当前位置:网站首页>[NLP notes] preliminary study on CRF principle
[NLP notes] preliminary study on CRF principle
2022-04-23 07:54:00 【Apple Laboratory of Central South University】
Write it at the front : I just got started NLP Three months , I hope to consolidate my knowledge by recording blogs , Improve the understanding of knowledge .
I'm tagging the sequence (sequence tagging) When learning about , First came into contact with two classic statistical learning methods : One is HMM( hidden Markov model ), One is CRF( Conditional random field ). In the CRF Related articles , The findings fall into two broad categories : A class of hard core parsing , Starting from the formula ; One kind of value concept , From the principle . Many blog posts are well written , But I think , understand CRF, Mathematics and concepts should be paid attention to , To be effective . I hope this superficial article can help beginners like me NLPer Clear away some doubts .
One 、 Sequence annotation Sequence tagging
understand CRF Before , Let's start with sequence labeling .
Sequence labeling problem is NLP Basic problems in , Simply put, it is to mark or label a sequence . Many classic NLP Mission , Like part of speech tagging 、 participle 、 Named entity recognition 、 Pinyin input method, etc , In essence, it is the tag prediction of the elements in the sentence . Sequence annotation is also a lot of higher-level NLP The precursor of the task , Because I recently did a word segmentation task , So let's briefly explain the common annotation methods , It is convenient for readers to read later :
- BIO mark :B-Beginning The beginning of a word ;I-Inside In one word ;O-Outside Independent word .( Common in named entity recognition ,B-Name And so on )
- BMES mark :B-Begin The beginning of a word ;E-End The end of a word ;M-Middle The middle of a word ;S-Single Independent word .( Often used in Chinese word segmentation )
- BIOES mark : and 1、2 The Chinese letters have the same meaning .
Next , Let's see CRF Well !
Two 、 Why CRF?
Let's start with a personal conclusion :CRF Can learn more information in the training corpus , Characterize more features .
I've seen a very interesting example , The original text is here , The translator is here , Maybe the idea is , You have a set of pictures on hand , The sequence of pictures shows a person's life in a day . Now? , You need to label this group of pictures , Note what the person is doing , What would you do ?
Generally speaking , We'll look at it one by one , Sometimes you need to use the front and back photos for reasoning . Because this group of pictures has a temporal and spatial order , If the last picture is eating, the next picture can't be cooking .
CRF So is the core idea of , By learning the characteristics between a certain time and adjacent time , To get better prediction results . In fact, if you have friends who know neural networks before , I'll think of it when I see here LSTM Model bar. ?LSTM The model is also very suitable for solving the problem of sequence type , therefore , Image model Bi-LSTM After the meeting CRF Layer to get richer feature information between tags .
To show CRF Stronger learning ability of training data in word segmentation , Show an example ( take HMM The comparison ):
For sentences that appear in the training data (BMES mark ): [ by /S Ben /S single /B position /E clothing /B service /E Of /S The earth /B earthquake /E prison /B measuring /E platform /B network /E]
The corresponding word segmentation result should be : [‘ by ’, ‘ Ben ’, ‘ Company ’, ‘ service ’, ‘ Of ’, ‘ The earthquake ’, ‘ monitoring ’, ‘ Network ’]
HMM Predicted results :

CRF Predicted results :

It can be seen that ,CRF When encountering a sequence that appears in the training data , It can reflect the information learned by itself and mark it , For the hidden information provided by training data, the representation ability is stronger .
Next , Let's learn more about CRF The nature and difference of .
3、 ... and 、 Discriminant (Discriminative) Model and generative (Generative) Model
These two concepts are often easy to encounter , It's also the basic knowledge that I think can't be confused .
First put an intuitive picture :
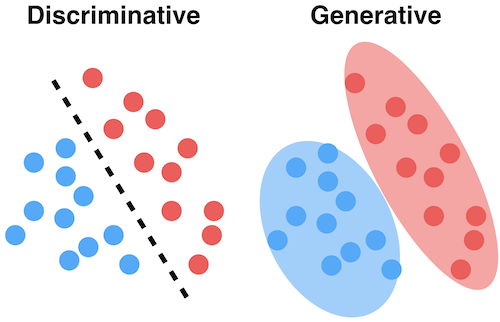
-
What is a discriminant ?
seeing the name of a thing one thinks of its function , The discriminant is , according to xx Judge xx. For input X, Prediction marks Y, That's conditional probability P(Y|X). So in my understanding , Discriminant is actually a boundary condition learned in training , Or split surface , For model input , It can be classified directly by this criterion . Like the left half of the picture above , In fact, what we get is the difference between the two categories , Therefore, discriminant has a very good performance in classification and prediction tasks .
-
What is generative ?
seeing the name of a thing one thinks of its function , The generative expression is , Generate multiple types of training data according to the training data “ Model ”, Instead of learning the boundaries between categories like discriminant . therefore , This method calculates a joint probability P(X,Y), For input X, Calculate multiple joint probabilities , Take the largest as the most likely case . As shown on the right in the above figure , The generator will learn the complete boundary of the whole class , Instead of just focusing on the relationship between classes .
-
Take a chestnut
Now I have Coca Cola and Pepsi in my training data , Then I input a picture containing a can into the trained machine .
If it's a discriminant model : First extract the feature information from the picture , The discriminant model uses some significant distinguishing features ( Color 、LOGO wait ), We can directly give the probability of Coca Cola and the probability of Pepsi .
If it's a generative model : First extract the feature information from the picture , When I passed the training, I had established a good model for Coca Cola and Pepsi , Incoming features are calculated one by one , Finally, the one with the highest probability is the predicted type .
-
and CRF What does it matter ?
HMM It's a generative model ,CRF It's a discriminant model . Why? ? because HMM The training process is to establish a statistical probability density model for all samples , This model is through HMM The transfer matrix and emission matrix are realized . and CRF Different ,CRF The calculation is conditional probability , Directly model the classification rules obtained from the training data , For example, the relationship between the front and back data and the current position .CRF More attention is paid to learning the characteristics of the sequence through the characteristic function , And the constraints in the sequence . That's why CRF There will be no Second point in HMM What happened , because HMM Only a probability estimate is made for one word and what its next word is , I didn't really pay attention to the front and back features in the whole sentence .
in fact , There is a certain transformation relationship between discriminant model and generative model . Logically, it can be understood as , Generative model after modeling various types , In fact, we also get the boundary of each model , It provides the prerequisite for transforming into discriminant . Yes HMM Readers who know something can also think about a problem ,HMM And CRF Whether there is a certain transformation relationship ?
Four 、 From Markov to CRF
-
Random Airport
In a sample space , The value of each point is given according to a certain distribution .
-
Markov random Airport
Random Airport + Markov nature , That is, a position in the random field is only related to the value of its adjacent position , Independent of the value of non adjacent positions .
-
Conditional random field
Special Markov random field ,Y Satisfy Markov . There is also an observation value under each position in the random field X(observation), Essentially , Is given the observation value X Random field , There are... In this field X and Y Two random variables , And Y Satisfy Markov .
-
Linear chain element random field Linear-CRF
The most common CRF In the form of , Characteristic is X and Y All have the same structure , And satisfy Markov property , That is, a position in the random field is only related to the value of its adjacent position , Independent of the value of non adjacent positions .
Linear-CRF Sketch Map :
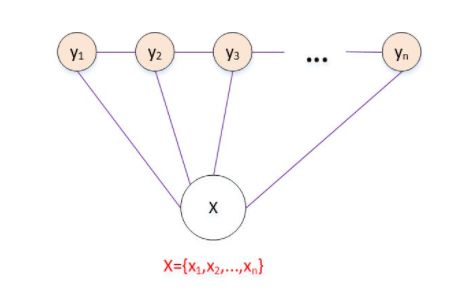
5、 ... and 、 Maximum entropy model and CRF
-
Maximum entropy MaxEnt
The maximum entropy model is not only applied to the sequence annotation task , The greatest thing about this model is , The characteristic function and its corresponding parameters are introduced to learn the overall characteristics of the input . The mathematical formula will not be brought up , In fact, on the whole, it is similar to CRF The final results are very similar .
Personal understanding , The introduction of feature function is to guide the model to learn some features that we think are helpful for the task . In this way, the calculation of conditional probability is established , It becomes a discriminant model . The simple generative model does not contain characteristic function , Directly study the distribution of the whole data .
-
Maximum Entropy Markov model MEMM
MEMM Compared with HMM The progress of the model is , To study the MaxEnt To calculate the conditional probability . But its limitation is ,MEMM It is based on the calculation of each local node , Merge again . The problem with this is , The conditional probability obtained by the maximum entropy model of each step is only based on the information of two points related to this point , And it is only normalized in this part , Lack of comprehensiveness .
MEMM The progress of is , The method of discriminant is introduced , And based on HMM The properties of are operated locally , It's also very fast .
-
CRF Characteristic function in
CRF More like the crystallization of the above methods .
CRF The indispensable concept in is the characteristic function . At first I saw CRF When , Suddenly two characteristic functions pop up, which makes me confused , Later, I found that they were all models slowly explored through the continuous research and trial and error of predecessors ,respect. The characteristic function is actually artificially defined , For example, in the word segmentation task , I don't want adjectives or verbs after verbs , Then I can make this clear by setting the characteristic function , Give the machine an adjusted direction .
CRF There are two kinds of characteristic functions :
① The state characteristic function on the node :
s l ( y i , x , i ) , i = 1 , 2 , . . . , L s_l(y_i,x,i),i=1,2,...,L sl(yi,x,i),i=1,2,...,LIt shows the characteristics between the observation sequence and the corresponding state on the node .
② Transfer characteristic function between nodes :
t k ( y i − 1 , y i , x , i ) , k = 1 , 2 , . . . , K t_k(y_{i-1},y_i,x,i),k=1,2,...,K tk(yi−1,yi,x,i),k=1,2,...,KBetween nodes ( Here is the previous node and the current node ) The characteristic relationship of .
6、 ... and 、CRF Formula analysis
Enter the formula link , Before that , We should first add some knowledge that is convenient to understand :
-
Probability undirected graph
actually , If the joint probability distribution satisfies the pairing , Local or global markov , This joint probability distribution is called the probability undirected graph model . This definition is similar to the above definition of Markov field . in other words , Markov field can be regarded as a probability undirected graph , Points are random variables , Edges are relationships between variables . The conditional random field can be regarded as a special Markov random field , Therefore, it can be represented by probability undirected graph .
In probability undirected graph , There is also a very important concept , It's called the largest group .

Thank you for this article , This set of pictures is very clear . It's very simple , A group of nodes in a maximal clique that are fully connected , Another node will break the condition of this full connection . The maximal clique is the maximal clique with the largest number of nodes in the maximal clique .
Then why do we need the largest regiment ? Because according to a very mathematical theorem (Hammersley-Clifford Theorem ), Joint probability distribution of probability undirected graph model P(Y) Can be obtained from the largest group :
P ( Y ) = 1 Z ∑ Y ψ c ( Y c ) P(Y) = \frac{1}{Z}\sum_{Y}\psi_c(Y_c) P(Y)=Z1Y∑ψc(Yc)
Z = ∑ Y ∏ c ψ c ( Y c ) Z = \sum_Y \prod_c\psi_c(Y_c) Z=Y∑c∏ψc(Yc)
ψ c ( Y c ) = e − E ( Y c ) \psi_c(Y_c) = e^{-E(Y_c)} ψc(Yc)=e−E(Yc)
E ( x c ) = ∑ u , v ∈ C , u ≠ v α u , v t u , v ( u , v ) + ∑ v ∈ C β v s v ( v ) E(x_c) = \sum_{u,v\in C,u \neq v}\alpha_{u,v}t_{u,v}(u,v) + \sum_{v \in C}\beta_v s_v(v) E(xc)=u,v∈C,u=v∑αu,vtu,v(u,v)+v∈C∑βvsv(v)
In the first formula c, Is the largest clique of an undirected graph . Y c {Y_c} Yc Represents the random variable on the node , ψ c {\psi_c} ψc Is a strictly positive function ,Z It's the normalization factor .
The second formula is the calculation formula of normalization factor . Same as the first formula , It just increases the multiplication of all the largest regiments .
The third and fourth formulas are right ψ {\psi} ψ function , Or say , Further explanation of potential function . But actually , There is no regulation ψ {\psi} ψ The function must be like this .
Because the definition here is related to the Boltzmann distribution in Physics , So we usually set the potential function like this . there α {\alpha} α And β {\beta} β Are all parameters. ,t() And s() It's a characteristic function .
And one more detail , The characteristic function here t() It's about the relationship between two nodes in the maximal clique , and s() It's about nodes alone . This is related to CRF The definition of characteristic function in is very similar .It doesn't matter if the formula is not very clear , Whether the reader finds , The fourth formula looks very familiar ? Let's continue to observe CRF Formula .
-
CRF The formula
For the sake of illustration , Take linear conditional random field as an example .
CRF The parametric definition of is like this :
P ( y ∣ x ) = 1 Z ( x ) e x p ( ∑ i , k λ k t k ( y i − 1 , y i , x , i ) + ∑ i , l μ l s l ( y i , x , i ) ) P(y|x) = \frac{1}{Z(x)}exp(\sum_{i,k}\lambda_kt_k(y_{i-1},y_i,x,i) + \sum_{i,l}\mu_ls_l(y_i,x,i)) P(y∣x)=Z(x)1exp(i,k∑λktk(yi−1,yi,x,i)+i,l∑μlsl(yi,x,i))Z ( x ) = ∑ y e x p ( ∑ i , k λ k t k ( y i − 1 , y i , x , i ) + ∑ i , l μ l s l ( y i , x , i ) ) Z(x) = \sum_y exp(\sum_{i,k}\lambda_kt_k(y_{i-1},y_i,x,i) + \sum_{i,l}\mu_ls_l(y_i,x,i)) Z(x)=y∑exp(i,k∑λktk(yi−1,yi,x,i)+i,l∑μlsl(yi,x,i))
Is it familiar ? In fact, it is to integrate the formulas in the probability undirected graph !λ and μ They're all learnable parameters , The characteristic function is also the same as what we defined earlier . Actually ,MEMM The formula for calculating the maximum entropy is also very similar to this result , Because the definition and design of information entropy itself have some similarities with the potential function here . But it's connected to CRF The main difference is , The calculation of normalization factor is different .MEMM The calculated normalization factor is obtained by multiplying the normalization factors on each node ( Personal observation , Not necessarily right );CRF Directly calculate the global normalization factor , Therefore, the overall situation is stronger .
See here , Is it possible to understand CRF Where did the formula come from ?
For the convenience of expression , Generally, the formula will be simplified as follows :
P ( y ∣ x ) = 1 Z ( x ) e x p ( ∑ k ω k f k ( y , x ) ) P(y|x) = \frac{1}{Z(x)}exp(\sum_{k}\omega_kf_k(y,x)) P(y∣x)=Z(x)1exp(k∑ωkfk(y,x))
Z ( x ) = ∑ Y e x p ( ∑ k ω k f k ( y , x ) ) Z(x) = \sum_Y exp(\sum_{k}\omega_kf_k(y,x)) Z(x)=Y∑exp(k∑ωkfk(y,x))
use ω Instead of representing two parameters , use f() Instead of representing two characteristic functions . After using this formula , In fact, we can find CRF Some of the working principles of . The more characteristic functions are satisfied , The greater the corresponding conditional probability value ( Will not ω Think about it , take ω If you consider it, you should add a premise : In the case of features we want to learn .)
thus , You can use some algorithms ( gradient descent 、L-BFGS wait ) To study , Got the parameters .
7、 ... and 、 summary
Personally think that ,CRF The core point is to introduce globality . The above example is about Linear-CRF The situation of , actually ,CRF It can be much more complicated , All this is determined by your characteristic function .CRF This design method makes it possible to mine more constraints and information between tags , But the disadvantages are obvious , It's just that the training speed will be slow .
Last , Thanks to brother Junyi and KNLP The rest of the group !!
A premise : In the case of features we want to learn .)
thus , You can use some algorithms ( gradient descent 、L-BFGS wait ) To study , Got the parameters .
7、 ... and 、 summary
Personally think that ,CRF The core point is to introduce globality . The above example is about Linear-CRF The situation of , actually ,CRF It can be much more complicated , All this is determined by your characteristic function .CRF This design method makes it possible to mine more constraints and information between tags , But the disadvantages are obvious , It's just that the training speed will be slow .
Last , thank Junyi Brother and his friends !!
( The original text is on my personal blog :CRF A preliminary study of the principle )
版权声明
本文为[Apple Laboratory of Central South University]所创,转载请带上原文链接,感谢
https://yzsam.com/2022/04/202204230626397689.html
边栏推荐
- IT高薪者所具备的人格魅力
- Unable to process jar entry [module info. Class]
- 常用Markdown语法学习
- Towords Open World Object Detection
- Double sided shader
- Use of command line parameter passing library argparse
- 庄懂的TA笔记(零)<铺垫与学习方法>
- Mongodb 启动警告信息处理
- SampleCameraFilter
- Online Safe Trajectory Generation For Quadrotors Using Fast Marching Method and Bernstein Basis Poly
猜你喜欢

Houdini>建筑道路可变,学习过程笔记

使用flask时代码无报错自动结束,无法保持连接,访问不了url。

MySQL8.0 安装/卸载 教程【Window10版】

Window10版MySQL设置远程访问权限后不起效果

Understanding the role of individual units in a deep neural networks

SVG中Path Data数据简化及文件夹所有文件批量导出为图片

命令行参数传递库argparse的使用

Page dynamic display time (upgraded version)

About USB flash drive data prompt raw, need to format, data recovery notes

Towords Open World Object Detection
随机推荐
Weblux file upload and download
Index locked data cannot be written to es problem handling
SVG中年月日相关的表达式
Unity screen adaptation
Solve the problem of deploying mysql8 in docker with correct password but unable to log in to MySQL
05 use of array
C# 多个矩形围成的多边形标注位置的问题
TimelineWindow
Understanding the role of individual units in a deep neural networks
About USB flash drive data prompt raw, need to format, data recovery notes
SQL user-defined scalar value function that looks up relevant column values n times forward or backward according to a specified table name, column name and column value
Simple random roll call lottery (written under JS)
Teach-Repeat-Replan: A Complete and Robust System for Aggressive Flight in Complex Environments
踩坑日记:Unable to process Jar entry [module-info.class]
大学学习路线规划建议贴
Unityshader Foundation
Nodejs (II) read files synchronously and asynchronously
Robust and Efficient Quadrotor Trajectory Generation for Fast Autonomous Flight
electron-builder打包报错:proxyconnect tcp: dial tcp :0: connectex
IDEA快捷键