从项目去剖析领域驱动
JS入门到精通完整版
640. 求解方程 : 简单模拟题
leetcode 739. Daily Temperatures Daily Temperatures (Moderate)
antd组件中a-modal设置固定高度,内容滚动显示
作业
DB2查询2个时间段之间的所有月份,DB2查询2个时间段之间的所有日期
强意识 压责任 安全培训筑牢生产屏障
网络初识(二)
“国资云”和“国家云”能给市场带来怎样的变革?
缺少比较器,运放来救场!(运放当做比较器电路记录)
这一次,话筒给你:向自由软件之父斯托曼 提问啦!
无线网络、HTTP缓存、IPv6
How to code like a pro in 2022 and avoid If-Else
富爸爸穷爸爸之读书笔记
Data product manager thing 2
司空见惯 - 股市狠狠下跌后,何時能反弹?
【MinIO】Using tools