当前位置:网站首页>深度学习--神经网络(基础讲解)
深度学习--神经网络(基础讲解)
2022-08-09 10:15:00 【AI_孟菜菜】
神经网络:
什么是神经网络?
首先明白我们的目的是想要做人工智能,既然是人工智能就想让机器去模仿人,那么人最大的特点就是有很多的神经元,从而可以思考,因此基于这个想法,搭建出来了人工神经网络,有大量的节点构建出来的一个网络,不过这毕竟是个抽象的概念,节点通常就用来储存数字啦,而边一般都用来储存权重,以及传给哪些神经元。
神经网络分为前馈神经网络和反馈神经网络
前馈神经网络:是最简单的一种神经网络,采用单向多层的结构,各个神经元分层排列,每个神经元之于前一层的神经元相连,接受前一层的输入,并输出传递给下一层,各层之间没有反馈。
输入节点:外界信息进行输入,不进行任何的计算,仅向下一层的节点传递信息
隐藏节点:接收上一层的输入,进行计算,并传递给下一层的节点
输出节点:接收上一层的输入,进行计算,并输出最终的结果
输入层和输出层必须有,但是隐藏层可以没有(单层感知机),也可以有多层(这样的前馈神经网络就叫做多层感知机)
反馈神经网络:又叫做递归神经网络,是一种将输出经过一步的时移,再次接入到输入层当中,这类网络神经元可以互连。
举一个反馈神经网络的例子
前馈神经网络和反馈神经网络的主要区别
1.前馈神经网络只接受上一层传来的数据,处理然后接着再传入到下一层, 数据是正向流动的,而反馈神经网络神经元之间是由连接的,数据可以反馈到前层。
2.前馈神经网络不考虑输出和输入时间上的延迟,只能表示出输出和输入之间的一个映射关系,而反馈神经网络不同,他会考虑输出和输入之间的延迟,会考虑到输出对输入是否有用。
3.相比较前馈神经网络,反馈神经网络更适合记忆等功能。
如何设计一个神经网络?
- 设计一个神经网络,输入层和输出层的节点个数往往是固定的,而中间的隐藏层是自己指定的。
- 在一个神经网络的图中,圆圈代表神经元,线代表神经元之间的连接,每条线上都会对应一个权重。这个权值需要训练的来。
发展历史:
单层感知机------>多层感知机-------->神经网络
感知机:
在感知机当中,没有所谓的隐藏层,只有输入和输出两层,输入层只负责传输数据,不做计算,输出层的输出单元对前一层的进行计算。
结构图:

如果说输出的不是一个值了,而是一个向量,那么这个时候就在增加一个z2,那么输出就会变成一个向量。
a就是输入的矩阵向量,z是输出向量,g是一个符号函数,输出是0,1。
但是它有一个很不好的点,就是连简单的异或问题都解决不了。
多层感知机:
在原本单层感知机的基础上加上了一层计算层,两层的计算网络不仅可以解决异或问题,而且对于非线性的分类问题也有很好的解决效果,不过如果是两层的神经网络在当时计算又是一个大问题,没有一个很好的解决办法。
接着出现了BP算法,解决了两层计算网络计算困难的问题。
结构:

两层的网络结构,除了包含一个输入层和一个输出层,还包括一个中间层,此时中间层和输出层都是我们的计算层。

输入是第一层的a,通过和权重的计算得到,第一层的a,然后再通过和第二层的权重的计算,得到最终的输出结果z。如果说输出的是一个向量,那么增加输出的节点即可。
到现在为止,始终没有提到偏执b,其实偏执b一直都是默认存在的。
除了输出层,在神经网络的每个层中都是存在的。

在多层的神经网络当中的激活函数g,就不再是符号函数了,就成了sigmoid激活函数。
在设计一个神经网络时,输入层的节点数需要与特征的维度匹配,输出层的节点数要与目标的维度匹配。而中间层的节点数,是由自己指定的。但是,节点数设置的多少,却会影响到整个模型的效果。一般先设定几个值,然后通过网格搜索来寻找最优的中间层节点个数。
训练:
一开始神经网络都不知道怎么训练,导致它并没有很大的发展,然后随着数据量的逐步的增大,更多优化算法的提出,神经网络的又是渐渐展现了出来。
机器学习模型训练的目的,就是使得参数尽可能的与真实的模型逼近。具体做法是这样的。首先给所有参数赋上随机值。我们使用这些随机生成的参数值,来预测训练数据中的样本。样本的预测目标为h,真实目标为y。那么,定义一个值loss,计算公式如下。
loss = (h - y)2
这个值称之为损失(loss),我们的目标就是使对所有训练数据的损失和尽可能的小。
如果将先前的神经网络预测的矩阵公式带入到h中(因为有z=h),那么我们可以把损失写为关于参数的函数,这个函数称之为损失函数(loss function)。下面的问题就是求:如何优化参数,能够让损失函数的值最小。
此时这个问题就被转化为一个优化问题。一个常用方法就是高等数学中的求导,但是这里的问题由于参数不止一个,求导后计算导数等于0的运算量很大,所以一般来说解决这个优化问题使用的是梯度下降算法。
梯度下降算法每次计算参数在当前的梯度,然后让参数向着梯度的反方向前进一段距离,不断重复,直到梯度接近零时截止。一般这个时候,所有的参数恰好达到使损失函数达到一个最低值的状态。
在神经网络模型中,由于结构复杂,每次计算梯度的代价很大。因此还需要使用反向传播算法。反向传播算法是利用了神经网络的结构进行的计算。它并不一次计算所有参数的梯度,而是从后往前。首先计算输出层的梯度,然后是第二个参数矩阵的梯度,接着是中间层的梯度,再然后是第一个参数矩阵的梯度,最后是输入层的梯度。计算结束以后,所要的两个参数矩阵的梯度就都有了。
反向传播算法就是将梯度计算从后往前,一点一点,一层一层的向前传播。

影响:
当然是由好处的,比如在自动驾驶,语音和图像上,但是仍然后很大问题,比如训练太耗时,容易局部最优,难以调参等,很快被SVM比下去了。
“深度信念网络”的概念。与传统的训练方式不同,“深度信念网络”有一个“预训练”(pre-training)的过程,这可以方便的让神经网络中的权值找到一个接近最优解的值,之后再使用“微调”(fine-tuning)技术来对整个网络进行优化训练。这两个技术的运用大幅度减少了训练多层神经网络的时间。他给多层神经网络相关的学习方法赋予了一个新名词--“深度学习”。
结构:

就是在原来两层的基础上,在原本输出层的后边又接了一层,
g(W(1) * a(1)) = a(2);
g(W(2) * a(2)) = a(3);
g(W(3) * a(3)) = z;
多层神经网络这样一层一层的往前计算,我们叫做正向传播。
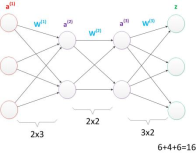


通过上边三张图,充分的表示如果说神经元稍微多一点的话,一样的参数量可以获得到更深层次的表达。
与两层神经网络相对比,其实深层的神经网络相比它多了更多的层。
深层网络的好处?
会有更深入的表示特征,以及更强的函数模拟的能力。随着网络层数的增加,每一层所提取的特征又都不一样,那么这样就会抽取到更多更详细更深入的信息。例如:第一层学到一些边缘特征,第二层学到一些形状,第三层学到目标等等。从而更好的去区分,获得更强的分类能力。
在单层神经网络时,我们使用的激活函数是sgn函数。到了两层神经网络时,我们使用的最多的是sigmoid函数。而到了多层神经网络时,通过一系列的研究发现,ReLU函数在训练多层神经网络时,更容易收敛,并且预测性能更好。因此,目前在深度学习中,最流行的非线性函数是ReLU函数。
在深度学习中,泛化技术变的比以往更加的重要。这主要是因为神经网络的层数增加了,参数也增加了,表示能力大幅度增强,很容易出现过拟合现象。因此正则化技术就显得十分重要。目前,Dropout技术,以及数据扩容(Data-Augmentation)技术是目前使用的最多的正则化技术。
同时深度学习的成功也不仅仅是各种优化算法的提升或者更好的激活函数等等。
外因:

希望这篇文章能够帮助到你!!!!!
边栏推荐
- The GNU Privacy Guard
- 借问变量何处存,牧童笑称用指针,Go lang1.18入门精炼教程,由白丁入鸿儒,go lang类型指针(Pointer)的使用EP05
- 今天做了手机播放器的均衡器
- 关于页面初始化
- 第二周作业
- EndNote User Guide
- 踩坑scrollIntoView
- 浏览器的报错分类
- Quick sort eight sorts (3) 】 【 (dynamic figure deduction Hoare, digging holes, front and rear pointer method)
- 3D printed this DuPont cable management artifact, and the desktop is no longer messy
猜你喜欢


![[Machine Learning] Detailed explanation of web crawler combat](/img/ac/f00f0c81e66ba526ac39ee60fad72b.png)
随机推荐
[ASM] Bytecode operation MethodVisitor case combat generation object
【MySQL】mysql因为字符集导致left join出现Using join buffer (Block Nested Loop)
《刷题日记》2
1003 我要通过! (20 分)
Throwing a question? The execution speed of the Count operation in the Mysql environment is very slow. You need to manually add an index to the primary key---MySql optimization 001
[项目配置] 配置Qt函数库和ui界面库的封装并调用的项目
实验室装修及改造工程程序简介
Arrays.toString( )打印二维数组
程序员的专属浪漫——用3D Engine 5分钟实现烟花绽放效果
排序1:冒泡排序
Nodejs服务端
壁纸
1: bubble sort
常用语言图表库总结
antd表单
虚拟列表key复用问题
多线程案例——定时器
MySQL全文索引
编程技术提升
学习NET-SNMP之二-----------VisualStudio编译Net-SNMP