当前位置:网站首页>添加spark的相关依赖和打包插件(第六弹)
添加spark的相关依赖和打包插件(第六弹)
2022-08-10 06:20:00 【发量不足】
目录
步骤1 打开pom.xmlà添加的以下依赖,点击右下角enable auto-import自动下载
步骤2 右击main下的Scala文件先创建一个package并命名为cn.itcast
步骤3 创建WordCount.scala文件用于词频统计 alt+回车:选择导入包
步骤3 创建WordCount.scala文件用于词频统计 alt+回车:选择导入包
注意:需要事先在D盘创建word文件夹下的words.txt里面内容如下:(最好不要用中文路径)

添加spark的相关依赖和打包插件
步骤1 打开pom.xmlà添加的以下依赖,点击右下角enable auto-import自动下载
<!--设置依赖版本号-->
<properties>
<scala.version>2.11.8</scala.version>
<hadoop.version>2.7.1</hadoop.version>
<spark.version>2.0.0</spark.version>
</properties>
<dependencies>
<!--Scala-->
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>${scala.version}</version>
</dependency>
<!--Spark-->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>${spark.version}</version>
</dependency>
<!--Hadoop-->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>${hadoop.version}</version>
</dependency>
</dependencies>添加完依赖后选择自动载入

步骤2 右击main下的Scala文件先创建一个package并命名为cn.itcast
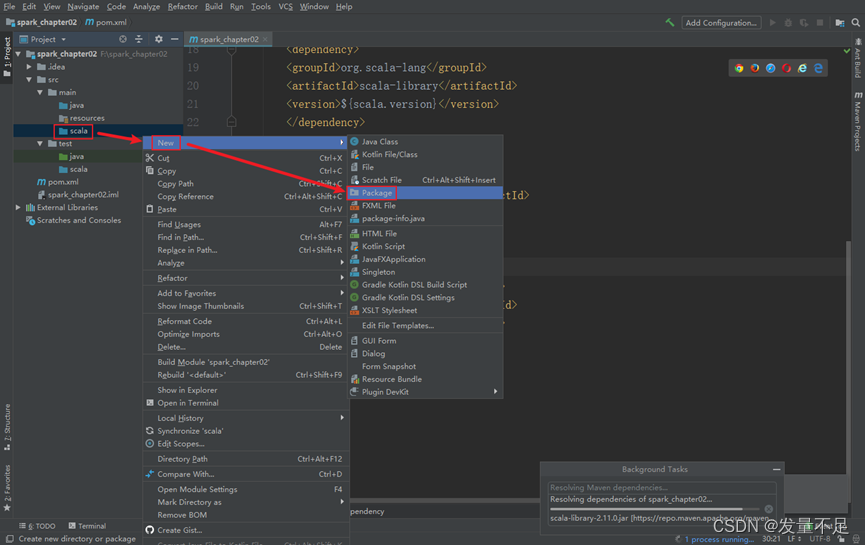

步骤3 创建WordCount.scala文件用于词频统计 alt+回车:选择导入包
问题:没有scala文件创建选项

解决方法:




添加完插件包后即可: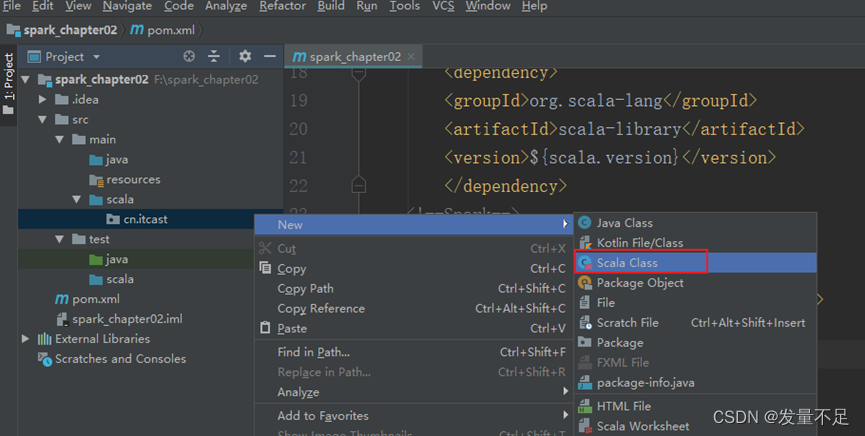

步骤3 创建WordCount.scala文件用于词频统计 alt+回车:选择导入包
注意:需要事先在D盘创建word文件夹下的words.txt里面内容如下:(最好不要用中文路径)

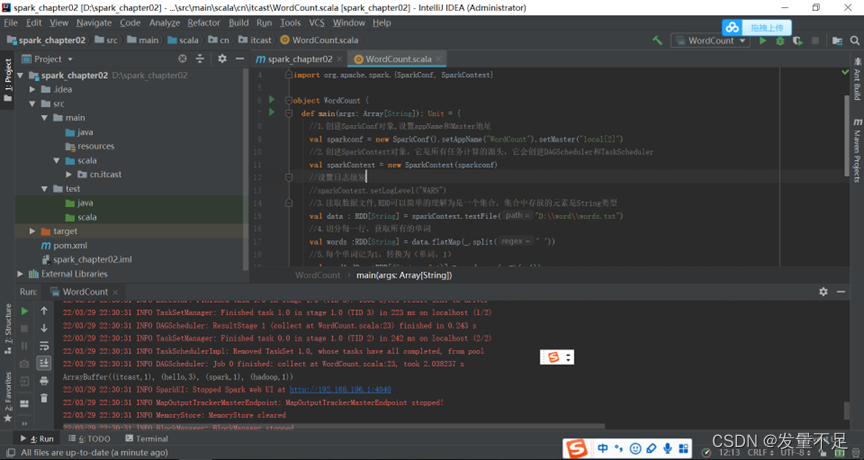
package cn.itcast
# 导入包
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object WordCount {
def main(args: Array[String]): Unit = {
//1.创建SparkConf对象,设置appName和Master地址
val sparkconf = new SparkConf().setAppName("WordCount").setMaster("local[2]")
//2.创建SparkContext对象,它是所有任务计算的源头,它会创建DAGScheduler和TaskScheduler
val sparkContext = new SparkContext(sparkconf)
//设置日志级别
//sparkContext.setLogLevel("WARN")
//3.读取数据文件,RDD可以简单的理解为是一个集合,集合中存放的元素是String类型
val data : RDD[String] = sparkContext.textFile("D:\\word\\words.txt")
//4.切分每一行,获取所有的单词
val words :RDD[String] = data.flatMap(_.split(" "))
//5.每个单词记为1,转换为(单词,1)
val wordAndOne :RDD[(String, Int)] = words.map(x =>(x,1))
//6.相同单词汇总,前一个下划线表示累加数据,后一个下划线表示新数据
val result: RDD[(String, Int)] = wordAndOne.reduceByKey(_+_)
//7.收集打印结果数据
val finalResult: Array[(String, Int)] = result.collect()
println(finalResult.toBuffer)
//8.关闭sparkContext对象
sparkContext.stop()
}
}
可以看到计算出的单词频数itcast(1)Hadoop(1)spark(1)hello(3)

可能碰到的问题:
如果遇到运行结果报错或者结果没出来,则是没放Scala-sdk-2.11.8
解决方法:



如果没有则需要手动添加:



解决以上问题,运行结果如下
可以看到计算出的单词频数itcast(1)Hadoop(1)spark(1)hello(3)
边栏推荐
- Qt滚动条(QScrollBar)圆角样式问题跟踪
- 自组织是管理者和成员的双向奔赴
- [网络安全]实操AWVS靶场复现CSRF漏洞
- OSPF的dr和bdr
- 椭圆曲线离散对数问题以及求解
- 第11章 数据库的设计规范【2.索引及调优篇】【MySQL高级】
- Unity3d famous project-Dark Tree translation
- Elementary Structure
- Nude speech - lying flat - brushing questions - big factory (several tips for Android interviews)
- COLMAP+OpenMVS realizes 3D reconstruction mesh model of objects
猜你喜欢

ES13 - ES2022 - 第 123 届 ECMA 大会批准了 ECMAScript 2022 语言规范

ebp/栈帧/call stack
![[Network Security] Practice AWVS Range to reproduce CSRF vulnerability](/img/7f/f08e429e3d8ede03a1c1754e256f99.png)
[Network Security] Practice AWVS Range to reproduce CSRF vulnerability

MySQL's InnoDB engine (6)

复现dns外带数据结合sqlmap

进制的前缀表示和后缀表示
Grammar Basics (Judgment Statements)

【愚公系列】2022年08月 Go教学课程 034-接口和多态

A few lines of code can crash the system;

elf文件与链接脚本
随机推荐
【Day10】进程管理命令
C语言文件操作
Qt程序字体初始化引起的白屏问题
Qt绘制椭圆曲线的角度问题(离心角和旋转角)
数据库学习之数据类型
全网可达,实现备份
CuteOneP is a PHP-based OneDrive multi-network disk mount program with member synchronization and other functions
Parallax Mapping: More Realistic Texture Detail Representation (Part 1): Why Use Parallax Mapping
结构体初阶
2022河南萌新联赛第(五)场:信息工程大学 K - 矩阵生成
Qt滚动条(QScrollBar)圆角样式问题跟踪
BUUCTF笔记(web)
MySQL's InnoDB engine (6)
排序二叉树代码
QScroller的QScrollerProperties参数研究
2022河南萌新联赛第(五)场:信息工程大学 H - 小明喝奶茶
动态规划——从0-1背包问题到leetcode正则匹配
Nude speech - lying flat - brushing questions - big factory (several tips for Android interviews)
【机器学习】神经网络中的优化器
COLMAP+OpenMVS实现物体三维重建mesh模型