当前位置:网站首页>scikit-learn随机数据生成实例
scikit-learn随机数据生成实例
2022-08-08 06:20:00 【波尔德】
1.1使用make_regression生成回归模型数据
几个关键参数有:n_samples(生成样本数), n_features(样本特征数),noise(样本随机噪音)和coef(是否返回回归系数)。例子代码如下:
import matplotlib.pyplot as plt
from sklearn.datasets import make_regression
# X为样本特征,y为样本输出, coef为回归系数,共1000个样本,每个样本1个特征
X, y, coef = make_regression(n_samples=1000, n_features=1, noise=10, coef=True)
# 画图
plt.scatter(X, y, color='black')
plt.plot(X, X * coef, color='blue',
linewidth=3)
plt.xticks(())
plt.yticks(())
plt.show()
运行结果: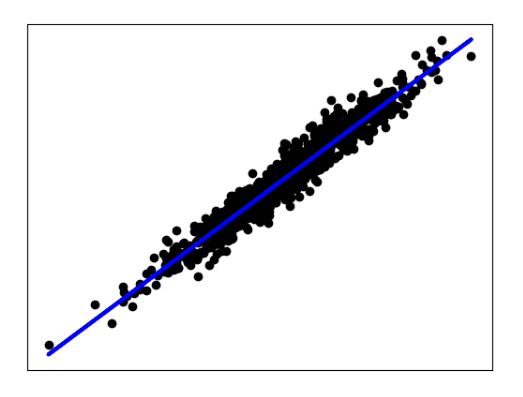
1.2使用make_blobs生成聚类模型数据
用make_classification生成三元分类模型数据。
几个关键参数有n_samples(生成样本数), n_features(样本特征数), n_redundant(冗余特征数)和n_classes(输出的类别数),例子代码如下:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_classification
# X1为样本特征,Y1为样本类别输出, 共400个样本,每个样本2个特征,输出有3个类别,没有冗余特征,每个类别一个簇
X1, Y1 = make_classification(n_samples=400, n_features=2, n_redundant=0,
n_clusters_per_class=1, n_classes=3)
plt.scatter(X1[:, 0], X1[:, 1], marker='o', c=Y1)
plt.show()
运行结果:
1.3使用make_blobs生成聚类模型数据
几个关键参数有:n_samples(生成样本数), n_features(样本特征数),centers(簇中心的个数或者自定义的簇中心)和cluster_std(簇数据方差,代表簇的聚合程度)。代码如下:
import matplotlib.pyplot as plt
from sklearn.datasets import make_blobs
# X为样本特征,Y为样本簇类别, 共1000个样本,每个样本2个特征,共3个簇,簇中心在[-1,-1], [1,1], [2,2], 簇方差分别为[0.4, 0.5, 0.2]
X, y = make_blobs(n_samples=1000, n_features=2, centers=[[-1,-1], [1,1], [2,2]], cluster_std=[0.4, 0.5, 0.2])
plt.scatter(X[:, 0], X[:, 1], marker='o', c=y)
plt.show()
运行结果: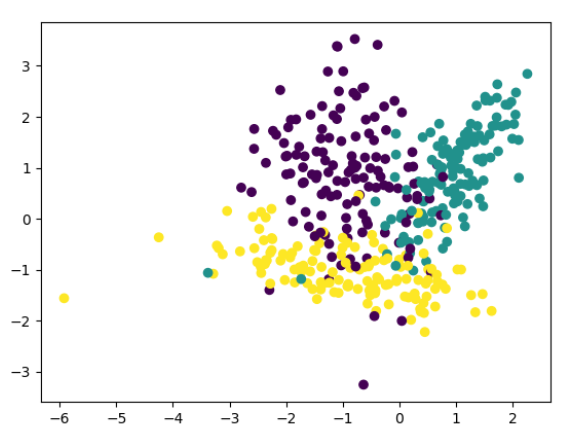
1.4 用make_gaussian_quantiles生成分组多维正态分布的数据。
几个关键参数有:n_samples(生成样本数), n_features(正态分布的维数),mean(特征均值), cov(样本协方差的系数), n_classes(数据在正态分布中,按分位数分配的组数)。 代码如下:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_gaussian_quantiles
#生成2维正态分布,生成的数据按分位数分成3组,1000个样本,2个样本特征均值为1和2,协方差系数为2
X1, Y1 = make_gaussian_quantiles(n_samples=1000, n_features=2, n_classes=3, mean=[1,2],cov=2)
plt.scatter(X1[:, 0], X1[:, 1], marker='o', c=Y1)
plt.show()
运行结果如下所示:
边栏推荐
- convolutional neural network image recognition, convolutional neural network image processing
- 神经网络参数量和计算量,神经网络是参数模型吗
- 结合实践总结docker 安装 mysql5.7
- 机器学习之R语言caret包trainControl函数详解
- docker安装Mysql和其数据持久化
- String title parsing
- 缓存存在的问题:缓存穿透、缓存击穿、缓存雪崩
- string hash hash value
- Several postman features worth collecting will help you do more with less!
- Day8:面试必考编程题(细心OJ)
猜你喜欢






随机推荐
字符串哈希 哈希值
String title parsing
2021 mathematical modeling national competition question B
MySQL5
Day8:面试必考编程题(细心OJ)
flex布局属性简约速记
Promise的使用与async/await的使用
C face recognition
cnn卷积神经网络反向传播,卷积神经网络维度变化
Rust学习:5_所有权与借用
leetcode 232. Implement Queue using Stacks 用栈实现队列(简单)
Neural network to solve what problem, neural network results is not stable
pta补坑简单图论
刚学,这是怎么回事,SQL怎么转运错误啊
Shorthand for flex layout properties
日常bug小结:
数字IC设计笔试题汇总(四):一些基础知识点
独立成分分析ICA/FastICA
Horizontal version of the generated image uniapp H5 signature
仿QQ好友列表,QListWidget!