当前位置:网站首页>Where does detection go forward?
Where does detection go forward?
2022-08-09 08:31:00 【CapricornGuang】
Introduction
"Where the deep learning goes forward?" It's a universally common problem for every one exploring neural networks, no matter a green hand or who has dived into it for a long time. After years of development, numerous state-of-the-art models have been integrated with a large number of techniques, and the recipe to their success begins to blur out. And thus, it's necessary to stand on to the highway of the history and pick out the shining golds. Along this line, this article summarizes my recent discoveries on visual object detection.

Figure 1. An illustration of visual object detection.
Remark1
This blog merely refers my recent views and summaries towards visual detection, and mainly focuses on anchor-based series models, the tremendous mainstream of recent 10 years.
Philosophy
The early time's object detection (before 2000) did not follow a unified detection philosophy like sliding window detection. Detectors at that time were usually designed based on delicate designed model with dark prior knowledge and assumption. Such exploration continues until the RCNN comes out in 2014. The development in deep learning era lasting a decade aims to build up an end-to-end pipeline for visual object detection.
The proposal of a series of RCNN-based models (RCNN, SPPNet, Fast RCNN, Faster RCNN) fosters several general network components, including region proposal, proposal detection, feature extraction, bounding box regression. And their similarities are summarized as follow:
Remark2
RCNN-based methods mostly follow the philosophy of "proposal detection+verification". And their differences or we said their improvements lie in the way they generate candicate region and the way they conduct verfication.
Figure 2. An illustration of candicate region and class verification. a. The bounding box (BB) in the panel is what we called candicate region. And we need to filter out the most accurate BB as our localization of objects. b. A classification network will be employed to conduct the object detection.

Fig. 2 illustrates how modern convolution networks handle the object detection problem, where these methods adopt the region proposal or bounding box regression to localize the object, and a sibling brance is applied for classification. It means that these methods enumerate possible regions within images and recognize the category of the objects. Translated, the localization of object is performed by enumeration.
Components
Personally, there are four indispensable compoents for object detection: feature extraction, proposal detection, classification and bounding box regression. And the Fig. 3 below basically illustrate all the components you need for object detection.
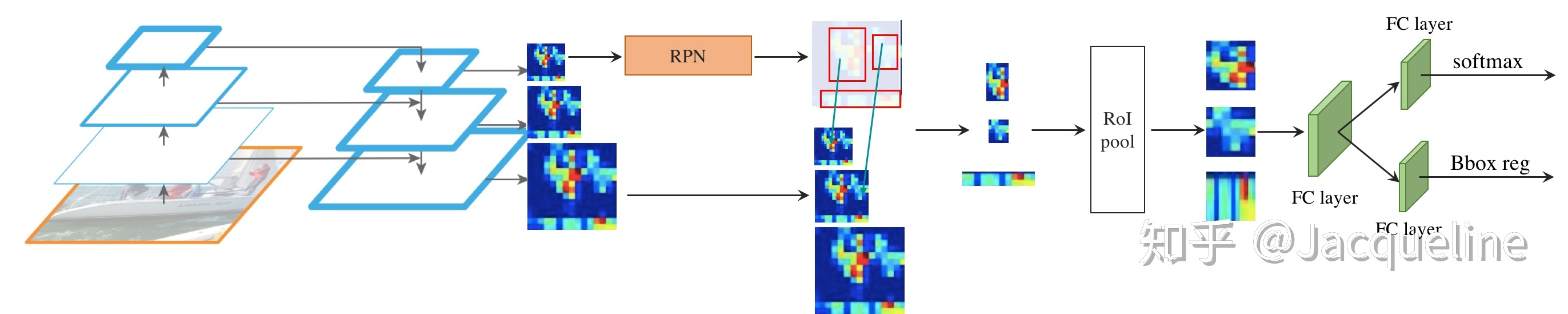
Figure 3. An overview of object detection components.a. The pyramid feature structure represents the feature extractor, which generates the feature map of the raw image. b.The RPN (region proposal network) represents the proposal detection c.The softmax and Bbox reg stands for the classification and bounding box regression, respectively.
feature extraction
The feature extraction is responsible for obtaining the feature map of the raw image, which filters out the environment elements such as illumination, reflection, etc. and reserves the category sensitive feature containing spatial information. Theoretically, common backbonds likeFPN, VGG, Alex, ViT, HourGlasscan all be taken as a feature extractor.proposal detection
(1) For anchor based methods, the vanilla way is to propose thoudsands of possible regions which might contain object within them. And then, the detection problem can be translated to a simple supervision problem of 0-1, 0 denotes no object and 1 denotes existing object.
(2) As the increase of GPU's computing power, an intuitive improvement that simply performing the deep regression to feature map is proposed (Yolov1). But the feature map where the localization of object is out of position and the small receptive filed of convolution undermine its performance.
(3) A more advanced line is adopted byFaster RCNN, SSD, which pre-define a set of reference boxes (a.k.a. anchor boxes) with different sizes and aspect-ratios at different locations of an image, and then predict the detection box based on these references.
With components mentioned above, you can establish your own object detection system, just like piling up the blocks. And if with no significant progress, their performance might converges to being the same.
Technical lines
In deep learning era, object detection can be grouped into two genres: "two-stage detection" and "one-stage detection", where the former frames the detection as a "coarse-to-fine" process while the later frames it as to "complete in one step".
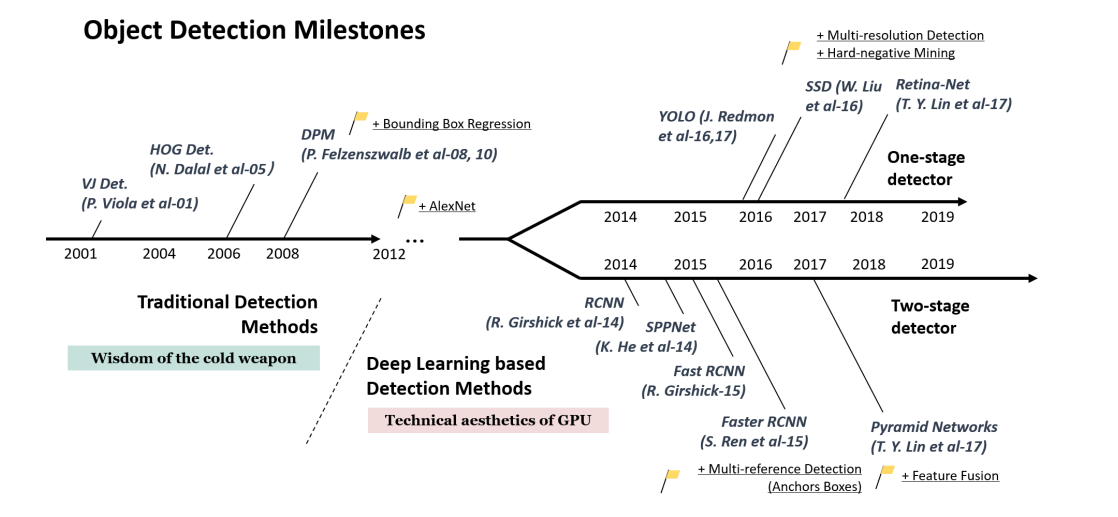 Figure 4. A road map of object detection.
Figure 4. A road map of object detection.
However, the one-stage detectors have trailed the accuracy of two-stage for years (2014~2017), until the RetinaNet is proposed. The designs of RetinaNet follows a simple thought that the extreme foreground-background class imbalance encountered during training of dense detectors is the central cause to the performance degration of one-stage detectors.
Remark3
In this perspective, the two-stage methods have the advantages of interputting the category imbalance, naturally. And numerous methods are introduced to solve the hard sample mining problem, which hinders the interfere of the negative samples that occupy nearly 95% of the training samples.
Conclusion
Although the object detection such as Yolo, SSD have achieved satisfactory performance in lab. setting, their still remains lots of challenges like the detection of small objects, inference speed and so on. And along any technical line, with the components introduced above, you can build your own network.
Nevertheless, some of the basic problems have not been solved yet, personally. Achieving localization with enumeration triggers an inefficient inference process and the bounding box regression mixs up the spatio and classification features. Although nowadays new advance try to alleviate these problems, but the ceils may not be higher without a substantil chaning from-bottom-to-up.
边栏推荐
猜你喜欢

随机推荐
OSI网络模型
数据解析之bs4学习
欧几里和游戏
交换机的工作原理
NAT地址转换的原理与配置
进程同步与互斥问题纠错
requests之防盗链学习
The principle and configuration of VLAN
requests爬取百度翻译
pip3 source change to improve speed
897. 增加订单搜索树
leetcode 36. 有效的数独(模拟题)
System Security and Application
数据库MySQL的安装和卸载
黑马2022最新redis课程笔记知识点(面试用)
【CNN】2022 ECCV Oral 自反馈学习的mixup训练框架AutoMix
【CNN】白话迁移学习中域适应
Redis(七) 主从复制(二)哨兵模式
网络层协议介绍
204. 数素数