当前位置:网站首页>浙大、阿里提出DictBERT,字典描述知识增强的预训练语言模型
浙大、阿里提出DictBERT,字典描述知识增强的预训练语言模型
2022-08-10 12:11:00 【夕小瑶】

文 | 刘聪NLP
源 | NLP工作站
 写在前面
写在前面
大家好,我是刘聪NLP。
今天给大家带来一篇IJCAI2022浙大和阿里联合出品的采用对比学习的字典描述知识增强的预训练语言模型-DictBERT,全名为《Dictionary Description Knowledge Enhanced Language Model Pre-training via Contrastive Learning》
paper地址:
https://arxiv.org/pdf/2208.00635.pdf
又鸽了许久,其实最近看到一些有趣的论文,大多以知乎想法的形式发了,感兴趣可以去看看,其实码字还是很不易的~

介绍
预训练语言模型(PLMs)目前在各种自然语言处理任务中均取得了优异的效果,并且部分研究学者将外部知识(知识图谱)融入预训练语言模型中后获取了更加优异的效果,但具体场景下的知识图谱信息往往是不容易获取的,因此,我们提出一种新方法DictBert,将字典描述信息作为外部知识增强预训练语言模型,相较于知识图谱的信息增强,字典描述更容易获取。
在预训练阶段,提出来两种新的预训练任务来训练DictBert模型,通过掩码语言模型任务和对比学习任务将字典知识注入到DictBert模型中,其中,掩码语言模型任务为字典中词条预测任务(Dictionary Entry Prediction);对比学习任务为字典中词条描述判断任务(Entry Description Discrimination)。
在微调阶段,我们将DictBert模型作为可插拔的外部知识库,对输入序列中所包含字典中的词条信息作为外部隐含知识内容,注入到输入中,并通过注意机制来增强输入的表示,最终提升模型表征效果。
模型
字典描述知识
字典是一种常见的资源,它列出了某一种语言所包含的字/词,并通过解释性描述对其进行含义的阐述,常常也会指定它们的发音、来源、用法、同义词、反义词等,如下表所示,

我们主要利用四种信息进行模型的预训练,包括:词条、描述、同义词和反义词。在词条预测任务中,利用字典的词条及其描述进行知识学习;在词条描述判断任务中,利用同义词和反义词来进行对比学习,从而学习到知识表征。
预训练任务
预训练任务主要包含字典中词条预测任务和字典中词条描述判断任务,如下图所示。

词条预测任务,实际上是一个掩码语言模型任务,给定词条和它对于的描述,然后将词条的内容使用特殊字符[MASK]进行替换,最终将其[MASK]内容进行还原。注意,当词条包含多个token时,需要将其全部掩掉。
词条描述判断任务,实际上是一个对比学习任务,而对比学习就是以拉近相似数据,推开不相似数据为目标,有效地学习数据表征。如下表所示,

对于词条“forest”,正例样本为同义词“woodland”,负例样本为反义词“desert”。对比学习中,分别对原始词条+描述、正例样本+描述和负例样本+描述进行模型编码,获取、和,获取对比学习损失,
402 Payment Required
最终,模型预训练的损失为
其中,为0.4,为0.6。
微调任务
在微调过程中,将DictBert模型作为可插拔的外部知识库,如下图所示,首先识别出输入序列中所包含字典中的词条信息,然后通过DictBert模型获取外部信息表征,再通过三种不同的方式进行外部知识的注入,最终将其综合表征进行下游具体的任务。并且由于可以事先离线对一个字典中所有词条进行外部信息表征获取,因此,在真实落地场景时并不会增加太多的额外耗时。

知识注入的方式包含三种:
Pooled Output Concatenation,即将所有词条的信息表征进行求和,然后与原始模型的进行拼接,最终进行下游任务;
Extra-hop Attention,即将所有词条的信息表征对进行attition操作,获取分布注意力后加权求和的外部信息表征,然后与原始模型的进行拼接,最终进行下游任务;
Layer-wise Extra-hop Attention,即将所有词条的信息表征对每一层的进行attition操作,获取每一层分布注意力后加权求和的外部信息表征,然后对其所有层进行mean-pooling操作,然后与原始模型的进行拼接,最终进行下游任务;
结果
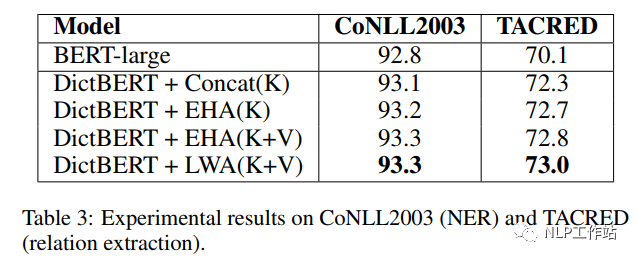
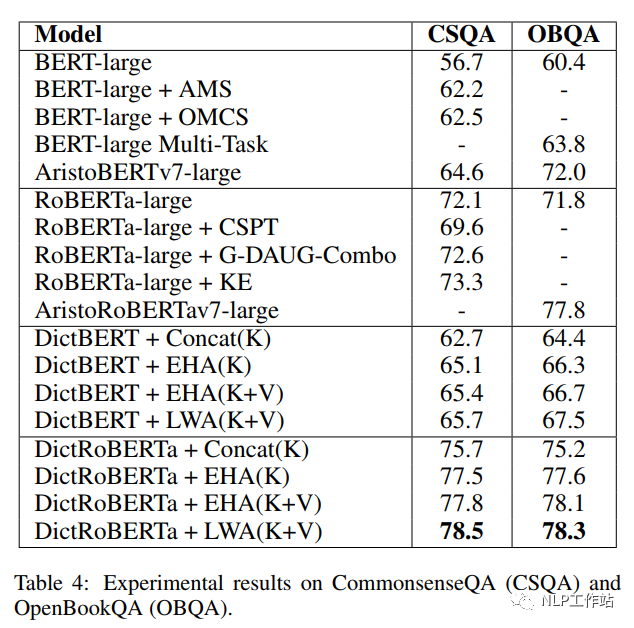
如下表所示,采用剑桥字典进行预训练后的DictBert模型,在CoNLL2003、TACRED、CommonsenseQA、OpenBookQA和GLUE上均有提高。其中,Concat表示Pooled Output Concatenation方式,EHA表示Extra-hop Attention,LWA表示Layer-wise Extra-hop Attention,K表示仅采用词条进行信息表征,K+V表示采用词条和描述进行信息表征。

总结
挺有意思的一篇论文吧,相较于知识图谱来说,字典确实较容易获取,并在不同领域中,也比较好通过爬虫的形式进行词条和描述的获取;并且由于字典的表征可以进行离线生成,所以对线上模型的耗时并不明显,主要在attention上。
后台回复关键词【入群】
加入卖萌屋NLP、CV、搜推广与求职讨论群
边栏推荐
- 自定义过滤器和拦截器实现ThreadLocal线程封闭
- 实践为主,理论为辅!腾讯大佬MySQL高阶宝典震撼来袭!
- 娄底农产品检验实验室建设指南盘点
- 燃炸!字节跳动成功上岸,只因刷爆LeetCode算法面试题
- The 6th "Blue Hat Cup" National College Student Network Security Skills Competition Semi-Final Part WriteUp
- So delicious!Since using this interface artifact, my team efficiency has increased by 60%!
- leetcode/两个链表的第一个重合节点
- three.js blur glass effect
- 日记16
- MySQL索引的B+树到底有多高?
猜你喜欢

IDC第一的背后,阿里云在打造怎样的一朵“视频云”?

Prada, big show?In the yuan in the universe that!

Chapter 5 virtual memory

G1和CMS的三色标记法及漏标问题

面试美团被问到了Redis,搞懂这几个问题,让你轻松吊打面试官

How to cultivate the design thinking of ui designers?
CV复习:空洞卷积

AICOCO AI Frontier Promotion (8.10)

Proprietary cloud ABC Stack, the real strength!

2022年8月中国数据库排行榜:openGauss重夺榜眼,PolarDB反超人大金仓
随机推荐
camshift实现目标跟踪
Solve the idea that unit tests cannot use Scanner
dedecms supports one-click import of Word content
【集合】HashSet和ArrayList的查找Contains()时间复杂度
IM即时通讯开发WebSocket从入门到精通
Guo Jingjing's personal chess teaching, the good guy is a robot
堪称神级的阿里巴巴“高并发”教程——基础+实战+源码+面试+架构 全包了
查看 CUDA cudnn 版本 & 测试 cuda 和 cudnn 有效性「建议收藏」
Proprietary cloud ABC Stack, the real strength!
Real-time data warehouse practice of Baidu user product flow and batch integration
wirshark 常用操作及 tcp 三次握手过程实例分析
search--01
CodeForces - 628D (digital dp)
Polygon zkEVM工具——PIL和CIRCOM
Educational Codeforces Round 41 (Rated for Div. 2) E. Tufurama
What are the five common data types of Redis?What is the corresponding data storage space?Take you to learn from scratch
浮动及其特点
【论文+代码】PEBAL/Pixel-wise Energy-biased Abstention Learning for Anomaly Segmentation on Complex Urban Driving Scenes(复杂城市驾驶场景异常分割的像素级能量偏置弃权学习)
娄底疾控中心实验室设计理念说明
How to cultivate the design thinking of ui designers?