当前位置:网站首页>[code analysis (3)] communication efficient learning of deep networks from decentralized data
[code analysis (3)] communication efficient learning of deep networks from decentralized data
2022-04-23 13:47:00 【Silent city of the sky】
update.py
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# Python version: 3.6
import torch
from torch import nn
from torch.utils.data import DataLoader, Dataset
class DatasetSplit(Dataset):
"""An abstract Dataset class wrapped around Pytorch Dataset class.
"""
''''
Data set partitioning
'''
def __init__(self, dataset, idxs):
self.dataset = dataset
self.idxs = [int(i) for i in idxs]
def __len__(self):
return len(self.idxs)
def __getitem__(self, item):
image, label = self.dataset[self.idxs[item]]
# sampling in idxs = np.arange(60000)
# [1, 2]-->>tensor([1, 2])
return torch.tensor(image), torch.tensor(label)
class LocalUpdate(object):
def __init__(self, args, dataset, idxs, logger):
# Local update
self.args = args
self.logger = logger # Recorder
self.trainloader, self.validloader, self.testloader = \
self.train_val_test(dataset, list(idxs))
self.device = 'cuda' if args.gpu else 'cpu'
# Default criterion set to NLL loss function
self.criterion = nn.NLLLoss().to(self.device)
'''
The default standard setting is NLL Loss function
similar :net = net.to(device)
CrossEntropyLoss()=log_softmax() + NLLLoss()
softmax(x)+log(x)+nn.NLLLoss====>nn.CrossEntropyLoss
among softmax Function is also called normalized exponential function , It can compress a multidimensional vector into (0,1) Between , And their sum is 1
'''
def train_val_test(self, dataset, idxs):
"""
This function is called above
Returns train, validation and test dataloaders for a given dataset
and user indexes.
Given a data set, return : Training set , Verification set , Test set
For a given dataset and user index
"""
# split indexes for train, validation, and test (80, 10, 10)
idxs_train = idxs[:int(0.8*len(idxs))]
idxs_val = idxs[int(0.8*len(idxs)):int(0.9*len(idxs))]
idxs_test = idxs[int(0.9*len(idxs)):]
'''
Partition index scale (80,10,10)
'''
trainloader = DataLoader(DatasetSplit(dataset, idxs_train),
batch_size=self.args.local_bs, shuffle=True)
'''
shuffle Set to True every last epoch All shuffle the data
DataLoader(training_data, batch_size=64, shuffle=True)
'''
validloader = DataLoader(DatasetSplit(dataset, idxs_val),
batch_size=int(len(idxs_val)/10), shuffle=False)
testloader = DataLoader(DatasetSplit(dataset, idxs_test),
batch_size=int(len(idxs_test)/10), shuffle=False)
return trainloader, validloader, testloader
def update_weights(self, model, global_round):
# Set mode to train model
'''
Update weights
'''
model.train()
'''
Tell our network , This stage is for training , Parameters can be updated
'''
epoch_loss = []
# Set optimizer for the local updates
'''
Select optimizer for local updates
'''
if self.args.optimizer == 'sgd':
optimizer = torch.optim.SGD(model.parameters(), lr=self.args.lr,
momentum=0.5)
elif self.args.optimizer == 'adam':
optimizer = torch.optim.Adam(model.parameters(), lr=self.args.lr,
weight_decay=1e-4)
# epoch
for iter in range(self.args.local_ep):
batch_loss = []
for batch_idx, (images, labels) in enumerate(self.trainloader):
'''
batch_idx
(images, labels)
enumerate(self.trainloader) The training set data will be a
batch One batch Take it out to train
Use enumerate Conduct dataloader Used to read data in
The training of neural network is the first data reading method , Its basic form
That is to say for index, item in enumerate(dataloader['train']),
among item in 0 For data ,1 by label.
'''
images, labels = images.to(self.device), labels.to(self.device)
model.zero_grad()
'''
Set the parameter gradient of the model to 0
'''
log_probs = model(images)
'''
Obtain the propagation result of the preceding item
model When the function is called, it will call call, So call forward.
'''
loss = self.criterion(log_probs, labels)
'''
This code is called cross entropy :log_softmax()+NLLLoss()
from torch import nn
self.criterion = nn.NLLLoss().to(self.device)
loss=nn.NLLLoss()
loss(input,target)
CrossEntropyLoss()=log_softmax() + NLLLoss()
softmax(x)+log(x)+nn.NLLLoss====>nn.CrossEntropyLoss
'''
loss.backward()
'''
The most important back-propagation calculation in deep learning ,
pytorch Use a very simple backward() The function realizes
'''
optimizer.step()
'''
be-all optimizer It's all done step() Method ,
This method will update all parameters
'''
if self.args.verbose and (batch_idx % 10 == 0):
'''
for batch_idx, (images, labels) in enumerate(self.trainloader):
'''
print('| Global Round : {} | Local Epoch : {} | [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(
global_round,
iter,
batch_idx * len(images),
len(self.trainloader.dataset),
100. * batch_idx / len(self.trainloader),
loss.item()))
'''
batch_idx by batch Quantity ?
len(images) For one batch The data in is batch_size
batch_idx * len(images) Is the amount of data
'''
'''
Global rounds :
Local epoch:
Loss loss:
'''
self.logger.add_scalar('loss', loss.item())
'''
add_scalar(tag, scalar_value, global_step=None, ):
Save the data we need in a file for visualization
scalar_value( Floating point or string ):y Axis data ( They count )
'''
batch_loss.append(loss.item())
'''
batch_loss = []
stay for Cycle to the next epoch,append once
'''
epoch_loss.append(sum(batch_loss)/len(batch_loss))
'''
Finish all epoch
epoch_loss = []
Yes loss Averaging
'''
'''
state_dict Variable storage training process need to learn the weight and paranoia coefficient
state_dict As python The dictionary object maps the parameters of each layer to tensor tensor
It should be noted that torch.nn.Module Module state_dict Only the parameters of convolution layer and full connection layer are included
'''
return model.state_dict(), sum(epoch_loss) / len(epoch_loss)
def inference(self, model):
""" Returns the inference accuracy and loss.
"""
'''
Returns the inference accuracy and loss
'''
model.eval()
'''
1. Tell our network , This stage is used to test , Therefore, the parameters of the model are not updated at this stage
Use PyTorch When training and testing, we must pay attention to the instantiation of
model Appoint train/eval,eval() when , The frame will automatically put
BN and DropOut Hold on , No averaging , It's about training ,
otherwise , once test Of batch_size Too small , It's easy to
By BN Layer causes color distortion in the generated image
'''
loss, total, correct = 0.0, 0.0, 0.0
for batch_idx, (images, labels) in enumerate(self.testloader):
'''
batch_idx
(images, labels)
enumerate(self.trainloader) The training set data will be a
batch One batch Take it out to train
Use enumerate Conduct dataloader Used to read data in
The training of neural network is the first data reading method , Its basic form
That is to say for index, item in enumerate(dataloader['train']),
among item in 0 For data ,1 by label.
'''
images, labels = images.to(self.device), labels.to(self.device)
# Inference infer
outputs = model(images)
batch_loss = self.criterion(outputs, labels)
'''
Write like this
crossentropyloss=nn.CrossEntropyLoss()
crossentropyloss_output=crossentropyloss(x_input,y_target)
print('crossentropyloss_output:\n',crossentropyloss_output)
bool value of Tensor with more than one value is ambiguous
It can't be written like this :
xx = nn.CrossEntropyLoss(x_input, y_target)
print(xx)
'''
loss += batch_loss.item()
# Prediction
'''
The prediction process
'''
_, pred_labels = torch.max(outputs, 1)
'''
_ Is the maximum per line
pred_labels Index representing the maximum value of each row
But why is it named pred_labels( Forecast tags )
torch.max(input, dim)
input yes softmax One of the outputs of the function tensor
dim yes max The dimension of the functional index 0/1,0 Is the maximum per column ,1 Is the maximum per line
The function returns two tensor,
first tensor Is the maximum per line ;
the second tensor Is the index of the maximum value per row
'''
pred_labels = pred_labels.view(-1)
'''
tensor([2, 2]).view(-1) The result remains unchanged.
tensor([[1, 1, 1]]).view(-1) The result is tensor([1, 1, 1])
b=torch.Tensor([[[1,2,3],[4,5,6]]])
Its structure is
[1,4]
[2,5]
[3,6]
a=torch.Tensor([[1,2,3],[4,5,6]])
Its structure is
[1,2,3]
[4,5,6]
b=torch.Tensor([[[1,2,3]]])
Its structure is
[1]
[2]
[3]
'''
correct += torch.sum(torch.eq(pred_labels, labels)).item()
# corrent Store the number of matches between the predicted tag and the real tag
'''
torch.eq:
Compare the two tensor Whether the numbers correspond to the same position , Same as 1, Otherwise 0
pred_label=torch.Tensor([1,2,3])
labels=torch.Tensor([1,0,3])
torch.eq(pred_label, labels):
tensor([ True, False, True])
torch.sum(torch.eq(pred_label, labels):
tensor(2)
torch.sum:
Is to add all the values , But what we get is still a tensor
tensor(2)
tensor.item():
label=torch.Tensor([2])
print(label.item())
tensor Only one element in the can be used in this way item()
'''
total += len(labels)
'''
total How many rows? ?
'''
accuracy = correct/total
return accuracy, loss
def test_inference(args, model, test_dataset):
# Returns the accuracy and loss of the test
"""
def inference(self, model):
test The inference function is different from the original inference function
First, the data set is different
The original inference function is :self.testloader
def train_val_test(self, dataset, idxs):
This function is used to return testloader
test Inference function : The dataset is test_dataset
Returns the test accuracy and loss.
"""
model.eval()
'''
1. Tell our network , This stage is used to test , Therefore, the parameters of the model are not updated at this stage
Use PyTorch When training and testing, we must pay attention to the instantiation of
model Appoint train/eval,eval() when , The frame will automatically put
BN and DropOut Hold on , No averaging , It's about training ,
otherwise , once test Of batch_size Too small , It's easy to
'''
loss, total, correct = 0.0, 0.0, 0.0
device = 'cuda' if args.gpu else 'cpu'
criterion = nn.NLLLoss().to(device)
'''
The default standard setting is NLL Loss function
similar :net = net.to(device)
CrossEntropyLoss()=log_softmax() + NLLLoss()
softmax(x)+log(x)+nn.NLLLoss====>nn.CrossEntropyLoss
among softmax Function is also called normalized exponential function , It can take a multidimensional vector
Compress in (0,1) Between , And their sum is 1
'''
testloader = DataLoader(test_dataset, batch_size=128,
shuffle=False)
'''
testloader = DataLoader(DatasetSplit(dataset, idxs_test),
batch_size=int(len(idxs_test)/10), shuffle=False)
'''
# The above three lines are different from the original inference function
# And below for The inference function in the loop is enumerate(self.testloader)
for batch_idx, (images, labels) in enumerate(testloader):
images, labels = images.to(device), labels.to(device)
'''
batch_idx
(images, labels)
enumerate(self.trainloader) The training set data will be a
batch One batch Take it out to train
Use enumerate Conduct dataloader Used to read data in
The training of neural network is the first data reading method , Its basic form
That is to say for index, item in enumerate(dataloader['train']),
among item in 0 For data ,1 by label.
'''
# Inference
outputs = model(images)
batch_loss = criterion(outputs, labels)
'''
Write like this
crossentropyloss=nn.CrossEntropyLoss()
crossentropyloss_output=crossentropyloss(x_input,y_target)
print('crossentropyloss_output:\n',crossentropyloss_output)
bool value of Tensor with more than one value is ambiguous
It can't be written like this :
xx = nn.CrossEntropyLoss(x_input, y_target)
print(xx)
'''
loss += batch_loss.item()
# Prediction
'''
forecast
'''
_, pred_labels = torch.max(outputs, 1)
'''
_ Is the maximum per line
pred_labels Index representing the maximum value of each row
But why is it named pred_labels( Forecast tags )
torch.max(input, dim)
input yes softmax One of the outputs of the function tensor
dim yes max The dimension of the functional index 0/1,0 Is the maximum per column ,1 Is the maximum per line
The function returns two tensor,
first tensor Is the maximum per line ;
the second tensor Is the index of the maximum value per row
'''
pred_labels = pred_labels.view(-1)
'''
tensor([2, 2]).view(-1) The result remains unchanged.
tensor([[1, 1, 1]]).view(-1) The result is tensor([1, 1, 1])
b=torch.Tensor([[[1,2,3],[4,5,6]]])
Its structure is
[1,4]
[2,5]
[3,6]
a=torch.Tensor([[1,2,3],[4,5,6]])
Its structure is
[1,2,3]
[4,5,6]
b=torch.Tensor([[[1,2,3]]])
Its structure is
[1]
[2]
[3]
'''
correct += torch.sum(torch.eq(pred_labels, labels)).item()
# corrent Store the number of matches between the predicted tag and the real tag
'''
torch.eq:
Compare the two tensor Whether the numbers correspond to the same position , Same as 1, Otherwise 0
pred_label=torch.Tensor([1,2,3])
labels=torch.Tensor([1,0,3])
torch.eq(pred_label, labels):
tensor([ True, False, True])
torch.sum(torch.eq(pred_label, labels):
tensor(2)
torch.sum:
Is to add all the values , But what we get is still a tensor
tensor(2)
tensor.item():
label=torch.Tensor([2])
print(label.item())
tensor Only one element in the can be used in this way item()
'''
total += len(labels)
accuracy = correct/total
return accuracy, loss
版权声明
本文为[Silent city of the sky]所创,转载请带上原文链接,感谢
https://yzsam.com/2022/04/202204230556365805.html
边栏推荐
- Android 面试主题集合整理
- Test the time required for Oracle library to create an index with 7 million data in a common way
- Why do you need to learn container technology to engage in cloud native development
- AI21 Labs | Standing on the Shoulders of Giant Frozen Language Models(站在巨大的冷冻语言模型的肩膀上)
- RAC environment alert log error drop transient type: systp2jw0acnaurdgu1sbqmbryw = = troubleshooting
- [multi screen interaction] realize dual multi screen display II: startactivity mode
- 零拷贝技术
- Failure to connect due to improper parameter setting of Rac environment database node. Troubleshooting
- ./gradlew: Permission denied
- 聯想拯救者Y9000X 2020
猜你喜欢

SQL learning | complex query

10g database cannot be started when using large memory host

Special window function rank, deny_ rank, row_ number

【重心坐标插值、透视矫正插值】原理以及用法见解
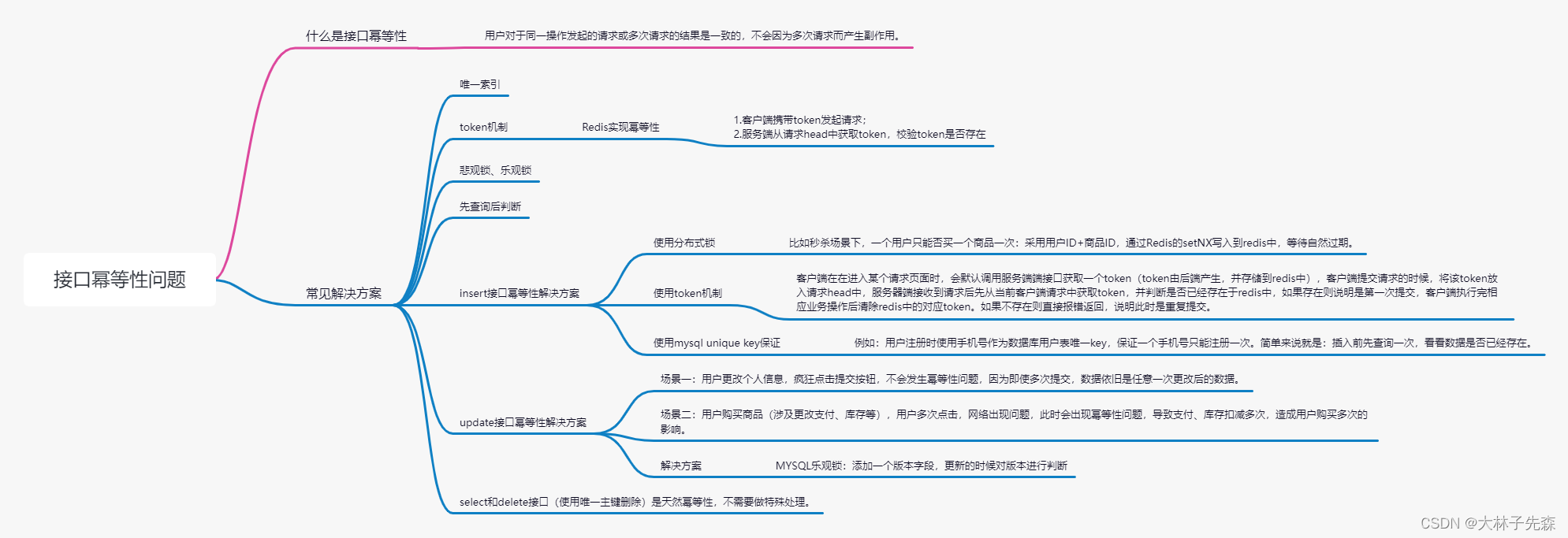
Interface idempotency problem

TIA博途中基於高速計數器觸發中斷OB40實現定點加工動作的具體方法示例

AI21 Labs | Standing on the Shoulders of Giant Frozen Language Models(站在巨大的冷冻语言模型的肩膀上)

Small case of web login (including verification code login)
UML统一建模语言
[barycentric coordinate interpolation, perspective correction interpolation] principle and usage opinions
随机推荐
Building MySQL environment under Ubuntu & getting to know SQL
Oracle and MySQL batch query all table names and table name comments under users
QT调用外部程序
Generate 32-bit UUID in Oracle
NPM err code 500 solution
Part 3: docker installing MySQL container (custom port)
Personal learning related
Handling of high usage of Oracle undo
Oracle renames objects
Ai21 labs | standing on the shoulders of giant frozen language models
Leetcode | 38 appearance array
Lenovo Savior y9000x 2020
Oracle index status query and index reconstruction
JUC interview questions about synchronized, ThreadLocal, thread pool and atomic atomic classes
Use future and countdownlatch to realize multithreading to execute multiple asynchronous tasks, and return results after all tasks are completed
MySQL [acid + isolation level + redo log + undo log]
MySQL [read / write lock + table lock + row lock + mvcc]
Usereducer basic usage
【重心坐标插值、透视矫正插值】原理以及用法见解
Small case of web login (including verification code login)