当前位置:网站首页>【机器学习】数据科学基础——机器学习基础实践(二)
【机器学习】数据科学基础——机器学习基础实践(二)
2022-08-09 09:22:00 【云曦智划】
【机器学习】数据科学基础——机器学习基础实践(二)

活动地址:[CSDN21天学习挑战赛](https://marketing.csdn.net/p/bdabfb52c5d56532133df2adc1a728fd)
作者简介:在校大学生一枚,华为云享专家,阿里云星级博主,腾云先锋(TDP)成员,云曦智划项目总负责人,全国高等学校计算机教学与产业实践资源建设专家委员会(TIPCC)志愿者,以及编程爱好者,期待和大家一起学习,一起进步~
.
博客主页:ぃ灵彧が的学习日志
.
本文专栏:机器学习
.
专栏寄语:若你决定灿烂,山无遮,海无拦
.

文章目录
前言
什么是机器学习?
机器学习是人工智能领域内的一个重要分支,旨在通过计算的手段,利用经验来改善计算机系统的性能,通常,这里的经验即历史数据。从大量的数据中抽象出一个算法模型,然后将数据输入到模型中,得到模型对其的判断(例如类型、预测实数值等),也就是说,机器学习是一门主要研究学习算法的学科。
一、基于朴素贝叶斯实现文本分类
导读:
贝叶斯分类算法是以贝叶斯定理为基础的一系列分类算法,包含朴素贝叶斯算法与树增强型贝叶斯算法,朴素贝叶斯算法是最简单但是十分高效的贝叶斯分类算法,因为其假设输入特征之间相互独立,因此得名“朴素”。
模型选择:
贝叶斯分类: 贝叶斯分类是一类分类算法的总称,这类算法均以贝叶斯定理为基础,故统称为贝叶斯分类。
贝叶斯公式: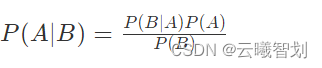
在**文本分类(classification)**问题中,我们要将一个句子分到某个类别,我们将句子中的词或字视为句子的属性,因此一个句子是由个属性(字/词)组成的,把众多属性看做一个向量,即X=(x1,x2,x3,…,xn),用X这个向量来代表这个句子。 类别也有很多种,我们用集合Y={y1,y2,…ym}表示。
一个句子属于yk类别的概率可以表示为:
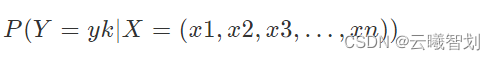
如果一个句子的属性向量X属于yk类别的概率最大,即:
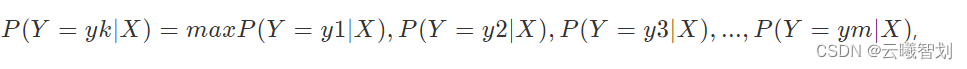
其中,X=(x1,x2,x3,…,xn),可以给X打上yk标签,意思是说X属于yk类别。这就是所谓的分类(Classification)。
朴素贝叶斯:
假设X=(x1,x2,x3,…,xn)中的所有属性都是独立的,即
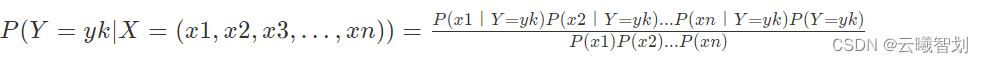
拉普拉斯平滑的引入:
如果某个属性的条件概率为0,则会导致整体概率为零,为了避免这种情况出现,引入拉普拉斯平滑参数,即将条件概率为0的属性的概率设定为固定值。
(一)、数据加载及预处理
- 导入相关包:
#导入必要的包
import random
import jieba # 处理中文
from sklearn import model_selection
from sklearn.naive_bayes import MultinomialNB
import re,string
- 加载文本,过滤其中的特殊字符
def text_to_words(file_path):
''' 分词 return:sentences_arr, lab_arr '''
sentences_arr = []
lab_arr = []
with open(file_path,'r',encoding='utf8') as f:
for line in f.readlines():
lab_arr.append(line.split('_!_')[1])
sentence = line.split('_!_')[-1].strip()
sentence = re.sub("[\s+\.\!\/_,$%^*(+\"\')]+|[+——()?【】“”!,。?、[email protected]#¥%……&*()《》:]+", "",sentence) #去除标点符号
sentence = jieba.lcut(sentence, cut_all=False)
sentences_arr.append(sentence)
return sentences_arr, lab_arr
- 加载停用词表,对文本词频进行统计,过滤掉停用词及词频较低的词,构建词表:
def load_stopwords(file_path):
''' 创建停用词表 参数 file_path:停用词文本路径 return:停用词list '''
stopwords = [line.strip() for line in open(file_path, encoding='UTF-8').readlines()]
return stopwords
def get_dict(sentences_arr,stopswords):
''' 遍历数据,去除停用词,统计词频 return: 生成词典 '''
word_dic = {
}
for sentence in sentences_arr:
for word in sentence:
if word != ' ' and word.isalpha():
if word not in stopswords:
word_dic[word] = word_dic.get(word,1) + 1
word_dic=sorted(word_dic.items(),key=lambda x:x[1],reverse=True) #按词频序排列
return word_dic
- 从词典中选取N个特征词,形成特征词列表。
def get_feature_words(word_dic,word_num):
''' 从词典中选取N个特征词,形成特征词列表 return: 特征词列表 '''
n = 0
feature_words = []
for word in word_dic:
if n < word_num:
feature_words.append(word[0])
n += 1
return feature_words
# 文本特征
def get_text_features(train_data_list, test_data_list, feature_words):
''' 根据特征词,将数据集中的句子转化为特征向量 '''
def text_features(text, feature_words):
text_words = set(text)
features = [1 if word in text_words else 0 for word in feature_words] # 形成特征向量
return features
train_feature_list = [text_features(text, feature_words) for text in train_data_list]
test_feature_list = [text_features(text, feature_words) for text in test_data_list]
return train_feature_list, test_feature_list
#获取分词后的数据及标签
sentences_arr, lab_arr = text_to_words('data/data6826/news_classify_data.txt')
#加载停用词
stopwords = load_stopwords('data/data43470/stopwords_cn.txt')
# 生成词典
word_dic = get_dict(sentences_arr,stopwords)
#数据集划分
train_data_list, test_data_list, train_class_list, test_class_list = model_selection.train_test_split(sentences_arr,
lab_arr,
test_size=0.1)
#生成特征词列表
feature_words = get_feature_words(word_dic,10000)
#生成特征向量
train_feature_list,test_feature_list = get_text_features(train_data_list,test_data_list,feature_words)
(二)、模型定义与训练
上述概率计算中,可能存在某一个单词在某个类型中从来没有出现过,即某个属性的条件概率为0(P(x|c)=0),此时会导致整体概率为零,为了避免这种情况出现,引入拉普拉斯平滑参数,将条件概率为0的属性的概率设定为固定值,具体的,对每个类型下所有单词的计数加1,当训练样本集数量充分大时,并不会对结果产生影响。下面调用接口的参数中,alpha为1时,表示使用拉普拉斯平滑方式,若设置为0,则不使用平滑;fit_prior代表是否学习先验概率P(Y=c),如果设置为False,则所有的样本类型输出都有相同的类别先验概率;class_prior为各类型的先验概率,如果没有给出具体的先验概率则自动根据数据来进行计算。
代码如下:
from sklearn.metrics import accuracy_score,classification_report
#获取朴素贝叶斯分类器
classifier = MultinomialNB(alpha=1.0, # 拉普拉斯平滑
fit_prior=True, #否要考虑先验概率
class_prior=None)
#进行训练
classifier.fit(train_feature_list, train_class_list)
(三)、模型训练
模型训练结束后,可使用验证集测试模型的性能,同上一小节,输出准确率的同时,对各个类型的精确率、召回率以及F1值也进行输出。
代码如下:
# 在验证集上进行验证
predict = classifier.predict(test_feature_list)
test_accuracy = accuracy_score(predict,test_class_list)
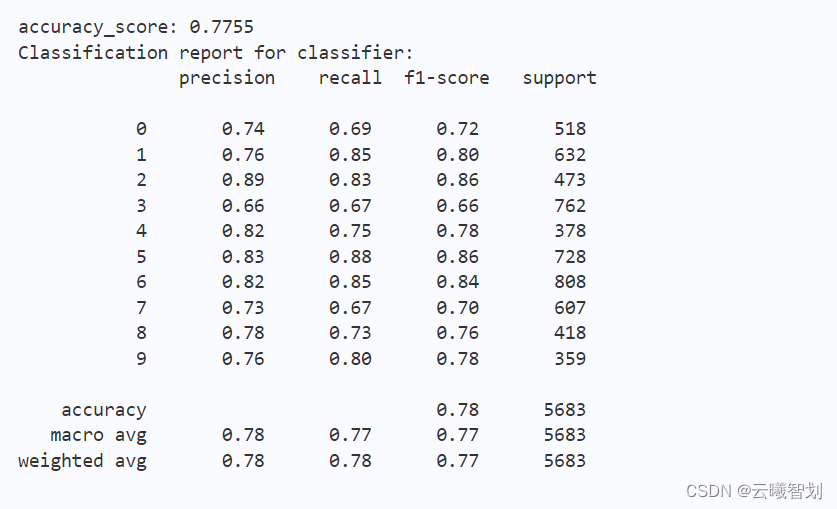
print("accuracy_score: %.4lf"%(test_accuracy))
print("Classification report for classifier:\n",classification_report(test_class_list, predict))
输出结果如下图1-1所示:
(四)、模型预测
使用上述训练好的模型,对任意给定的文本数据,可进行预测,观察模型的泛化性能。
代码如下:
#加载句子,对句子进行预处理
def load_sentence(sentence):
sentence = re.sub("[\s+\.\!\/_,$%^*(+\"\')]+|[+——()?【】“”!,。?、[email protected]#¥%……&*()《》:]+", "",sentence) #去除标点符号
sentence = jieba.lcut(sentence, cut_all=False)
return sentence
lab = [ '文化', '娱乐', '体育', '财经','房产', '汽车', '教育', '科技', '国际', '证券']
p_data = '【中国稳健前行】应对风险挑战必须发挥制度优势'
sentence = load_sentence(p_data)
sentence= [sentence]
print('分词结果:', sentence)
#形成特征向量
p_words = get_text_features(sentence,sentence,feature_words)
res = classifier.predict(p_words[0])
print("所属类型:",lab[int(res)])
文本预测结果如下图1-2所示:

二、基于支持向量积实现鸾尾花分类
导读:
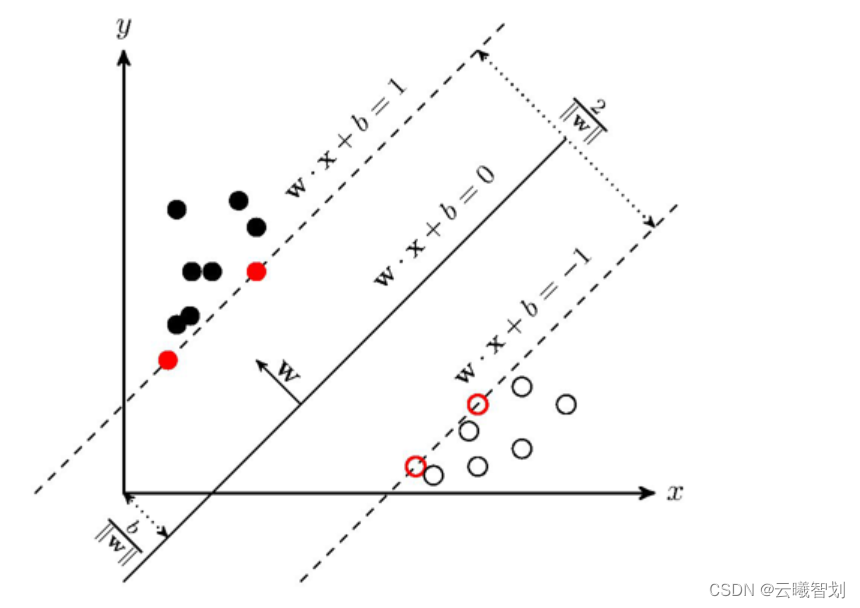
支持向量机(SVM)是机器学习中经典的分类算法,主要思想为最大化不同类型的样本到分类超平面之间的距离和。
对于SVM,存在一个分类面,两个点集到此平面的最小距离最大,两个点集中的边缘点到此平面的距离最大。
(一)、数据加载及预处理
- 导入相关包:
import numpy as np
from matplotlib import colors
from sklearn import svm
from sklearn import model_selection
import matplotlib.pyplot as plt
import matplotlib as mpl
- 加载数据、切分数据集:
# ======将字符串转化为整形==============
def iris_type(s):
it = {
b'Iris-setosa':0, b'Iris-versicolor':1,b'Iris-virginica':2}
return it[s]
# 1 数据准备
# 1.1 加载数据
data = np.loadtxt('/home/aistudio/data/data2301/iris.data', # 数据文件路径i
dtype=float, # 数据类型
delimiter=',', # 数据分割符
converters={
4:iris_type}) # 将第五列使用函数iris_type进行转换
# 1.2 数据分割
x, y = np.split(data, (4, ), axis=1) # 数据分组 第五列开始往后为y 代表纵向分割按列分割
x = x[:, :2]
x_train, x_test, y_train, y_test=model_selection.train_test_split(x, y, random_state=1, test_size=0.2)
print(x.shape,x_train.shape,x_test.shape)
(二)、模型配置
sklearn.svm.SVC()函数提供多个可配置参数,其中,C为错误项的惩罚系数。C越大,对训练集错误项的惩罚越大。模型在训练集上的准确率越高,越容易过拟合。C越小,越允许训练样本中有一些误分类错误样本,泛化能力强。
对于训练样本带有噪声的情况,一般采用较小的C,把训练样本集中错误分类的样本作为噪声;Kernel为采用的核函数,默认为线性核,可选的为一对多分类决策函数:
linear/poly/rbf/sigmoid/precomputed,decision_function_shape为ovr
# SVM分类器构建
def classifier():
clf = svm.SVC(C=0.8, # 误差项惩罚系数
kernel='linear', # 线性核 高斯核 rbf
decision_function_shape='ovr') # 决策函数
return clf
# 训练模型
def train(clf, x_train, y_train):
clf.fit(x_train, y_train.ravel()) # 训练集特征向量和 训练集目标值
# 2 定义模型 SVM模型定义
clf = classifier()
# 3 训练模型
train(clf, x_train, y_train)
(三)、模型训练
在划分好的测试集上测试模型的准确率,使用两种方法计算模型预测结果的准确率:自定义方法show_accuracy()以及sklearn中机器学习模型封装好的方法socre(),验证两者的一致性,并且输出样本x到各个决策超平面的距离,选择正的最大值对应的类型作为分类结果。
# ======判断a,b是否相等计算acc的均值
def show_accuracy(a, b, tip):
acc = a.ravel() == b.ravel()
print('%s Accuracy:%.3f' %(tip, np.mean(acc)))
# 分别打印训练集和测试集的准确率 score(x_train, y_train)表示输出 x_train,y_train在模型上的准确率
def print_accuracy(clf, x_train, y_train, x_test, y_test):
print('training prediction:%.3f' %(clf.score(x_train, y_train)))
print('test data prediction:%.3f' %(clf.score(x_test, y_test)))
# 原始结果和预测结果进行对比 predict() 表示对x_train样本进行预测,返回样本类别
show_accuracy(clf.predict(x_train), y_train, 'traing data')
show_accuracy(clf.predict(x_test), y_test, 'testing data')
# 计算决策函数的值 表示x到各个分割平面的距离
print('decision_function:\n', clf.decision_function(x_train)[:2])
(四)、模型可视化展示
若要绘制各个类型对应的空间区域,需要采集大量的样本点,但是本数据集仅包含150条数据,绘制的区域不太精细,因此,需要生成大规模的样本数据,根据生成的数据进行分类区域的绘制。
def draw(clf, x):
iris_feature = 'sepal length', 'sepal width', 'petal length', 'petal width'
# 开始画图
x1_min, x1_max = x[:, 0].min(), x[:, 0].max()
x2_min, x2_max = x[:, 1].min(), x[:, 1].max()
# 生成网格采样点
x1, x2 = np.mgrid[x1_min:x1_max:200j, x2_min:x2_max:200j]
grid_test = np.stack((x1.flat, x2.flat), axis = 1)
print('grid_test:\n', grid_test[:2])
# 输出样本到决策面的距离
z = clf.decision_function(grid_test)
print('the distance to decision plane:\n', z[:2])
grid_hat = clf.predict(grid_test)
# 预测分类值 得到[0, 0, ..., 2, 2]
print('grid_hat:\n', grid_hat[:2])
# 使得grid_hat 和 x1 形状一致
grid_hat = grid_hat.reshape(x1.shape)
cm_light = mpl.colors.ListedColormap(['#A0FFA0', '#FFA0A0', '#A0A0FF'])
cm_dark = mpl.colors.ListedColormap(['g', 'b', 'r'])
plt.pcolormesh(x1, x2, grid_hat, cmap = cm_light) # 能够直观表现出分类边界
plt.scatter(x[:, 0], x[:, 1], c=np.squeeze(y), edgecolor='k', s=50, cmap=cm_dark )
plt.scatter(x_test[:, 0], x_test[:, 1], s=120, facecolor='none',zorder=10)
plt.xlabel(iris_feature[0], fontsize=20) # 注意单词的拼写label
plt.ylabel(iris_feature[1], fontsize=20)
plt.xlim(x1_min, x1_max)
plt.ylim(x2_min, x2_max)
plt.title('Iris data classification via SVM', fontsize=30)
plt.grid()
plt.show()
# 4 模型评估
print('-------- eval ----------')
print_accuracy(clf, x_train, y_train, x_test, y_test)
# 5 模型使用
print('-------- show ----------')
draw(clf, x)
三、基于K-means实现鸾尾花聚类
导读:
K-means是一种经典的无监督聚类算法,对于给定的样本集,按照样本之间的距离大小,将样本集划分为K个簇,让簇内的点尽量紧密地连在一起,而让簇间的距离尽量大。
(一)、数据加载及预处理
- 导入相关包
import matplotlib.pyplot as plt
import numpy as np
from sklearn.cluster import KMeans
from sklearn import datasets
- 直接从sklearn.datasets中加载数据集
# 直接从sklearn中获取数据集
iris = datasets.load_iris()
X = iris.data[:, :4] # 表示我们取特征空间中的4个维度
print(X.shape)
- 绘制二维数据分布图
# 取前两个维度(萼片长度、萼片宽度),绘制数据分布图
plt.scatter(X[:, 0], X[:, 1], c="red", marker='o', label='see')
plt.xlabel('sepal length')
plt.ylabel('sepal width')
plt.legend(loc=2)
plt.show()
(二)、模型配置
实例化K-means类,并且定义训练函数
def Model(n_clusters):
estimator = KMeans(n_clusters=n_clusters)# 构造聚类器
return estimator
def train(estimator):
estimator.fit(X) # 聚类
(三)、模型训练
训练
# 初始化实例,并开启训练拟合
estimator=Model(3)
train(estimator)
(四)、模型可视化展示
label_pred = estimator.labels_ # 获取聚类标签
# 绘制k-means结果
x0 = X[label_pred == 0]
x1 = X[label_pred == 1]
x2 = X[label_pred == 2]
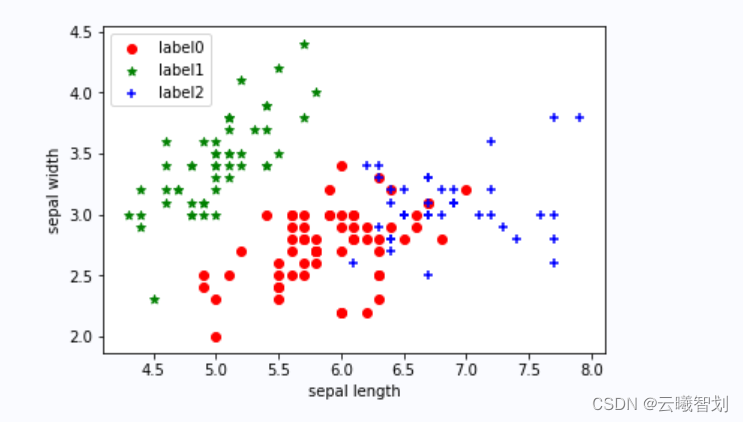
plt.scatter(x0[:, 0], x0[:, 1], c="red", marker='o', label='label0')
plt.scatter(x1[:, 0], x1[:, 1], c="green", marker='*', label='label1')
plt.scatter(x2[:, 0], x2[:, 1], c="blue", marker='+', label='label2')
plt.xlabel('sepal length')
plt.ylabel('sepal width')
plt.legend(loc=2)
plt.show()
输出结果如图3-1所示:
# 法一:直接手写实现
# 欧氏距离计算
def distEclud(x,y):
return np.sqrt(np.sum((x-y)**2)) # 计算欧氏距离
# 为给定数据集构建一个包含K个随机质心centroids的集合
def randCent(dataSet,k):
m,n = dataSet.shape #m=150,n=4
centroids = np.zeros((k,n)) #4*4
for i in range(k): # 执行四次
index = int(np.random.uniform(0,m)) # 产生0到150的随机数(在数据集中随机挑一个向量做为质心的初值)
centroids[i,:] = dataSet[index,:] #把对应行的四个维度传给质心的集合
return centroids
# k均值聚类算法
def KMeans(dataSet,k):
m = np.shape(dataSet)[0] #行数150
# 第一列存每个样本属于哪一簇(四个簇)
# 第二列存每个样本的到簇的中心点的误差
clusterAssment = np.mat(np.zeros((m,2)))# .mat()创建150*2的矩阵
clusterChange = True
# 1.初始化质心centroids
centroids = randCent(dataSet,k)#4*4
while clusterChange:
# 样本所属簇不再更新时停止迭代
clusterChange = False
# 遍历所有的样本(行数150)
for i in range(m):
minDist = 100000.0
minIndex = -1
# 遍历所有的质心
#2.找出最近的质心
for j in range(k):
# 计算该样本到4个质心的欧式距离,找到距离最近的那个质心minIndex
distance = distEclud(centroids[j,:],dataSet[i,:])
if distance < minDist:
minDist = distance
minIndex = j
# 3.更新该行样本所属的簇
if clusterAssment[i,0] != minIndex:
clusterChange = True
clusterAssment[i,:] = minIndex,minDist**2
#4.更新质心
for j in range(k):
# np.nonzero(x)返回值不为零的元素的下标,它的返回值是一个长度为x.ndim(x的轴数)的元组
# 元组的每个元素都是一个整数数组,其值为非零元素的下标在对应轴上的值。
# 矩阵名.A 代表将 矩阵转化为array数组类型
# 这里取矩阵clusterAssment所有行的第一列,转为一个array数组,与j(簇类标签值)比较,返回true or false
# 通过np.nonzero产生一个array,其中是对应簇类所有的点的下标值(x个)
# 再用这些下标值求出dataSet数据集中的对应行,保存为pointsInCluster(x*4)
pointsInCluster = dataSet[np.nonzero(clusterAssment[:,0].A == j)[0]] # 获取对应簇类所有的点(x*4)
centroids[j,:] = np.mean(pointsInCluster,axis=0) # 求均值,产生新的质心
# axis=0,那么输出是1行4列,求的是pointsInCluster每一列的平均值,即axis是几,那就表明哪一维度被压缩成1
print("cluster complete")
return centroids,clusterAssment
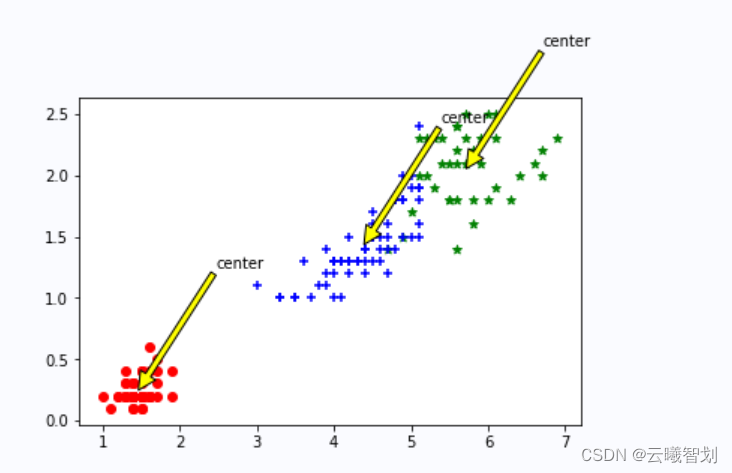
def draw(data,center,assment):
length=len(center)
fig=plt.figure
data1=data[np.nonzero(assment[:,0].A == 0)[0]]
data2=data[np.nonzero(assment[:,0].A == 1)[0]]
data3=data[np.nonzero(assment[:,0].A == 2)[0]]
# 选取前两个维度绘制原始数据的散点图
plt.scatter(data1[:,0],data1[:,1],c="red",marker='o',label='label0')
plt.scatter(data2[:,0],data2[:,1],c="green", marker='*', label='label1')
plt.scatter(data3[:,0],data3[:,1],c="blue", marker='+', label='label2')
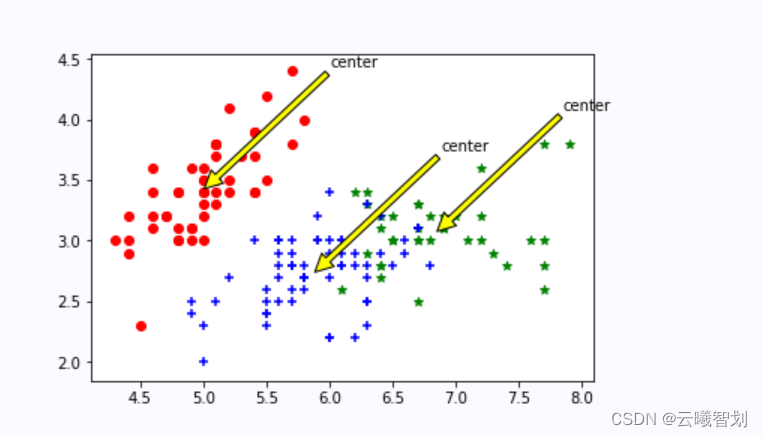
# 绘制簇的质心点
for i in range(length):
plt.annotate('center',xy=(center[i,0],center[i,1]),xytext=\
(center[i,0]+1,center[i,1]+1),arrowprops=dict(facecolor='yellow'))
# plt.annotate('center',xy=(center[i,0],center[i,1]),xytext=\
# (center[i,0]+1,center[i,1]+1),arrowprops=dict(facecolor='red'))
plt.show()
# 选取后两个维度绘制原始数据的散点图
plt.scatter(data1[:,2],data1[:,3],c="red",marker='o',label='label0')
plt.scatter(data2[:,2],data2[:,3],c="green", marker='*', label='label1')
plt.scatter(data3[:,2],data3[:,3],c="blue", marker='+', label='label2')
# 绘制簇的质心点
for i in range(length):
plt.annotate('center',xy=(center[i,2],center[i,3]),xytext=\
(center[i,2]+1,center[i,3]+1),arrowprops=dict(facecolor='yellow'))
plt.show()
dataSet = X
k = 3
centroids,clusterAssment = KMeans(dataSet,k)
draw(dataSet,centroids,clusterAssment)
输出结果如图3-2、3-3所示:
总结
本系列文章内容为根据清华社初版的《机器学习实践》所作的相关笔记和感悟,其中代码均为基于百度飞浆开发,若有任何侵权和不妥之处,请私信于我,定积极配合处理,看到必回!!!
最后,引用本次活动的一句话,来作为文章的结语~( ̄▽ ̄~)~:
【学习的最大理由是想摆脱平庸,早一天就多一份人生的精彩;迟一天就多一天平庸的困扰。】

边栏推荐
- 可以写进简历的软件测试项目实战经验(包含电商、银行、app等)
- 真·鸡汤文
- 用户设备IP三者绑定自动上号
- JS报错-Uncaught TypeError: 'caller', 'callee', and 'arguments' properties may not be accessed on...
- The era of Google Maps is over, how to view high-definition satellite image maps?
- 米斗APP逆向分析
- Another implementation of lateral view explode
- 接口测试主要测试哪方面?需要哪些技能?要怎么学习?
- 【面试体系知识点总结】---JVM
- Redis高可用
猜你喜欢





随机推荐
学习双向链表的心得与总结
接口性能测试方案设计方法有哪些?要怎么去写?
运行flutter项目时遇到的问题
奥维地图电脑端手机端不能用了,有没有可替代的地图工具
手机APP测试流程规范和方法你知道多少?
国产谷歌地球,地形分析秒杀同款地图软件
Anti App so层对抗分析
What are the basic concepts of performance testing?What knowledge do you need to master to perform performance testing?
Onnx - environment build 】 【 tensorrt
迭代
MySQL event_single event_timed loop event
GBase数据库中,源为 oracle 报出“ORA-01000:超出打开游标最大数”
【环境搭建】onnx-tensorrt
What does the test plan include?What is the purpose and meaning?
HD Satellite Map Browser
按字节方式和字符方式读取文件_加载配置文件
列表
软件测试面试中,面试官问你一些比较“刁难”的问题你会怎么回答
通用的测试用例编写大全(登录测试/web测试等)
第四讲 SVN