当前位置:网站首页>Practice of spark SQL in snowball
Practice of spark SQL in snowball
2022-04-21 20:11:00 【Snowball engineer team】
author : Snowball big data team
background
Because business requires , The snowball data team is based on HDP 3.1.5(Hadoop 3.1.1+Hive 3.1.0+Tez 0.9.1) Built a new cluster ,HDP 3.1.5 By default Hive3 on Tez As ETL Calculation engine , But in use Hive3 on Tez in , We have a lot of problems :
- part SQL Execution failure , You need to close the container reuse or vectorization implementation .
- part SQL Turn on CBO The optimized execution plan is wrong , Cause the result to go wrong , Need to be closed CBO Optimize .
- Some time zones are not allowed 、GroupBy with Limit Inaccurate, etc. are already in the new version fix Of bug.
- Extremely individual complex multi-level correlation SQL, The calculation result is not accurate , It's hard to find. , It needs to be modified SQL To solve .
These problems are very fatal to warehouse development . From an industry perspective , Most companies still use Hive2, and Hive and Tez The community is less active , Slow update iteration (Hive3.x The latest time release It's almost 3 Years. ), The cost of fixing related problems is relatively high .
In comparison Hive3 on Tez、Hive3 on MR、Hive3 on Spark2 、Spark SQL After all kinds of engines , Comprehensively consider the accuracy, stability and calculation efficiency , The data team decided to adopt Spark SQL As a storehouse ETL engine . After a period of promotion and use , Currently in interactive query and offline ETL Many scenarios and calculations have been supported Spark SQL:

This article mainly shared from Hive3 SQL Switch to Spark3 SQL Practice .
Handover process
Facebook In from Hive Switch to Spark SQL When , Rewrote Spark SQL Implementation plan of , Added one Shadow The process : be based on Hive SQL The execution log of , Execute one Spark SQL, Double write data to Shadow In the table , Then compare the actual table and table through the tool Shadow Execution efficiency and correctness of the table .
The snowball data team also developed similar tools for testing and comparison . The scheduling system developed by the company itself has its own execution time and resource consumption tools ( be based on yarn Of application Resource usage statistics ), Can be used to compare execution efficiency . At the same time, a software based on Trino The accuracy comparison tool is used to compare the accuracy .
The test is divided into two stages :
- For complex scenes SQL, Mainly made a comparison of the accuracy :Hive3 on Tez The correct rate of is about 50%,Hive3 on MR The correct rate of is about 70%,Hive3 on Spark2 The accuracy of is 100%( Need to be closed CBO),Spark SQL The accuracy of is 100%.

- On the actual operation on the line SQL, By collecting and replaying a large number of online actual SQL, Write different target tables with different engines , Then compare the execution efficiency with the execution efficiency . In terms of execution time ,Spark SQL Execution time and Hive3 on Tez On a data scale , but Spark SQL Resource consumption is about Hive3 on Tez( Limits the degree of parallelism ) Of 1/3. and Hive3 on Spark2 Data skew often occurs .Spark SQL The best performance of .

After carefully evaluating the accuracy and execution efficiency , The big data team decided to use it first Hive3 on Spark2 As an emergency replacement Tez The computing engine of , Then choose Spark 3.2.1 As a long-term supported computing engine , Step by step Hive SQL Switch to Spark SQL.
Have a problem
Thanks to the Spark3 Performance improvement and AQE Mechanism , Performance problems are rarely encountered . however , Switch between data and snowball during team testing , Some problems , Most of them are compatibility issues , Let's introduce one by one :
1.Spark SQL Can't recurse subdirectories and can't read and write their own problems
When Hive When table data is stored in multi-level subdirectories ,Tez、MR、Spark Data cannot be recognized and read by default . In this case ,Apache Hive Two parameters are provided :
set hive.mapred.supports.subdirectories=true;
set mapreduce.input.fileinputformat.input.dir.recursive=true;
Copy code but Spark SQL Similar parameters are not supported .Spark SQL In execution ORC and Parquet When parsing a file in format , By default Spark Built in parser (Spark The built-in parser is more efficient ), These built-in parsers do not support two parameters of recursive subdirectories , And there are no other parameters to support this effect . Can be set by spark.sql.hive.convertMetastoreOrc=false To specify the Spark Use Hive The parser , Make the recursive subdirectory parameters take effect correctly .Spark The built-in parser will also support recursive subdirectories in future versions .
Besides , When the user is using Spark Read and write the same Hive Table time , Come across "Cannot overwrite a path that is also being read from " The error of , And the same statement is in Hive It can be done in . This is because Spark The common data types of log warehouse have made their own implementation , In his own way , The target path will be cleared first , Then write , and Hive Write to the temporary directory first , After the task is completed, we will talk about the result data and replace the target path . Use Hive The parser can also solve this problem .
2.Hive ORC Some problems of analysis
stay 1 The solution to the problem , We choose to use Hive Of ORC Parser , This will lead to the following problems :
Hive Of ORC Reading some Hive Table time , An array out of bounds exception or null pointer exception will occur .
The reason is that there are empty directories under some directories ORC file , By setting hive.exec.orc.split.strategy=BI Avoid null pointer problem ,
Set up hive.vectorized.execution.enabled=false Avoid array out of bounds . In addition, use Spark 3.x when , You also need to set hive.metastore.dml.events=false Avoid errors when writing data .
3.Spark.sql.sources.schema problem
stay Spark and Hive In case of simultaneous use , Some actions may cause Hive Table metadata contains spark.sql.sources.schema.part The existence of attributes , Subsequent modification of the table structure will lead to inconsistency between the table metadata and data . for example : New fields A And execute a new write statement , Inquire about A The field values for NULL.
This is because Spark This attribute exists when reading and writing Hive Table time , The mapping value provided by this attribute will be preferentially used to generate the table structure . and Hive Statements that modify the table structure natively do not update the value , Eventually, the new field will not be read or written Spark distinguish .
The solution is to rebuild the table , Or delete the table attribute . When both engines exist at the same time , It can be agreed that only Hive To execute DDL data .
4.Spark Authority and audit
stay Hive Inside , We inherited PasswdAuthenticationProvider It realizes user-defined user authentication , Through integration Ranger Realize authority control , and Spark The open source version does not have a complete solution . Official Spark Thrift Server There are great deficiencies in resource isolation and authority control , We introduced Apache Kyuubi.Kyuubi There are similar PasswdAuthenticationProvider The interface of , Can be used to realize user authentication . For authority control , The general scheme is to use Submarine. however Submarine The first mock exam has removed this module. , And the latest one supports Ranger Of 0.6.0 Version support only Spark 3.0.Spark Integrate Ranger You need to parse first SQL Get the relevant tables and fields , To determine whether the current user has permission to read and write , and Spark 3.0 To Spark 3.2.1 Parsing SQL Made a lot of changes , So we modified the relevant code to adapt Spark 3.2.1. At the same time, it is based on Apache Kyuubi Of Event system , It's done Spark Audit function of .

5.Hive SQL transfer Spark SQL Some of the more hidden pits
- Date type comparison , Different ways of handling
Low version Hive Will Date Type conversion to string,2.3.5 Future versions will String Convert to Date Compare .
Such as : '2022-03-14 11:11:11' > date_sub('2022-03-15',1)
In lower versions , The result of this inequality is true, For higher versions false. stay Spark SQL 3.2.1 in , The result is also false.
- Different types of strictness
Hive Implicit conversion is supported by default ,Spark Need to set up spark.sql.storeAssignmentPolicy=LEGACY To support finite degree implicit conversion , Otherwise, the execution will report an error .
-
It requires higher semantic accuracy , for example
-
Relevance syntax is different :
select a from t1 join t2 group by t1.a
stay Spark SQL It needs to be written as select t1.a from t1 join t2 group by t1.a
- grouping The grammar is different :
Select a,b from t1 group by a,b grouping sets (a,b)
stay Hive In addition to aggregation summary a and b Out of dimension , It also summarizes the overall dimensions , But in SparkSQL It is required to be written as
Select a,b from t1 group by a,b grouping sets ((),(a),(b))
6. Dynamic resources , Multiple versions are compatible
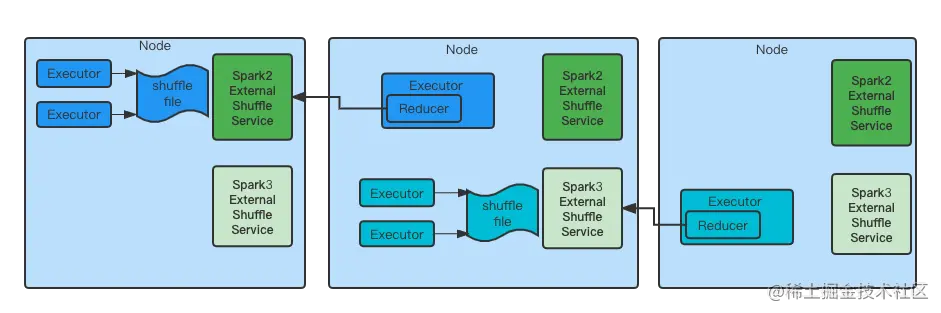
Spark Dynamic resources can save a lot of resources , But rely on shuffle service. Because the cluster needs to support Spark2(Hive on Spark2) and Spark3, Therefore, it is necessary to ensure that the cluster can support two versions of shuffle service.YARN stay 2.9.0 And then supported Classloader Segregated aux service. and Spark 3.1 A configurable way is introduced to start different ports classpath Bag shuffle service. But in practice ,Yarn This mechanism does not load xml The configuration file , Need to put xml become involved jar Package to identify .
7. Small file problem
In order to improve the calculation speed , The big data computing engine will adopt parallel processing in computing , and Spark SQL When writing data, it is written in parallel , There is no consolidation process . Too many small files , Will increase Namenode The pressure of the , At the same time, it also has a great impact on query performance . Usually in Hive Can be introduced in hive.spark.mergefiles=true for hive Add a merger to the implementation plan of Job, but Spark SQL This approach is not supported .
at present , We turn on AQE, By setting the target size and maximum shuffle The upper limit reduces the number of files finally generated to some extent . for example :
--conf spark.sql.adaptive.enabled=true \
--conf spark.sql.adaptive.advisoryPartitionSizeInBytes=262144000 \
--conf spark.sql.adaptive.maxNumPostShufflePartitions=200 \
--conf spark.sql.adaptive.forceApply=true \
--conf spark.sql.adaptive.coalescePartitions.parallelismFirst=false \
--conf spark.sql.adaptive.coalescePartitions.minPartitionSize =1 \
Copy code Be careful :advisoryPartitionSizeInBytes This parameter does not specify the final generated file size , But in the final output file stage , Every partition read Byte size of , Here 256M Corresponding to ORC Snappy The output file size of is about 55M.
By experiment , The maximum number of files generated is 200 individual , Size average 55M. The total size is less than 50M when , There will only be one file .
The future planning
Now every day 300+ The task is based on Spark SQL, It has been running stably for a long time , The problems encountered before have been basically solved , All the... Will be later ETL The engine is unified to Spark SQL, To improve computational efficiency . Use Spark SQL The main scene is still offline in the warehouse ETL, Later, we will try to introduce it in more scenarios Spark SQL, For example, interactive analysis , Will be combined with the company's current Trino The engine does something complementary . in addition , At present, there are many real-time data requirements in business , It will be based on Spark Technology stack introduction Hudi And other data Lake technologies to meet business needs .
版权声明
本文为[Snowball engineer team]所创,转载请带上原文链接,感谢
https:https://yzsam.com/html/QUGzWt.html
边栏推荐
- R language data analysis from entry to advanced: (8) data format conversion of data cleaning skills (including the conversion between wide data and long data)
- Unity Socket
- How to restore the deleted photos? Four schemes, which is the official guide
- Status code encapsulation -- reprint
- Publicity of the winners of the 9th "Datang Cup" National College Students' mobile communication 5g technology competition
- Redis can send verification codes and limit the number of times sent every day
- JUC queue interface and its implementation class
- Surface point cloud normal
- vim 从嫌弃到依赖(6)——插入模式
- C# 双保险进程监视器 lol 保证被监视的程序'几乎'永远运行. 关键字:进程操作 进程查看 创建进程
猜你喜欢

Solution to flash back after MySQL enters password

联想公布ESG新进展:承诺2025年全线计算机产品100%含有再生塑料

Discussion on the hot and cold issues of open source license grounding gas

艾尔登法环“无法加载保存数据”解决方法

Dolphin DB vscode plug-in tutorial
![[timing] lstnet: a time series prediction model combining CNN, RNN and ar](/img/b7/5b4fb5fc36f72aabfb04eafb941b57.png)
[timing] lstnet: a time series prediction model combining CNN, RNN and ar

R language data analysis from entry to advanced: (8) data format conversion of data cleaning skills (including the conversion between wide data and long data)

Introduction to applet project files

getchar,putchar,EOF

MySQL error 2005
随机推荐
Interesting souls are the same. It takes only 2 steps to slide the computer off
长安深蓝C385产品信息曝光 瞄准20万级别,头号目标Model 3!
在IE和Edge中用JS判断只能输入数字,字母,日期型。
Introduction to webrtc: 3 Use enumeratedevices to get the streaming media available in the device
The difference between English and American pronunciation [turn]
esayCode模板
第九届”大唐杯“全国大学生移动通信5G技术大赛省赛获奖名单公示
First acquaintance with EEMBC coremark
如何让网卡后门搞死一个系统,让你知道网卡是个多么厉害的角色
牛客BM40. 重建二叉树
The timer class of version C is accurate to microseconds and retains one decimal place after seconds. It supports the output of year, month, day, hour, minute and second with units
My medical experience of "traditional Chinese medicine"
Comprehensive solution for digital construction of double prevention mechanism in hazardous chemical enterprises
STL container (I) -- vector
Multi factor strategy
redis
[2021] number of effective sequences programmed by Tencent autumn recruitment technology post
Notes on checkpoint mechanism in flick
Use of complex function in MATLAB
Use of register keyword