当前位置:网站首页>正则表达式(包含各种括号,echo,正则三剑客以及各种正则工具)
正则表达式(包含各种括号,echo,正则三剑客以及各种正则工具)
2022-08-10 13:50:00 【不懂计算机的小白】
目录
单括号,双括号,中括号,双中括号,大括号
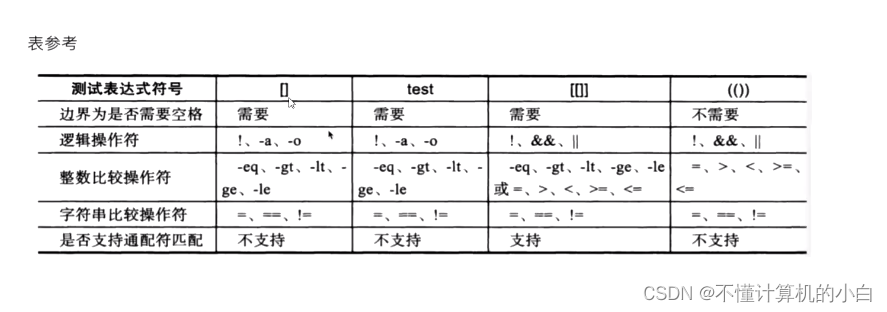
单括号:
1.命令组。括号中的命令将会新开一个子shell顺序执行,所以括号中的变量不能够被脚本余下的部分使用。括号中多个命令之间用分号隔开,最后一个命令可以没有分号,各命令和括号之间不必有空格。
2.命令替换。等同于cmd,shell扫描一遍命令行,发现了( c m d ) 结 构 , 便 将 (cmd)结构,便将(cmd)结构,便将(cmd)中的cmd执行一次,得到其标准输出,再将此输出放到原来命令。有些shell不支持,如tcsh。
3.用于初始化数组。如:array=(a b c d)
双小括号:
1.整数扩展。这种扩展计算是整数型的计算,不支持浮点型。((exp))结构扩展并计算一个算术表达式的值,如果表达式的结果为0,那么返回的退出状态码为1,或者 是"假",而一个非零值的表达式所返回的退出状态码将为0,或者是"true"。若是逻辑判断,表达式exp为真则为1,假则为0。
2.只要括号中的运算符、表达式符合C语言运算规则,都可用在$((exp))中,甚至是三目运算符。作不同进位(如二进制、八进制、十六进制)运算时,输出结果全都自动转化成了十进制。如:echo $((16#5f)) 结果为95 (16进位转十进制)
3.单纯用 (( )) 也可重定义变量值,比如 a=5; ((a++)) 可将 $a 重定义为6
4.常用于算术运算比较,双括号中的变量可以不使用$符号前缀。括号内支持多个表达式用逗号分开。 只要括号中的表达式符合C语言运算规则,比如可以直接使用for((i=0;i<5;i++)), 如果不使用双括号, 则为for i inseq 0 4或者for i in {0..4}。再如可以直接使用if (($i<5)), 如果不使用双括号, 则为if [ $i -lt 5 ]。
((expr ))通常作为运算的
中括号:
1.bash 的内部命令,[和test是等同的。如果我们不用绝对路径指明,通常我们用的都是bash自带的命令。if/test结构中的左中括号是调用test的命令标识,右中括号是关闭条件判断的。这个命令把它的参数作为比较表达式或者作为文件测试,并且根据比较的结果来返回一个退出状态码。if/test结构中并不是必须右中括号,但是新版的Bash中要求必须这样。
2.Test和[]中可用的比较运算符只有=和!=,两者都是用于字符串比较的,不可用于整数比较,整数比较只能使用-eq,-gt这种形式。无论是字符串比较还是整数比较都不支持大于号小于号。如果实在想用,对于字符串比较可以使用转义形式,如果比较"ab"和"bc":[ ab \< bc ],结果为真,也就是返回状态为0。[ ]中的逻辑与和逻辑或使用-a 和-o 表示。且[]前后都有空格。
3.字符范围。用作正则表达式的一部分,描述一个匹配的字符范围。作为test用途的中括号内不能使用正则。
4.在一个array 结构的上下文中,中括号用来引用数组中每个元素的编号。
双中括号:
1.[[是 bash 程序语言的关键字。并不是一个命令,[[ ]] 结构比[ ]结构更加通用。在[[和]]之间所有的字符都不会发生文件名扩展或者单词分割,但是会发生参数扩展和命令替换。
2.支持字符串的模式匹配,使用=~操作符时甚至支持shell的正则表达式。字符串比较时可以把右边的作为一个模式,而不仅仅是一个字符串,比如[[ hello == hell? ]],结果为真。[[ ]] 中匹配字符串或通配符,不需要引号。
3.使用[[ … ]]条件判断结构,而不是[ … ],能够防止脚本中的许多逻辑错误。比如,&&、||、<和> 操作符能够正常存在于[[ ]]条件判断结构中,但是如果出现在[ ]结构中的话,会报错。比如可以直接使用if [[ $a != 1 && $a != 2 ]], 如果不适用双括号, 则为if [ $a -ne 1] && [ $a != 2 ]或者if [ $a -ne 1 -a $a != 2 ]。
4.bash把双中括号中的表达式看作一个单独的元素,并返回一个退出状态码。
大括号:
1.大括号拓展。(通配(globbing))将对大括号中的文件名做扩展。在大括号中,不允许有空白,除非这个空白被引用或转义。第一种:对大括号中的以逗号分割的文件列表进行拓展。如 touch {a,b}.txt 结果为a.txt b.txt。第二种:对大括号中以点点(…)分割的顺序文件列表起拓展作用,如:touch {a…d}.txt 结果为a.txt b.txt c.txt d.txt
2.代码块,又被称为内部组,这个结构事实上创建了一个匿名函数 。与小括号中的命令不同,大括号内的命令不会新开一个子shell运行,即脚本余下部分仍可使用括号内变量。括号内的命令间用分号隔开,最后一个也必须有分号。{}的第一个命令和左括号之间必须要有一个空格。{}也可以用于多行注释,作为函数包起来只是不调用即可。
[ a /< b ]实际上比的是ascll码的值,其中a,b表示的并不是变量,如果需要比较变量则需要在前面增加$符号。
Echo的用法
Echo -n表示不换行输出
Echo -e表示输出转移字符,将转义后的内容输出到屏幕上
常用的转义字符如下:
\b:转义后相当于按退格键(backspace),但前提是"\b"后面存在字符;"\b"表示删除前一一个字符,"\b\b”表示删除前两个字符。

\c:不换行输出,在"\c"后面不存在字符的情况下,作用相当于echo -n;但是当"\c"后面仍然存在字符时,"\c"后面的字符将不会被输出。


\n:换行,被输出的字符从"\n"处开始另起一行。
\f换行,但是换行后的新行的开头位置连接着上一行的行尾;
\v '与\f相同;
\t转以后表示插入tab,即横向制表符;
\r光标移至行首,但不换行,相当于使用"\r"以后的字符覆盖"\r"之前同等长度的字符:但是当"\r"后面不存在任何字符时,"\r"前面的字符不会被覆盖
\\表示插入"\"本身;
正则表达式定义:
正则表达式,又称正规表达式、常规表达式,使用字符串来描述、匹配一系列符合某个规则的字符串。
正则表达式组成
普通字符:
大小写字母、数字、标点符号及一些其他符号
元字符:
在正则表达式中具有特殊意义的专用字符
元字符
\:转义字符,\!、\n等
^:匹配字符串开始的位置
例: ^a、^the、^#
$:匹配字符串结束的位置
例: word$
.:匹配除\n之外的任意的一个字符
例: go.d、g..d
*:匹配前面子表达式0次或者多次
例:goo*d、go.*d
[list]:匹配list列表中的一个字符
例: go[ola]d,[abc]、[a-z]、[a-z0-9]
[^list]:匹配任意不在list列表中的一个字符
例: [^a-z]、[^0-9]、[^A-Z0-9]
\{n,m\}:匹配前面的子表达式n到m次,有\{n\}、\{n,\}、\{n,m\}三种格式
例:go\{2\}d、go\{2,3\}d、go\{2,\}d
扩展元字符
+:匹配前面子表达式1次以上
例: go+d,将匹配至少一个o
?:匹配前面子表达式0次或者1次
例: go?d,将匹配gd或god
():将括号中的字符串作为一个整体
例:(xyz)+,将匹配 xyz 整体1次以上,如xyzxyz
|:以或的方式匹配字条串
例1: good|food,将匹配good或者food
例2: g(oo|la)d,将匹配good或者glad
使用grep匹配正则
Grep 【选项】 查找条件 目标文件
-w:表示精确匹配
-E :开启扩展(Extend)的正则表达式
-c : 计算找到'搜寻字符串'的次数
-i :忽略大小写的不同,所以大小写视为相同
-o :只显示被模式匹配到的宁符串
-v:反向选择,亦即显示出没有'搜寻字符串′内容的那一行! (反向查找,输出与查找条件不相符的行)--color=auto : 可以将找到的关键词部分加上颜色的显示喔!
-n :顺便输出行号
基础正则表达式常见元字符
\:转义符,将特殊字符进行转义,忽略其特殊意义a\.b匹配a.b,但不能匹配ajb,.被转义为特殊意义\\\
^:匹配行首,^则是匹配字符串的开始^tux匹配以tux开头的行^^^^
$:匹配行尾,$则是匹配字符串的结尾tux$匹配以tux结尾的行$$$$
.:匹配除了换行符 \r\n之外的任意单个字符
[list]:匹配list列表中的一个字符
例: go[ola]d,[abc]、[a-z]、[a-z0-9]
[^list]:匹配任意不在list列表中的一个字符
例: [^a-z]、[^0-9]、[^A-Z0-9]
\{n,m\}:匹配前面的子表达式n到m次,有\{n\}、\{n,\}、\{n,m\}三种格式
例:go\{2\}d、go\{2,3\}d、go\{2,\}d
示例:
- 查找特定字符
例如在test.txt文件中,多写了一个the,我想单独把the找出来,其中grep中-n表示显示行号,-i是区分大小写

- 使用-i命令表示不区分大小写

- 使用-v命令查找不包含“the”字符的行,并且配合-n一起使用显示行号

这里我将所有字符全部写在了一行,所以过滤的时候会将整行过滤。
- 利用中括号“【】”来查找集合字符
想要查找“shirt”与“short”这两个字符串时,可以发现这两个字符串均包含“sh”与“rt”。此 时执行以下命令即可同时查找到“shirt”与“short”这两个字符串,其中“[]”中无论有几个字符, 都仅代表一个字符,也就是说“[io]”表示匹配“i”或者“o”

4)若查找“oo”前面不是“w”的字符串,只需要通过集合字符的反向选择“[^]”来实现该目的。
例如执行“grep -n‘[^w]oo’test.txt”命令表示在 test.txt 文本中查找“oo”前面不是“w”的字符串。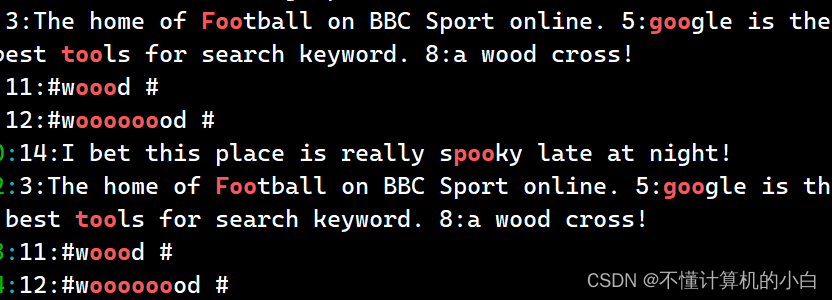 发现这里还是存在二者均包含“w”。其实通过执行结果就可以看出,符合匹配标准的字符加粗显示,而上述结果中可以得知,
发现这里还是存在二者均包含“w”。其实通过执行结果就可以看出,符合匹配标准的字符加粗显示,而上述结果中可以得知,
“#woood #”中加粗显示的是“ooo”,而“oo”前面的“o”是符合匹配规则的。同理“#woooooood #” 也符合匹配规则。若不希望“oo”前面存在小写字母,可以使用“grep -n‘[^a-z]oo’test.txt”命令实现,其中“a-z”表示小写字母,大写字母则通过“A-Z”表示。
grep -n '[^a-z]oo' test.txt

发现这里还存在大写字母想要去掉大写字母可以使用[^A-Z]
Grep -n ‘[^A-Z]oo’ test.sh
5)查找包含数字的行可以通过grep -n ‘[0-9]’ test.txt

6)查找行首“^” 与行尾字符:“$基础正则表达式包含两个定位元字符:“^”(行首)与“$”(行尾)。在上面的示例中, 查询“the”字符串时出现了很多包含“the”的行,如果想要查询以“the”字符串为行首的行,则 可以通过“^”元字符来实现”
Grep -n ‘^the’ test.txt
不想以英文开头则使用:
Grep -n ‘^[^a-zA-Z]’

7)”符号在元字符集合“[]”符号内外的作用是不一样的,在“[]”符号内表示反向选择,在“[]” 符号外则代表定位行首。反之,若想查找以某一特定字符结尾的行则可以使用“$”定位符。
例如,执行以下命令即可实现查询以小数点(.)结尾的行。因为小数点(.)在正则表达式
中也是一个元字符(后面会讲到),所以在这里需要用转义字符“\”将具有特殊意义的字符转
化成普通字符。
Grep -n ‘\.$’ test.txt

查询空白行:
Grep -n ‘^$’ test.txt

8)过滤空行和注释且注入到文件中
grep -v "^$\|^#" k.txt >2.txt


9)过滤出ip
Grep -o “[0-9]\+\.[0-9]\+\.[0-9]\+\.[0-9]\+” /etc/sysconfig/network-scripts/ifcfg-ens33,+表示钱买你的字符串出现一次或多次,而*表示前面的字符出现0次1次或多次。

10)*表示匹配0次一次或多次

Grep -n “go[al]*d” test

表示其中al可以出现0次1次和多次
Grep -n “go[al]\{2\}d” test表示al出现两次

Grep -n “go[al]\{2,\}d” test在次数的后面加,表示至少不少于2次

Grep -n “go[al]\{2,5\}d” test表示出现2-5次

扩展:
Egrep -E -n ‘go[2]d’ test
Egrep即为grep的增强版功能,在使用的时候需要注意,它不再是使用双引号而是单引号,且在使用时,不需要再加转义符即\
Egrep -n ‘of|is|on’ test查询of,is,on字符串,其中的|意思并不是管道符而是(或)

Egrep -E -n ‘t(e|s)st’ test

Egrep -E -n ‘t(e|s)*st’ test

查询以t开头t结尾,中间包含至少一个o的字符串,执行以下命令即可实现
Grep -n ‘ts*t’ test

查询以t开头以t结尾,中间的s可有可无的命令
Grep -n ‘ts.*t’ test
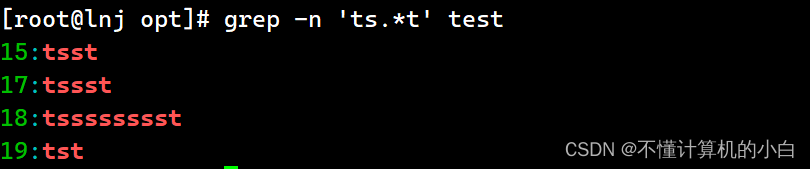
查询以t开头以t结尾,且中间出现es次数不限
Grep -n “^t[(es)]t$” test

Grep -n ‘t\(es\)\{1,2\}t’ test

总结:元字符
通过上面几个简单的示例,可以了解到常见的基础正则表达式的元字符主要包括以下几个
^ 匹配输入字符串的开始位置。除非在方括号表达式中使用,表示不包含该字符集合。要匹配”^”字符本身,请使用"\^"
$ 匹配输入字符串的结尾位置。如果设置了RegExp对象的 Multiline属性,则"$”也匹配'\n'或'\r’,。要匹配”$"字符本身,请使用”\$"
. 匹配除"\r\n"之外的任何单个字符
\ 反斜杠,又叫转义字符,去除其后紧跟的元字符或通配符的特殊意义
* 匹配前面的子表达式零次或多次。要匹配“*"字符,请使用“\*”
[] 字符集合,匹配所包含的任意一个字符。例如,"[abc]"可以匹配"plain"中的"a"
[^] 赋值字符集合,匹配未包含的一个任意字符。例如,"[^abc]"可以匹配"plin"中任何一个字母
[n1-n2] 字符范围,匹配指定范围内的任意一个字符。例如,"[a-z]"可以匹配"a"到"z"范围内的任意一个小写字母字符。注意:只有连字符(-)在字符组内部,并且出现在两个字符之间时,才能表示字符的范围;如果出现在字符组的开头,则只能表示连字符本身
(n} n 是一个非负整数,匹配确定的n次。例如,"o(2}"不能匹配"Bob"中的"o",但是能匹配"food"中的"oo"{n, } n是一个非负整数,至少匹配n次。例如,"o({2,)"不能匹配"Bob"中的"o”,但能匹配""fooood"中的所有o。"o(1,)"等价于"o+"。“o(0,]"则等价于"o*”
{n, m} m和 n均为非负整数,其中 n<=m,最少匹配n次且最多匹配m 次
正则工具
Cut工具
列截取工具,cut命令从文件的每一行剪切字节,字符和字段,并将这额字符,字节,字段挟制标准输出,如果不指定file参数,cut命令将读取标准输入,必须指定-b,-c或-f标志之一
选项:
-b:按宁节截取
-c:按字符截取,常用于中文
-d:指定以什么为分隔符截取,默认为制表符
-f:通常和-d一起
案例:
Cat /etc/passwd | cut -d ‘:’ -f 1,表示-d为以:为分隔符,取第一列


Cat /etc/passwd | cut -d ‘:’ -f 1,3表示以:为分隔符取第一列和第三列,不连续

Cat /etc/passwd | cut -d ‘:’ -f 1-3表示以:为分隔符,取一到三列,连续

ls | cut -b 3表示按字节截取


Ls | cut -c 2 上组代码中-d是以第几个字符来截取,而-c则是以中文字符截取

截取331081504806027044938:
Sort工具
sort是一个以行为单位对文件内容进行排序的工具,也可以根据不同的数据类型来排序,例如数据和字符的排序就不一样,用法:sort 【选项】 【参数】
常用选项:
-t:指定分隔符,默认使用「Tab]键或空格分隔-
-k:指定排序区域,哪个区间排序
-n :按照数字进行排序,默认是以文字形式排序
-u:等同于uniq,表示相同的数据仅显示一行,注意:如果行尾有空格去重就不成功
-r:反向排序,默认是升序,-r就是降序
-o:将排序后的结果转存至指定文件
案例:


Sort sort.txt 什么都不加的话即为默认按第一列升序,字母即从a到z由上

Sort -n -t: -k3 sort.txt 以冒号为分隔符,以数字大小对第三列排序
Sort -nr -t: -k3 passwd.txt 以冒号为分隔符,以数字大小对第三列排序(降序)

Sort -nr -t: -k3 sort.txt -o sort.sh排序后的结果不在屏幕上输出二十输出到sort.sh文件中。

Sort -u sort.txt 避免重复的内容(重复的行可以是不连续的)
Uniq工具
主要用于去除连续的重复行
注意:是连续的行,所以通常和sort结合使用先排序使之变成连续的行在执行去重操作,否则不连续的重复行不能去重
语法:uniq 【选项】【参数】
常用选项:
-c:对重复的行进行计数;
-d:仅显示重复行;
-u:仅显示出现一次的行;
案例
awk ‘{print $1}‘ sort.sh | uniq -c 表示相同的字符连续出现的次数

awk ‘{print $1}‘ sort.sh | uniq -d表示只显示重复的内容

awk ‘{print $1}‘ sort.sh | uniq -u只显示只出现过一次的行

查看当前状态中是连接状态的网络信息
netstat -natpul | grep "ESTABLISHED" | awk '{print $6 " " $4}' | uniq -c

Tr工具
它可以用一个字符来替换另一个字符,或者可以完全出去一些字符,也可以用来重复字符
语法:tr 【选项】 set1 【set2】
从标准输入中替换,缩减或删除字符,并将结果写道标准输出
常用选项:
-d 删除字符
-s 删除所有重复出现的字符,只保留一个
Cat sort.sh | tr -d ‘lnjnb‘


Echo”lnjnnnnnnnnnb” | tr -s ‘n’表示去重,只保留一个

组合题:
- Netstat和ss的区别?
ss比netstat快的主要原因是,netstat是遍历/proc下面每个PID目录,ss直接读/proc/net下面的统计信息。所以ss执行的时候消耗资源以及消耗的时间都比netstat少很多。
当服务器的socket连接数量非常大时(如上万个),无论是使用netstat命令还是直接cat /proc/net/tcp执行速度都会很慢,相比之下ss可以节省很多时间。ss快的秘诀在于,它利用了TCP协议栈中tcp_diag,这是一个用于分析统计的模块,可以获得Linux内核中的第一手信息。如果系统中没有tcp_diag,ss也可以正常运行,只是效率会变得稍微慢但仍然比netstat要快。
- 统计当前连接的主机数
ss -nt | tr -s "" | cut -d "" -f5 | cut -d ":" -f1 | sort|uniq -c

- 统计当前主机的连接状态
Ss -nat | grep -v ‘^state’ | cut -d “” -f1 | sort |uniq -c

![]()
Awk工具
读取一行处理一行即处理一行丢弃一行
工作原理:逐行读取文本,默认以空格为分隔符进行分隔,将分隔所得的各个字段保存到内建变量中,并按模式或者条件执行编辑命令
常用选项
-F 指定分隔符
-v 变量赋值
模式或条件
BGIN, END, >=3 && <=6, /^root/ ,‘{print $1 $2 $0}’
示例:
Awk ‘BEGIN{print “hello”}’
先执行BEGIN的命令,它的优先级最高

Awk -F: ‘BEGIN{print “hello”}{print $1}{print $1}END{print “exit”}’ /etc/passwd
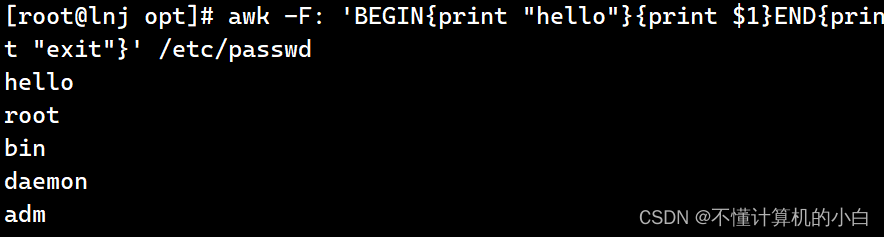

这里再后面加了end,begin优先级为最高,后输出end
Df | awk ‘{print $5}’ | awk -f% ’print $1’
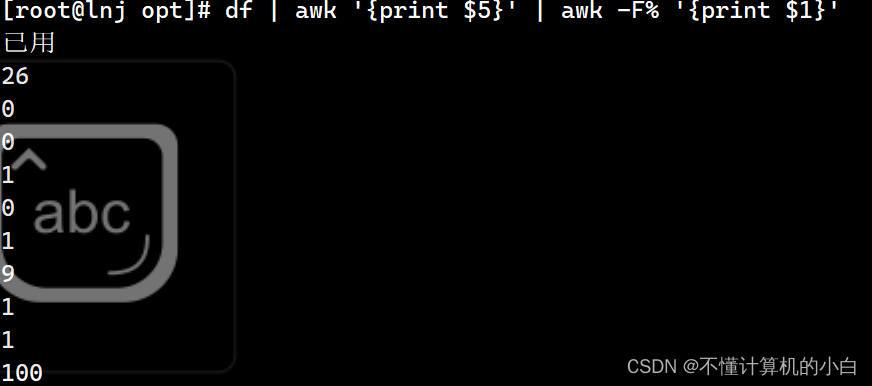
另一种表达方式:df | awk '{print $5}' |awk -F% '{print $1}' | grep -Ev "已用"

df | awk -F "[ %]+" '{print $5}'

cat timu.txt |awk -F. '{print $2}'>>timuxtxt

常见的内置变量
FS:指定每行文本的字段分隔符,缺省为空格或制表位。与"-F”"作用相同-v "FS=:"
OFS:输出时的分隔符
NF:当前处理的行的字段个数
NR:当前处理的行的行号(序数)
$0:当前处理的行的整行内容
$n:当前处理行的第n个字段(第n列)
FILENAME:被处理的文件名
RS:行分隔符。awk从文件上读取资料时,将根据RS的定义就把资料切割成许多条记录,而awk一次仅读入一条记录进行处理。预设值是\n
示例
Cat passwd | awk -v FS=”:” ‘{print $1FS$3}’
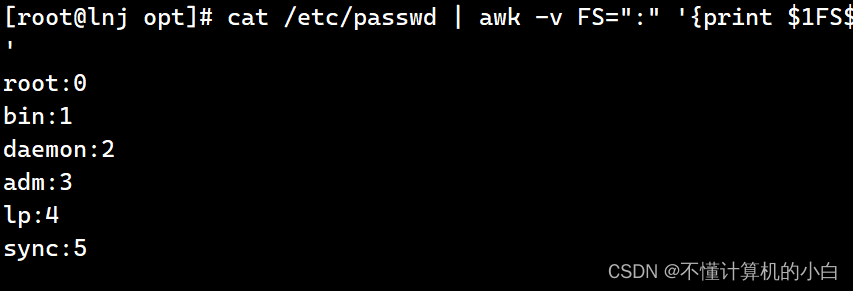
cat /etc/passwd | awk -F: -v OFS='---' '{print $1,$2}'

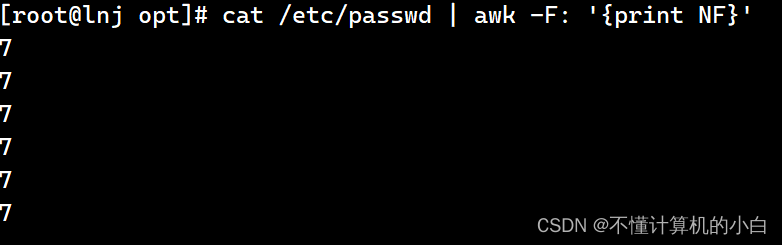
cat /etc/passwd | awk -F: '{print NF}'表示输出的字段为几
cat /etc/passwd |awk -F: '{print $(NF-1)}' |head -n1

cat /etc/passwd |awk -F: '{print NR,$1}'

cat /etc/passwd |awk -F: 'NR==2{print NR,$1}'这里给nr定义,表示第二行

cat /etc/passwd |awk -F: 'NR==2,NR==3{print NR,$1}'表示输出二到三行

cat /etc/passwd |awk -F: 'NR==1||NR==3{print NR,$1}'表示输出第一行和第三行不连续

cat /etc/passwd |awk -F: 'NR==2,NR==3{print NR,$1}'表示输出偶数行,奇数行同意

cat /etc/passwd |awk -F: '$3>1000{print $1,$3}'
打印出普通用户
Uid大于1000

awk '{print FNR}' /opt/11.txt /opt/12.txt表示两个文件拼接一起输出
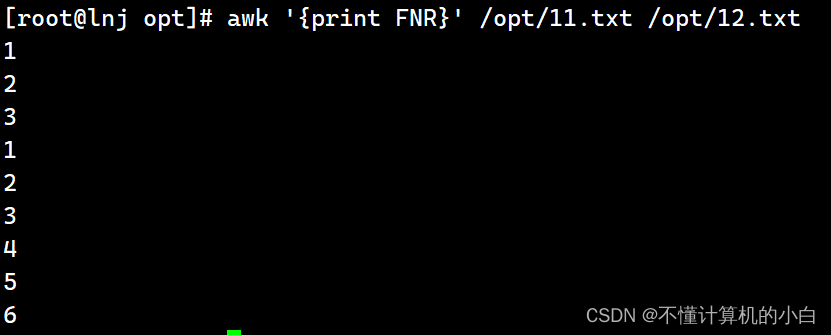
awk -v test='hello' 'BEGIN{print test}'这里可以给变量定义然后输出

awk '/^root/,/^b/{print $0}' /etc/passwd这里表示以root开头b结尾的行


Sed工具:
文本处理工具,读取文本内容,根据指定的条件进行处理,如删除、替换、添加等
可在无交互的情况下实现相当复杂的文本处理操作
被广泛应用于Shell脚本,以完成自动化处理任务
sed依赖于正则表达式
工作原理:

Sed命令格式
sed -e '编辑指令' 文件1 文件2 …
sed -n -e '编辑指令' 文件1 文件2 …
sed -i -e '编辑指令' 文件1 文件2
常用选项
-e 指定要执行的命令,只有一个编辑命令时可省略
-n 只输出处理后的行,读入时不显示
-i 直接编辑文件,而不输出结果
-f 用指定的脚本文件来处理输入的文本文件
-h 或help显示帮助
-r,-E使用扩展正则表达式
-s 将u东哥文件是为独立文件,而不是连续的长文件流
"操作"用于指定对文件操作的动作行为,也就是sed 的命令。通常情况下是采用的"[n1 [ ,n2]]"操作参数的格式。n1、n2是可选的,代表选择进行操作的行数,如操作需要在5~20行之间进行,则表示为"5,20
动作行为"。常见的操作包括以下几种。
a:增加,在当前行下面增加一行指定内容。c:替换,将选定行替换为指定内容。
d:删除,删除选定的行。
i:插入,在选定行上面插入一行指定内容。
p:打印,如果同时指定行,表示打印指定行;如果不指定行,则表示打印所有内容;如果有非打印字符,则以ASCII码输出。其通常与"-n"选项一起使用。
s:替换,替换指定字符。
y:字符转换。
示例
Sed -n ‘p’ test.txt直接打印文本

Sed -n ‘3,5p’ test.txt 表示打印第三行 表示输出3-5行

Sed -n “p;n” sed表示输出奇数行n表示读下一行
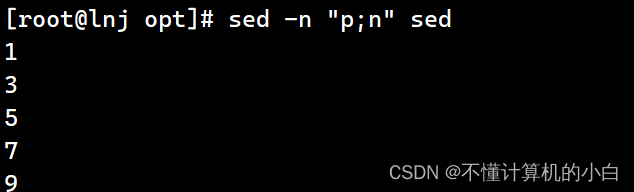
Sed -n “n;p” sed输出偶数行n表示读下一行

Sed -n “1,5{n;p}” sed表示输出1-5行之间的基数行,偶数pn反过来

Sed -n ‘5,${n;p}’ sed表示5行至尾行的偶数行
 d
d
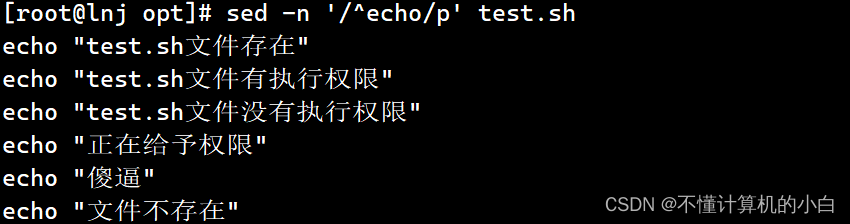
Sed -n ‘/echo/p’ test.sh表示输出包含echo的行

sed -n '6,/echo/p' test.sh表示输出从第六行到包含echo的行

sed -n '/echo/=' test.sh输出echo所在的行=表示输出行号

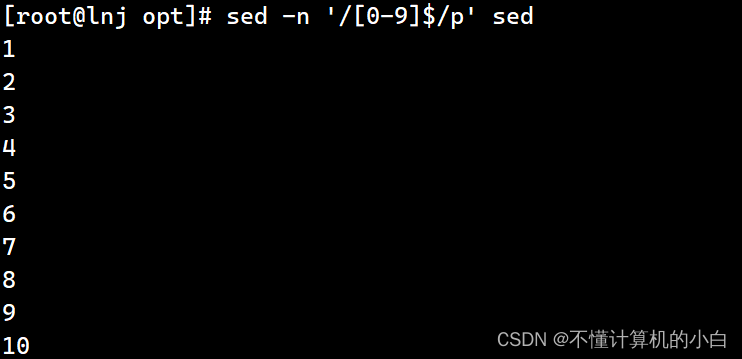
sed -n '/^echo/p' test.sh输出以echo开头的行
sed -n '/^e[0-9]$/p' sed输出以数字结尾的行
Sed -n ‘/\<echo\>/p’ test.sh 输出包含echo字符的行

Nl sed |sed ‘3d’删除第三行
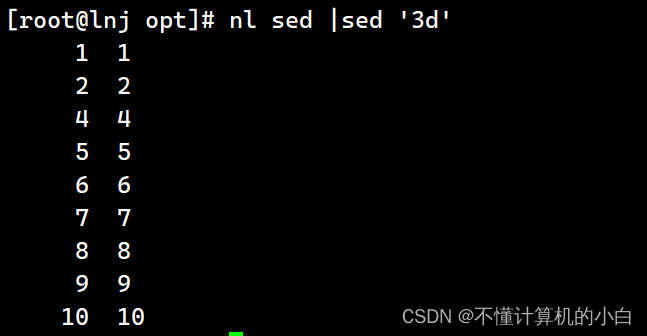
Nl sed |sed ‘3,5d’删除3-5行

Nl sed |sed’/1/d’删除包含1的行

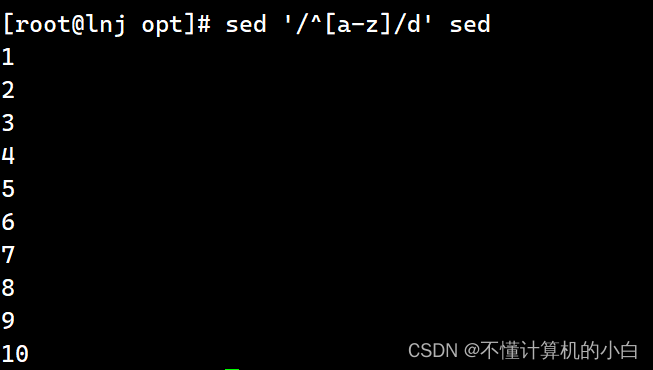
sed '/^[a-z]/d' sed表示删除以英文字母开头的行
以下就不给截图了不然太过冗长
Sed ‘/\.$/d’ sed删除以.为结尾的行
Sed ‘/^$/d’ sed删除所有空行
sed 's/the/THE/" test.txt将每行中的第一个the替换为THE
sed 's/l/LI2' test.txt 将每行中的第2个I替换为L
sed 's/the/THE/g" test.txt 将文件中的所有the替换为THE
sed 's/o//g" test.txt 将文件中的所有o删除(替换为空串)
sed 's//#l"test.txt 在每行行首插入#号
sed "/thels//#/"test.txt 在包含the 的每行行首插入#号
sed 's/$/EOF/" test.txt 在每行行尾插入字符串 EOF
sed '3,5s/the/THE/g" test.txt 将第3~5行中的所有the替换为THE
sed "/the/s/o/O‘g" test.txt 将包含the 的所有行中的o都替换为О
sed '/thel{H;d};$G' test.txt将包含the 的行迁移至文件末尾,舟用于多个操作
sed "1,5{H;d};17G' test.txt 将第1~5行内容转移至第17行后
sed '/the/w out.file" test.txt 将包含the 的行另存为文件 out.file
sed '/the/r /etc/hostname' test.txt 将文件letc/hostname 的内容添加到包含the 的每行以后
sed '"3aNew" test.txt 在第3行后插入一个新行,内容为New
sed '/the/aNew" test.txt 在包含the的每行后插入一个新行,内容为New
sed '3aNew1\nNew2' test.txt 在第3行后插入多行内容,中间的\n表示换行
边栏推荐
- PHP 判断文件是否有内容,没有内容则复制另一个文件写入
- Interface Automation Testing Basics
- numpy.meshgrid()理解
- 缺少比较器,运放来救场!(运放当做比较器电路记录)
- Import other custom namespaces in C#
- 3DS MAX batch export file script MAXScript with interface
- usb转rs485测试软件,usb转rs485「建议收藏」
- 串口服务器调试助手使用教程,串口调试助手使用教程【操作方式】
- PHP judges whether the file has content, and if there is no content, copy another file to write
- 递归递推之计算组合数
猜你喜欢

AWS Security Fundamentals
Classifying irises using decision trees
ABAP 里文件操作涉及到中文字符集的问题和解决方案试读版

高数_证明_曲率公式
laravel throws the error to Dingding
2022-08-09: What does the following go code output?A: No, it will panic; B: Yes, it can run correctly; C: Not sure, see the voting result.package main import (“fmt“ “syn
2022年中国软饮料市场洞察
laravel 抛错给钉钉
![[Study Notes] Persistence of Redis](/img/e4/d3c09754ca5ac4fdad2653ccca6d82.png)
[Study Notes] Persistence of Redis

How does IT Xiaobai learn PHP systematically
随机推荐
NAACL 2022 | 简单且高效!随机中间层映射指导的知识蒸馏方法
舵机内部结及工作原理浅析[通俗易懂]
【POI 2008, BLO】割点
Stream通过findFirst()查找满足条件的一条数据
【POI 2008, BLO】Cut Point
Drive IT Modernization with Low Code
PHP judges whether the file has content, and if there is no content, copy another file to write
ABAP file operations involved in the Chinese character set of problems and solutions for trying to read
Lithium battery technology
高数_证明_弧微分公式
2011年下半年 系统架构设计师 下午试卷 II
Network Saboteur
Fragment-hide和show
PEST 分析法
Classifying irises using decision trees
The recursive recursive Fighting_ silver study ah but level 4
池化技术有多牛?来,告诉你阿里的Druid为啥如此牛逼!
【剑指offer】---数组中的重复数字
简单的写一个防抖跟节流
【JS高级】ES5标准规范之创建子对象以及替换this_10